![10 Best IPFingerprint Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a69baada44932cddf63ae4b_10%20Best%20IPFingerprint%20Alternatives%20%26%20Competitors.png)
10 Best IPFingerprint Alternatives & Competitors [2026]

Below, I've lined up 10 IPFingerprint alternatives for 2026 and matched each to the kind of team it fits, from person-level identification tools to enterprise intent platforms.
TL;DR
- Warmly offers the best alternative to IPFingerprint in 2026 for mid-market B2B SaaS revenue teams, since it identifies visitors down to the individual and then works both the inbound conversion and the outbound follow-up from one system.
- If you mainly want low-cost company-level identification with pricing you can read straight off the website, the tools to compare are Leadfeeder, Snitcher, Albacross, and Leadinfo, all of which do the core job well at a fraction of enterprise pricing.
- Enterprise buyers who need predictive scoring or deep third-party intent tend to look at 6sense and ZoomInfo, while RB2B covers US teams that just want person-level leads dropped into Slack.
What are the best alternatives to IPFingerprint?
The best alternatives to IPFingerprint in 2026 are Warmly, Leadfeeder, and Lead Forensics.
The table lines up all 10, what each fits best and roughly what it costs:
#1: Warmly
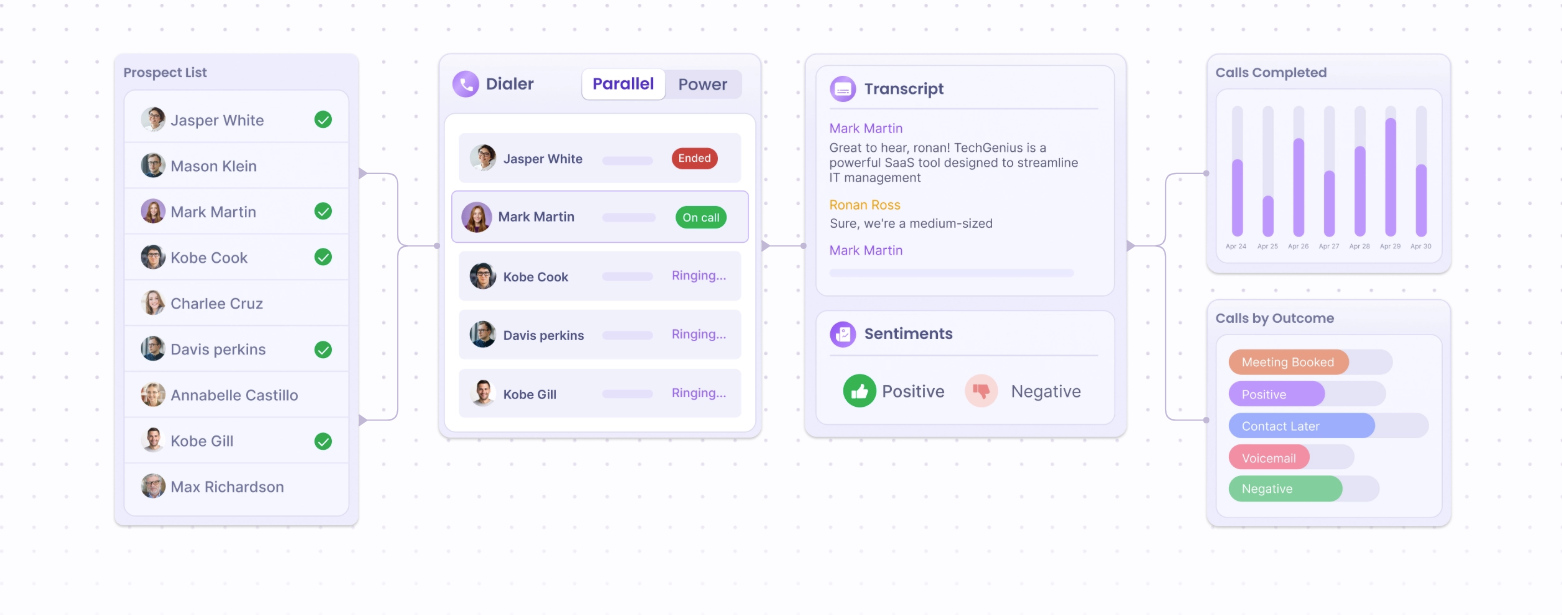
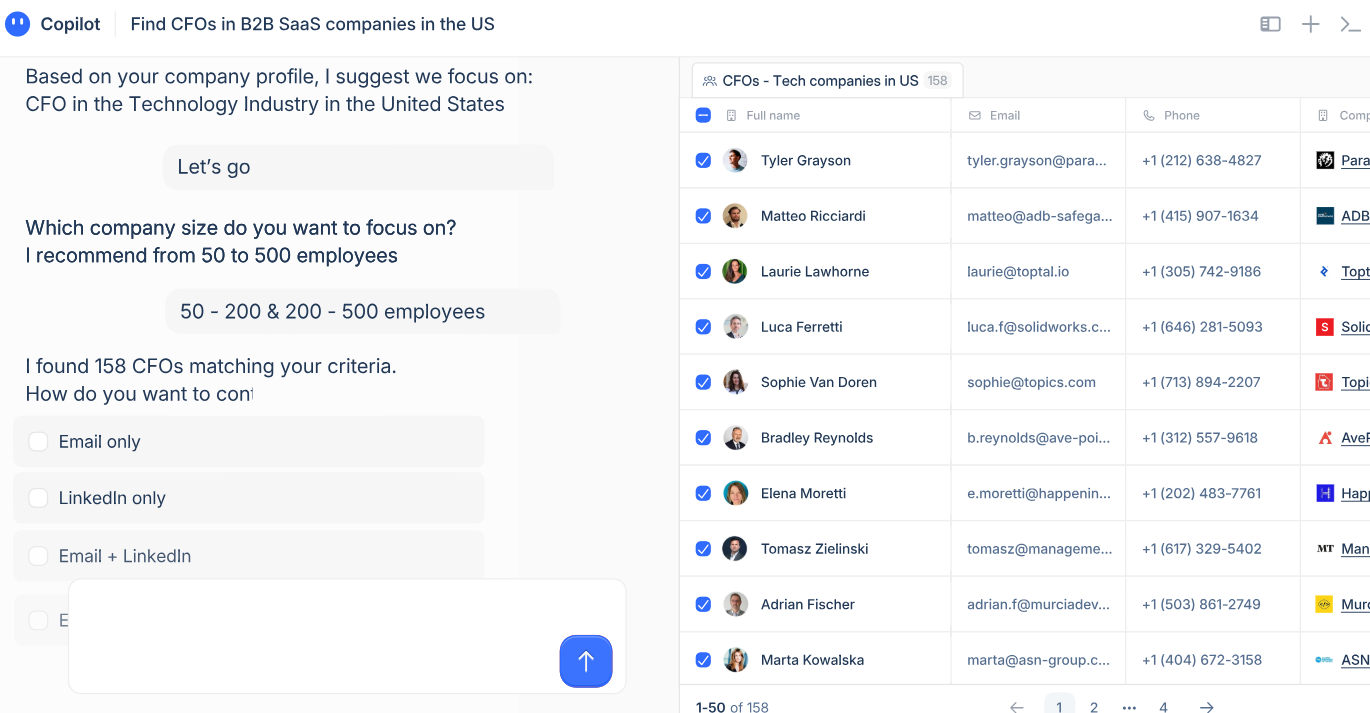
Warmly is the best alternative to IPFingerprint in 2026 for mid-market B2B SaaS revenue teams that want to do more than watch which companies show up.
Our platform names the individual behind a visit, then hands you the tools to reach that person while their intent is still fresh.
Full disclosure: Warmly is our product, so this is the section with the most bias. I'll flag where it genuinely fits teams leaving IPFingerprint, and where something else on this list will serve you better.
Here are the features that make Warmly the alternative to IPFingerprint I'd point a B2B GTM team toward:
Person and company-level website visitor identification
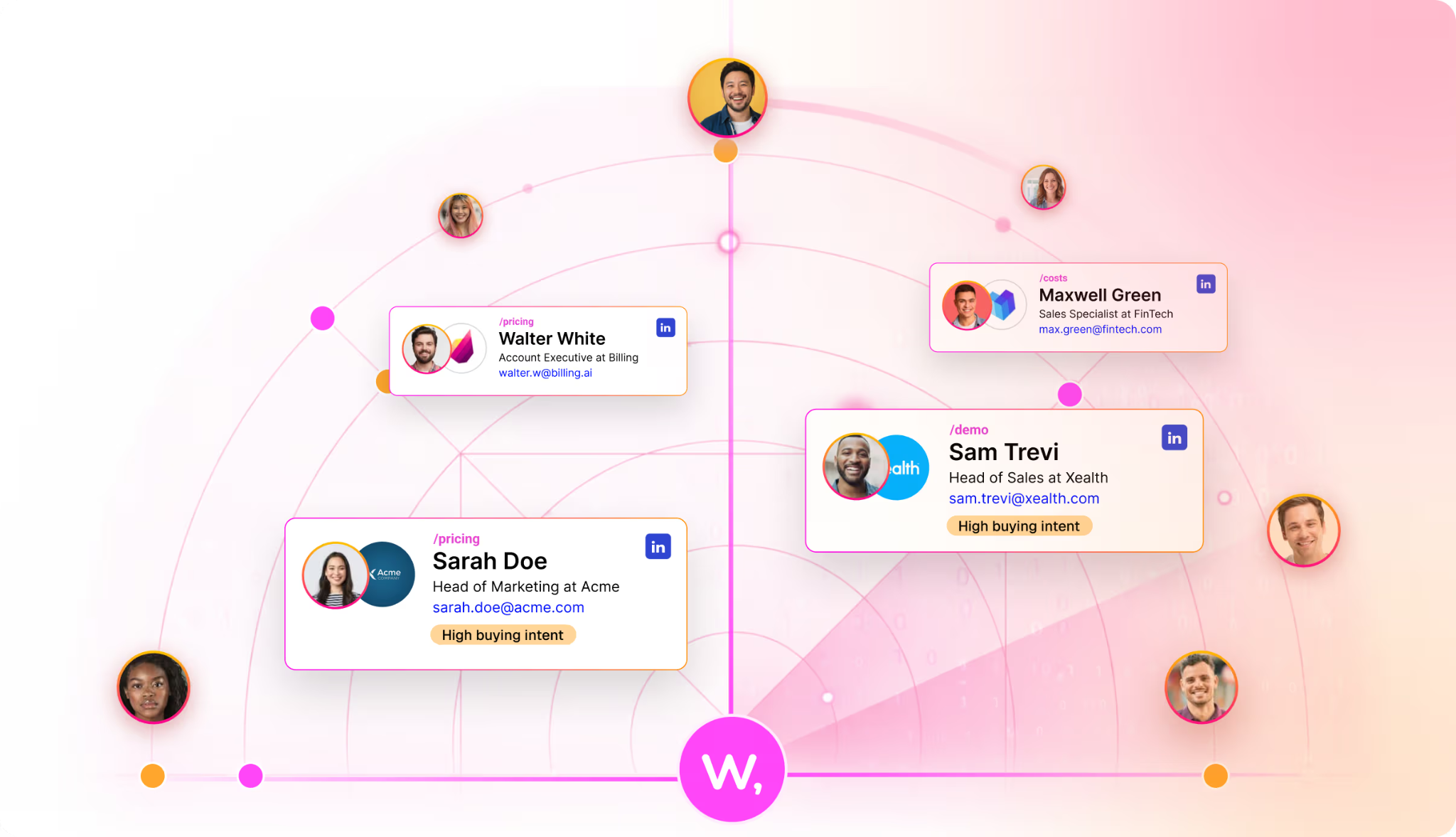
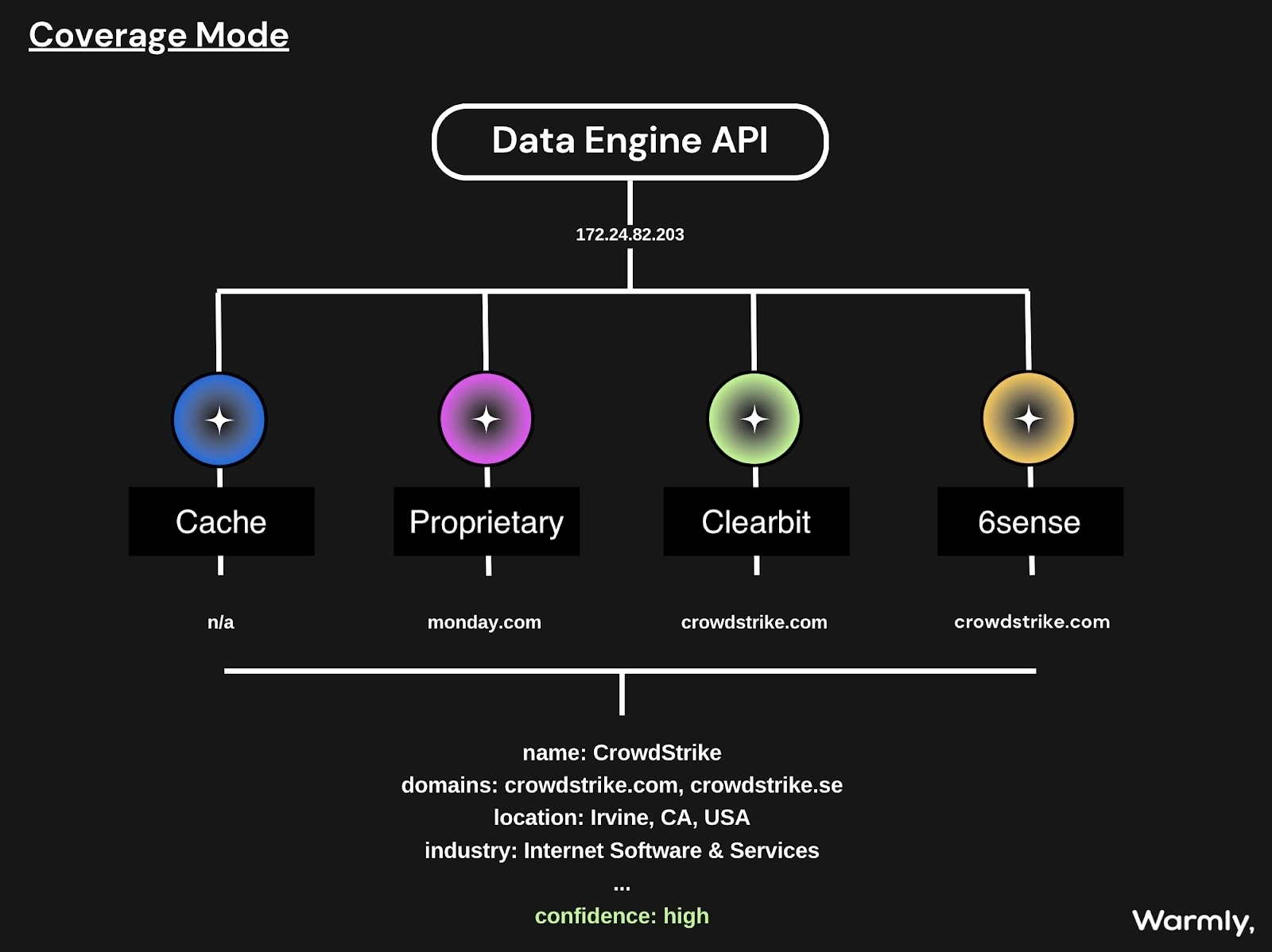
Warmly de-anonymizes visitors at both the company and the individual level, and its coverage is global.
That’s roughly 65% of companies and around 15% of individuals on ordinary B2B traffic.
Under the hood, matching combines deterministic signals (email, cookie, CRM ID) with probabilistic ones (IP, behavioral patterns, LinkedIn data).
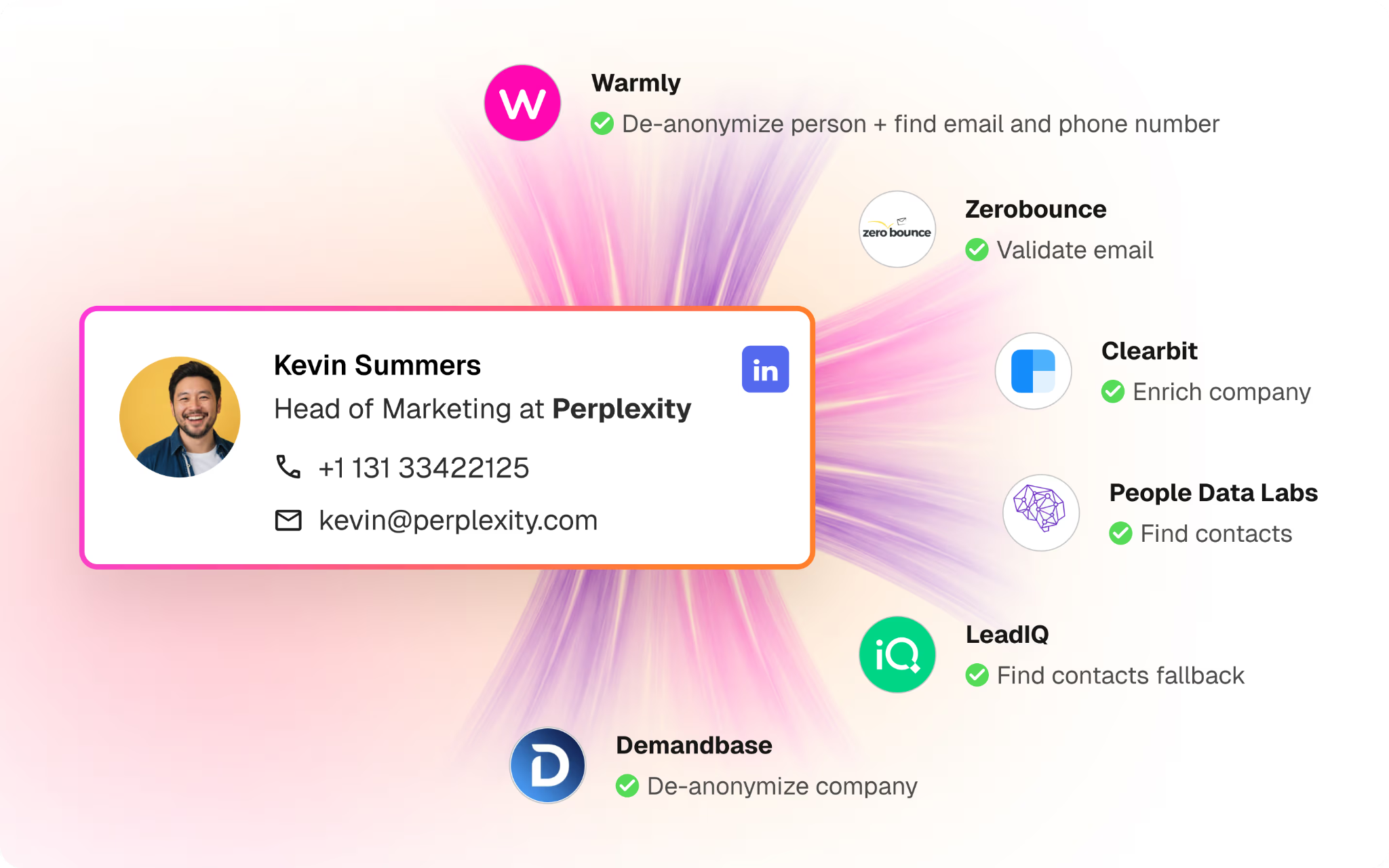
Person-level matches surface enriched: name, title, company, and LinkedIn profile.
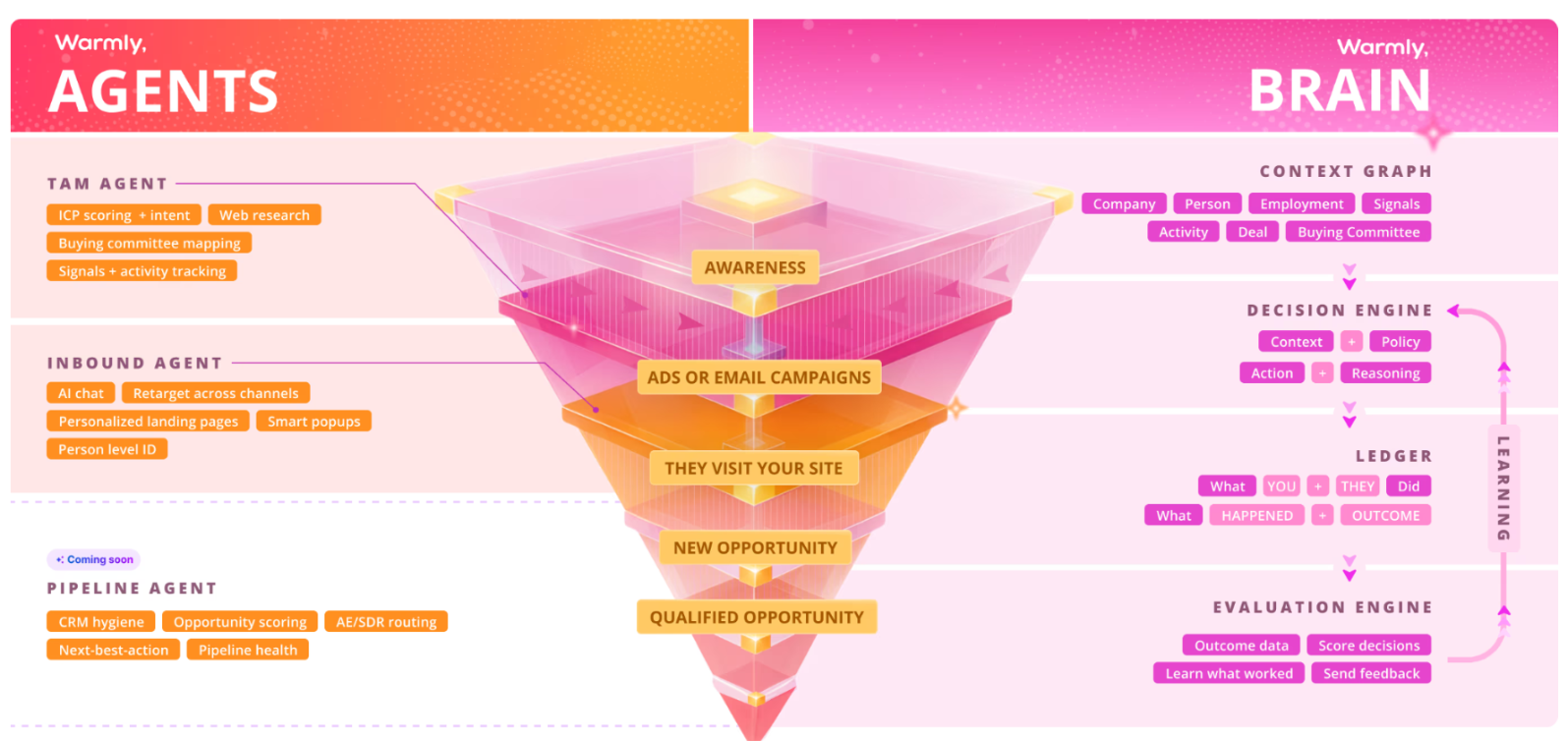
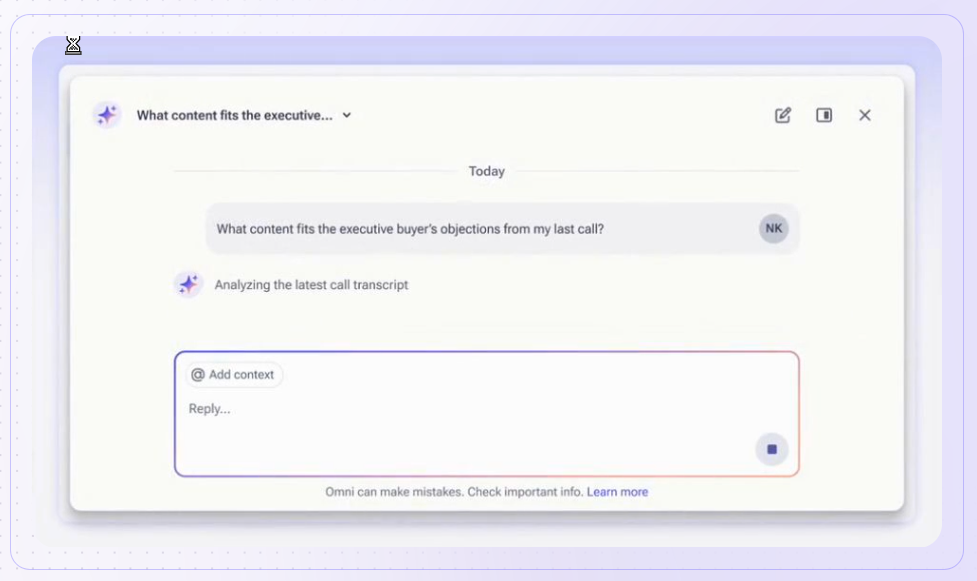
The Inbound Agent: AI chat and Warm Calls
The Inbound Agent greets identified visitors with AI chat that already knows their CRM and intent history before the first message.
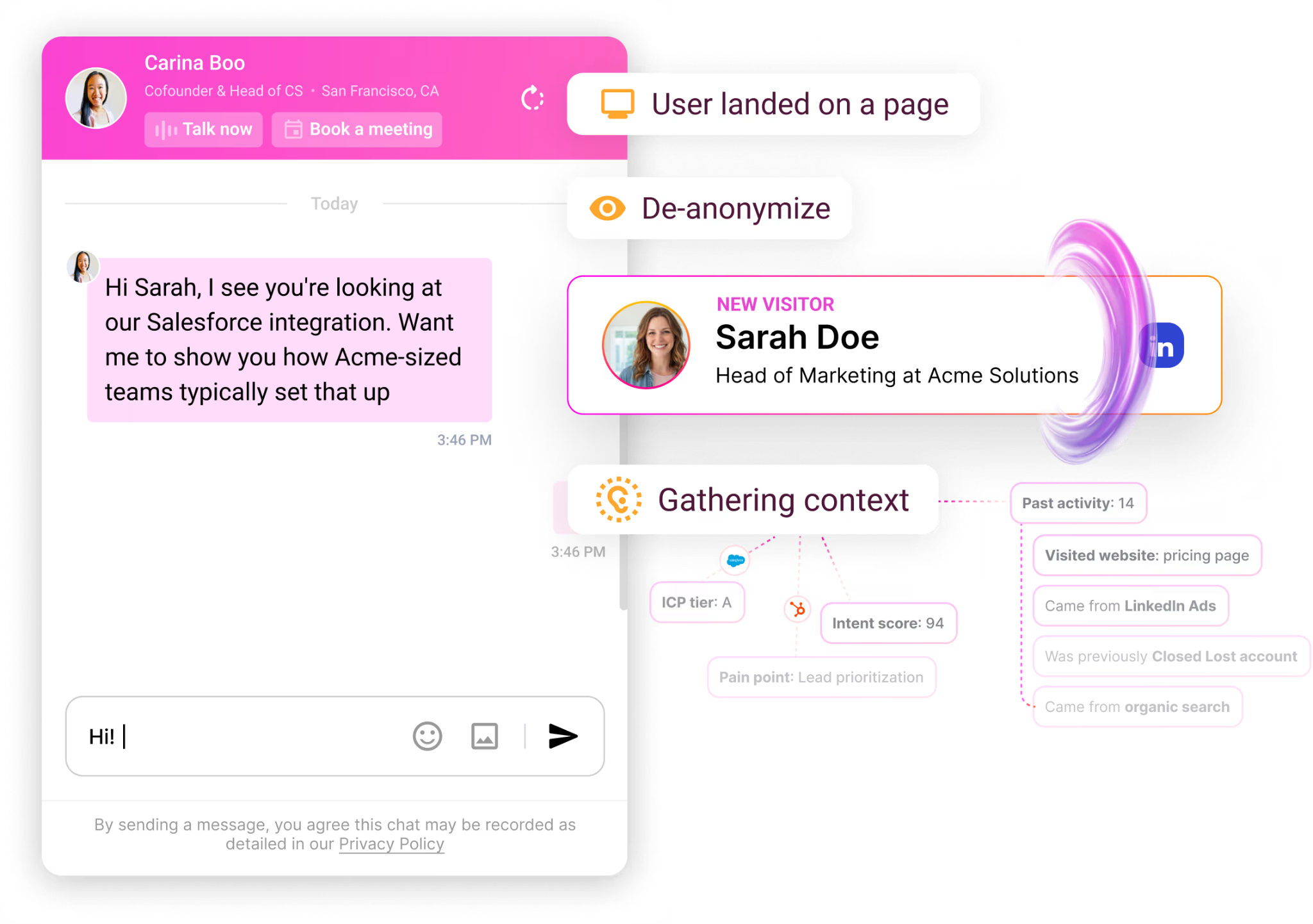
When a human sales rep should step in, they can take over the same thread with the full history intact, so the prospect never repeats themselves.
Nothing hides behind a form.
A prospect books time on the right rep's calendar without leaving the chat, and a live video agent can carry the qualifying conversation when the team is offline.
Apart from this, you can also set up smart popups and personalized microsites that adapt to the visitor's company, role, and behavior.
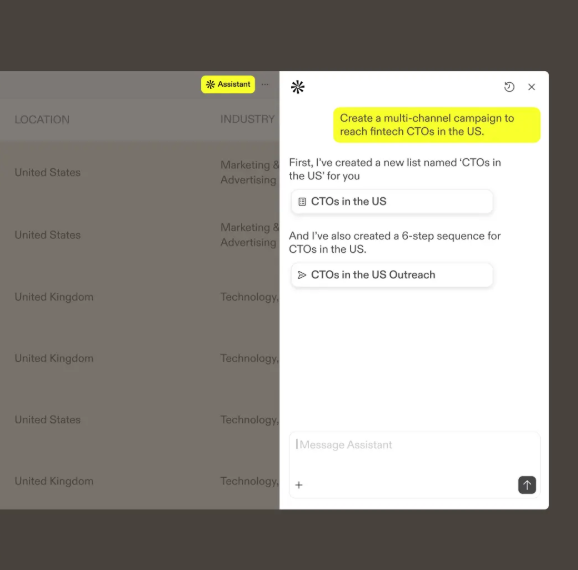
The TAM Agent: outbound orchestration
The TAM Agent builds target audiences from your ICP and refreshes them daily as intent shifts.
Our platform maps the buying committee behind an account and enriches each contact with verified email and LinkedIn data.
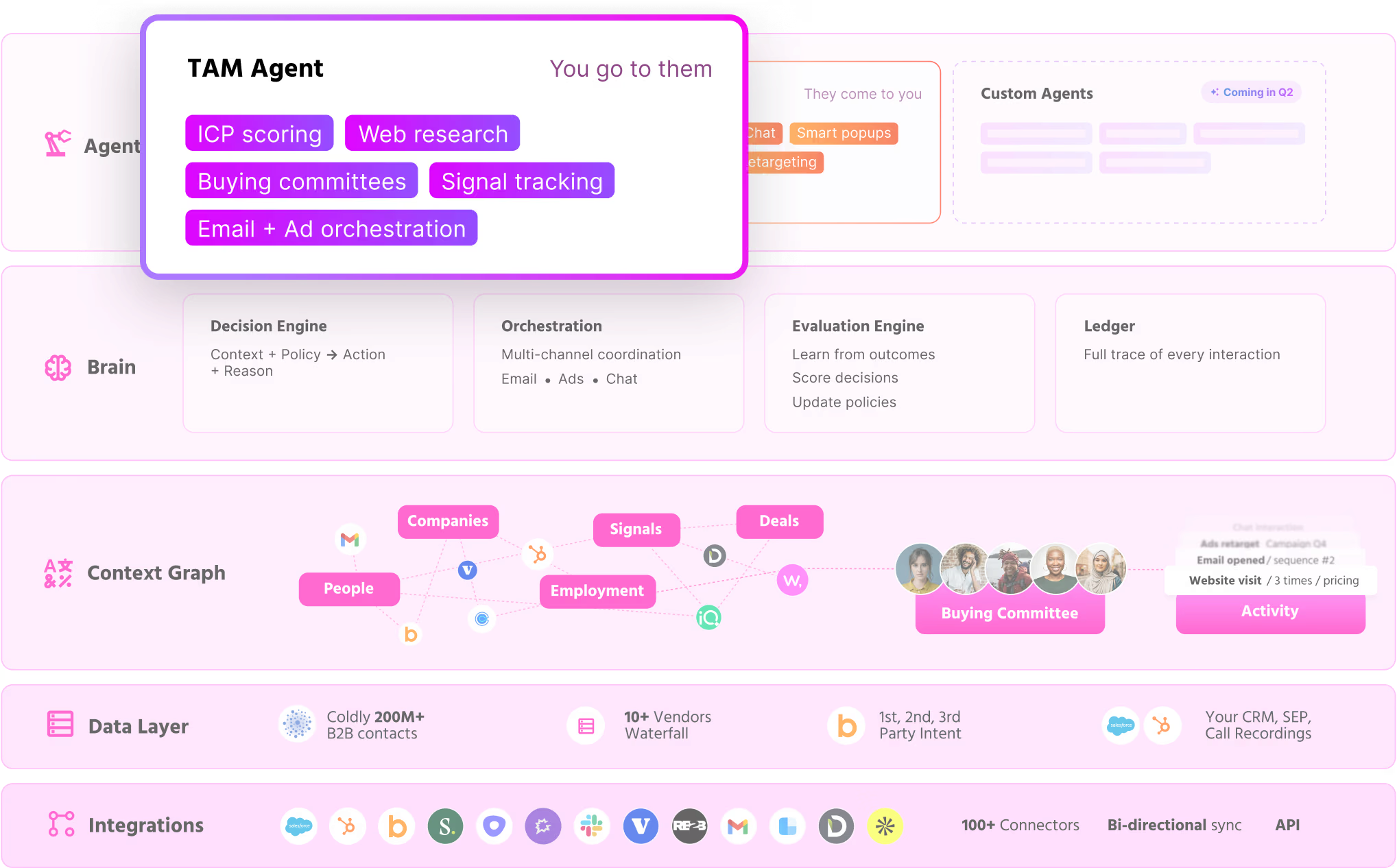
A few things carry most of the weight there:
- Committee mapping: Our agent fills in the Champion, Decision-maker, Influencer, and Approver around the buyer, reading org structure and LinkedIn to go past a simple title match.
- ICP tiering: The model learns from your own closed-won deals, labels each account Tier 1 through Not ICP, and shows the reasoning, so a rep sees why an account got flagged before working it.
- Outbound modes: You can run it through your reps, an autonomous AI SDR, or a split of the two, with rules that keep it off open deals and off anyone already talking to the chatbot.
The Context Graph
The Context Graph is the shared data layer both agents read from, so inbound conversion and outbound follow-up score intent the same way.
It tracks what happened to an account, what you did about it, and what resulted, all in one record.
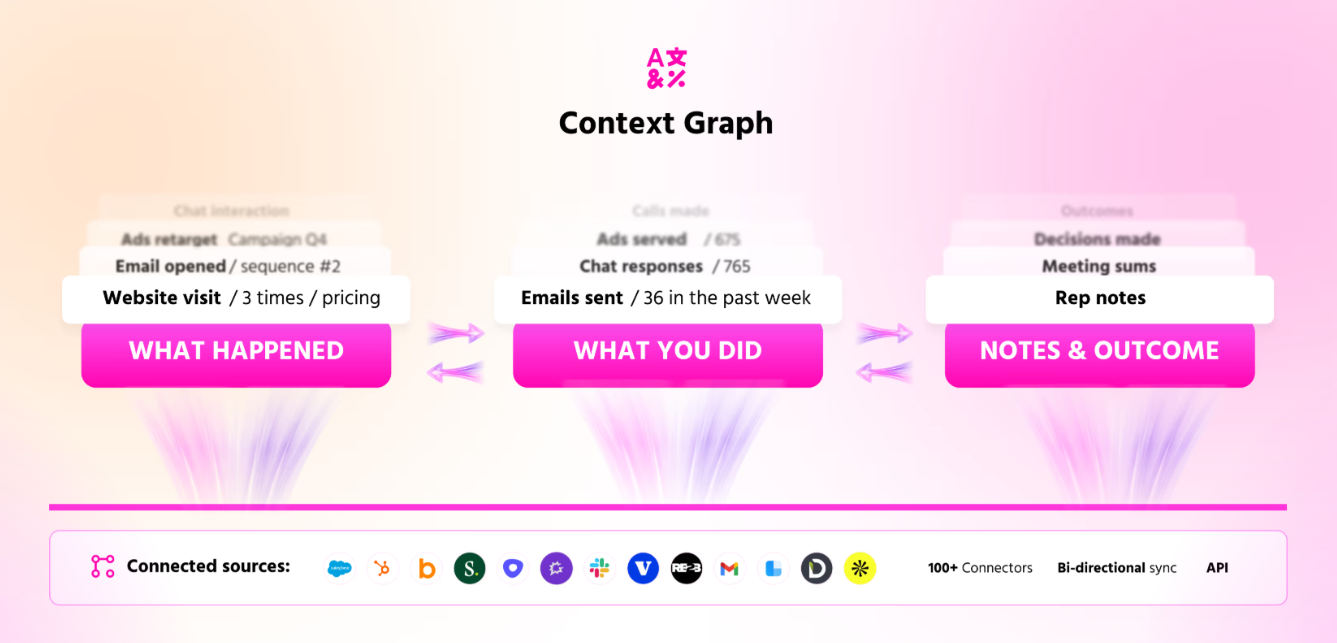
Both agents read from that record, which is how the chatbot can bring up the ROI guide someone downloaded in the spring and the minutes they just spent weighing your plans, with no integration wired in to carry the fact across.
How is Warmly different from IPFingerprint?
IPFingerprint answers one question cleanly: which businesses visited your site and what they looked at, right down to the Google Ads phrase that brought them.
That's reporting and alerting. Turning a flagged company into a real conversation is left to you and whatever other tools you're running.
Warmly starts a layer deeper and keeps going.
Our platform identifies the person behind the visit, then acts on that with chat, live video, popups, and outbound sequences.
The same intent data powers both the on-site conversion and the off-site follow-up.
There's also the Google Ads angle.
IPFingerprint leans hard into search-phrase tracking and paid-search ROI, which is useful if Google Ads is your main channel.
Warmly covers the whole funnel, so if your motion involves more than paid search, the picture is wider.
One honest caveat: IPFingerprint is a UK-based tool, and its company-level matching plus Google Ads reporting can be enough on their own for a smaller team that just needs to know which firms are browsing.
Warmly is a heavier platform built for teams ready to act on visits at scale.
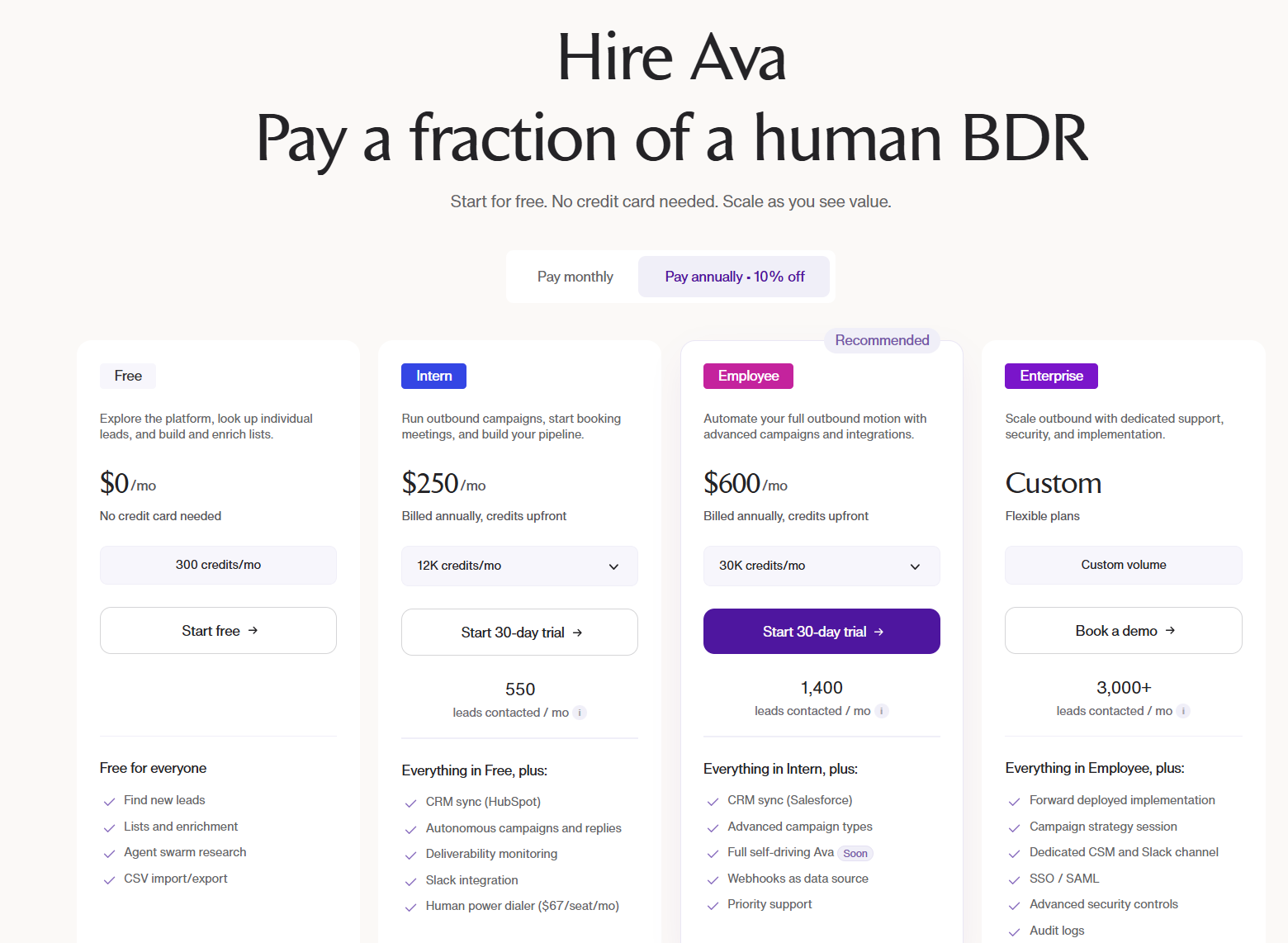
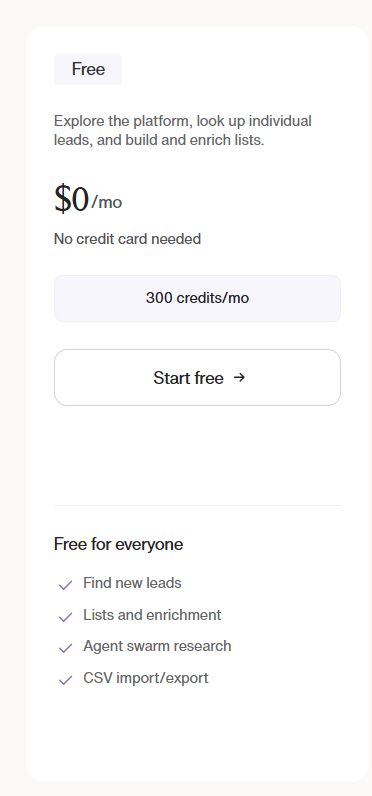
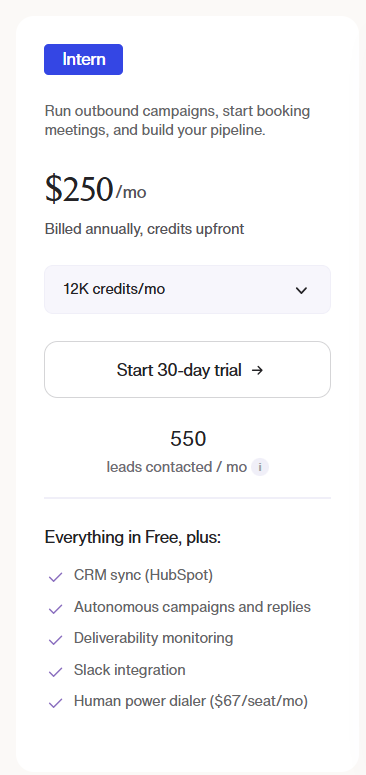
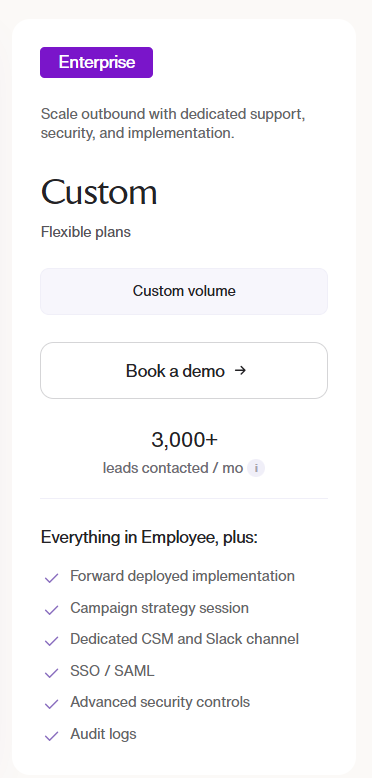
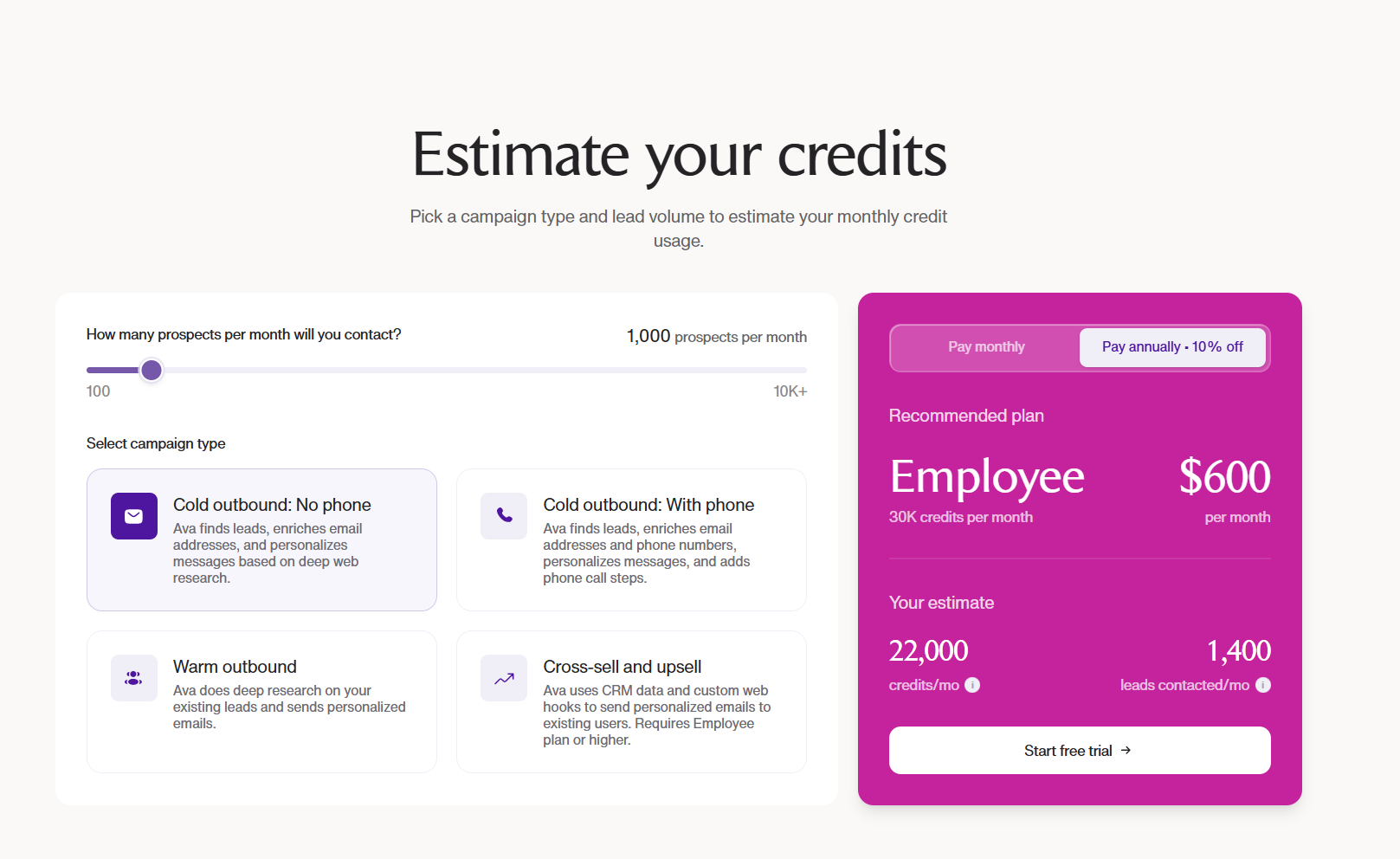
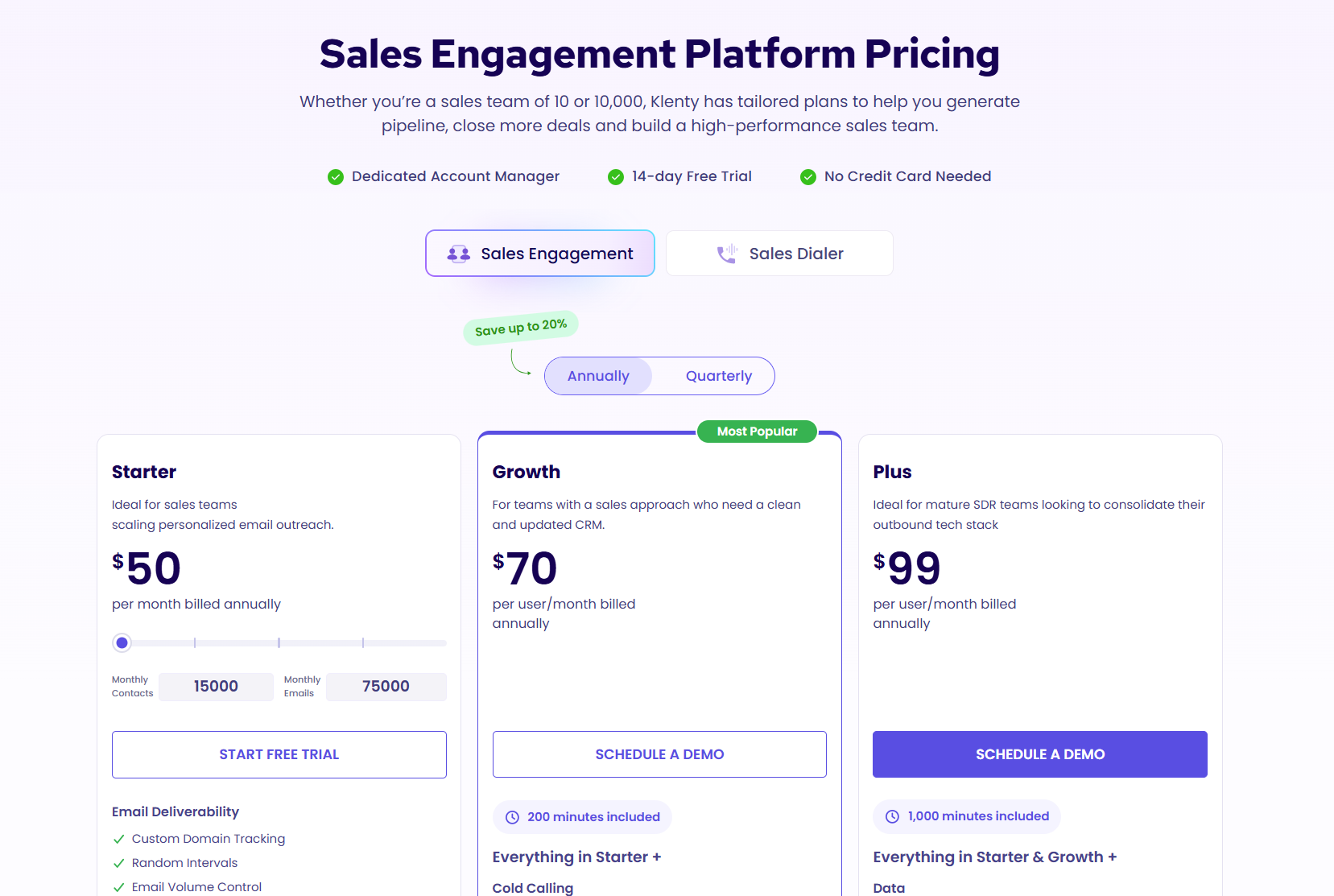
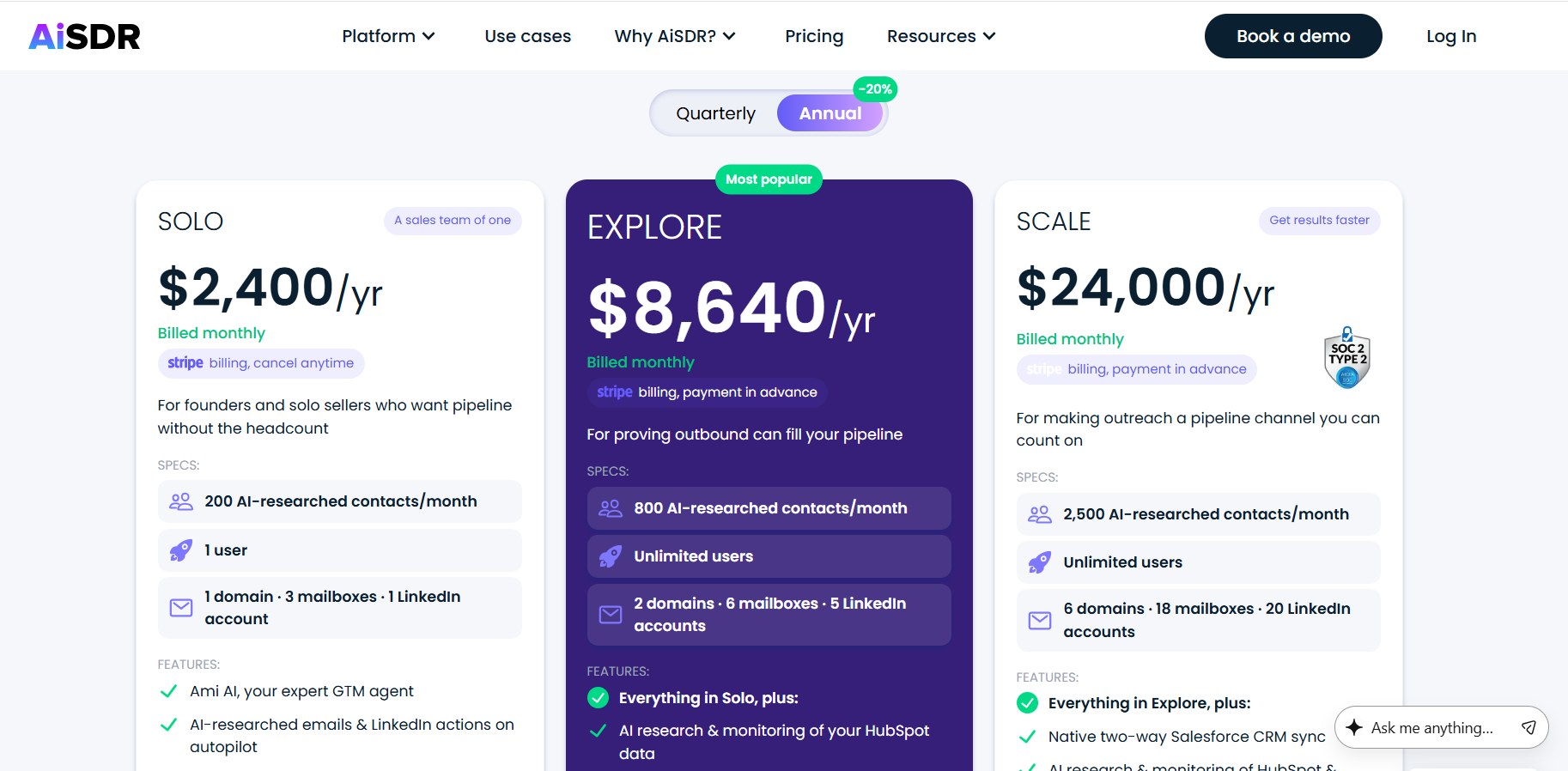
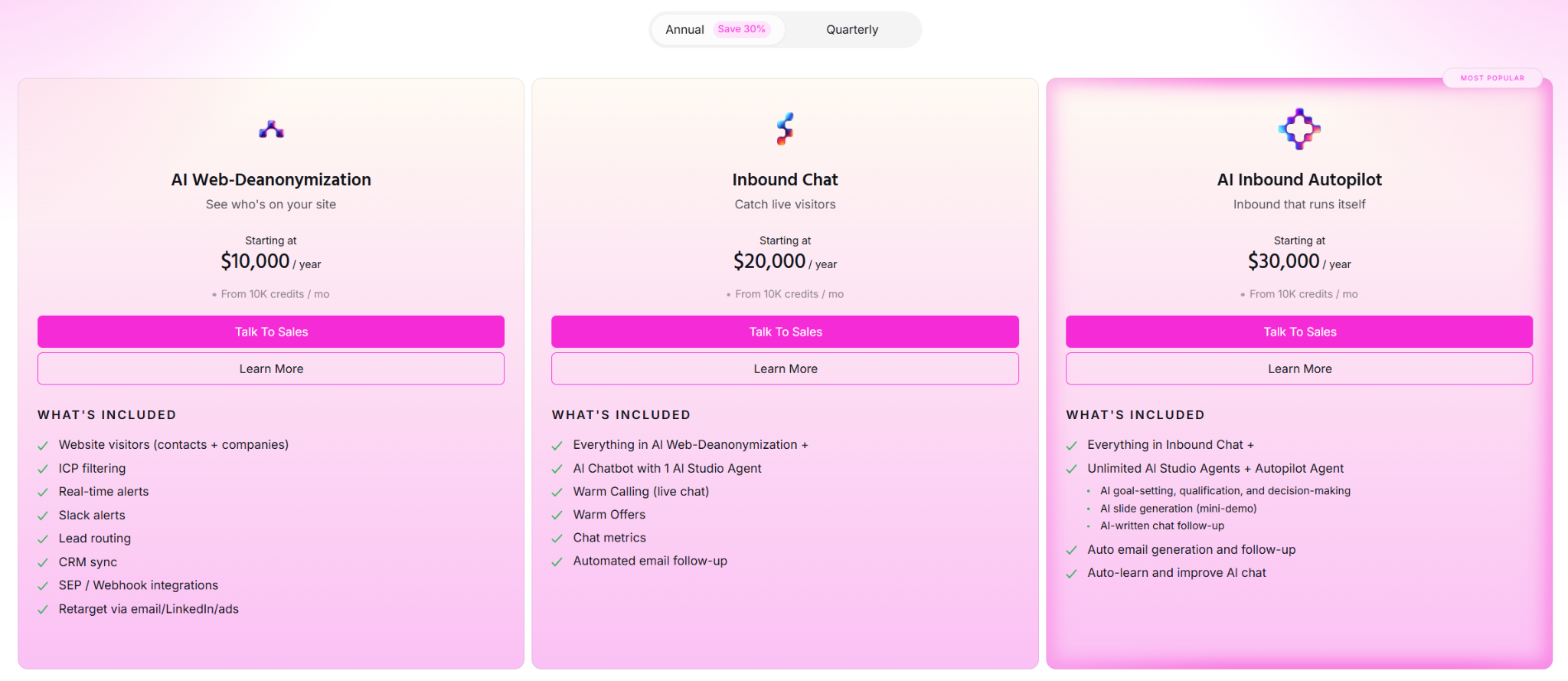
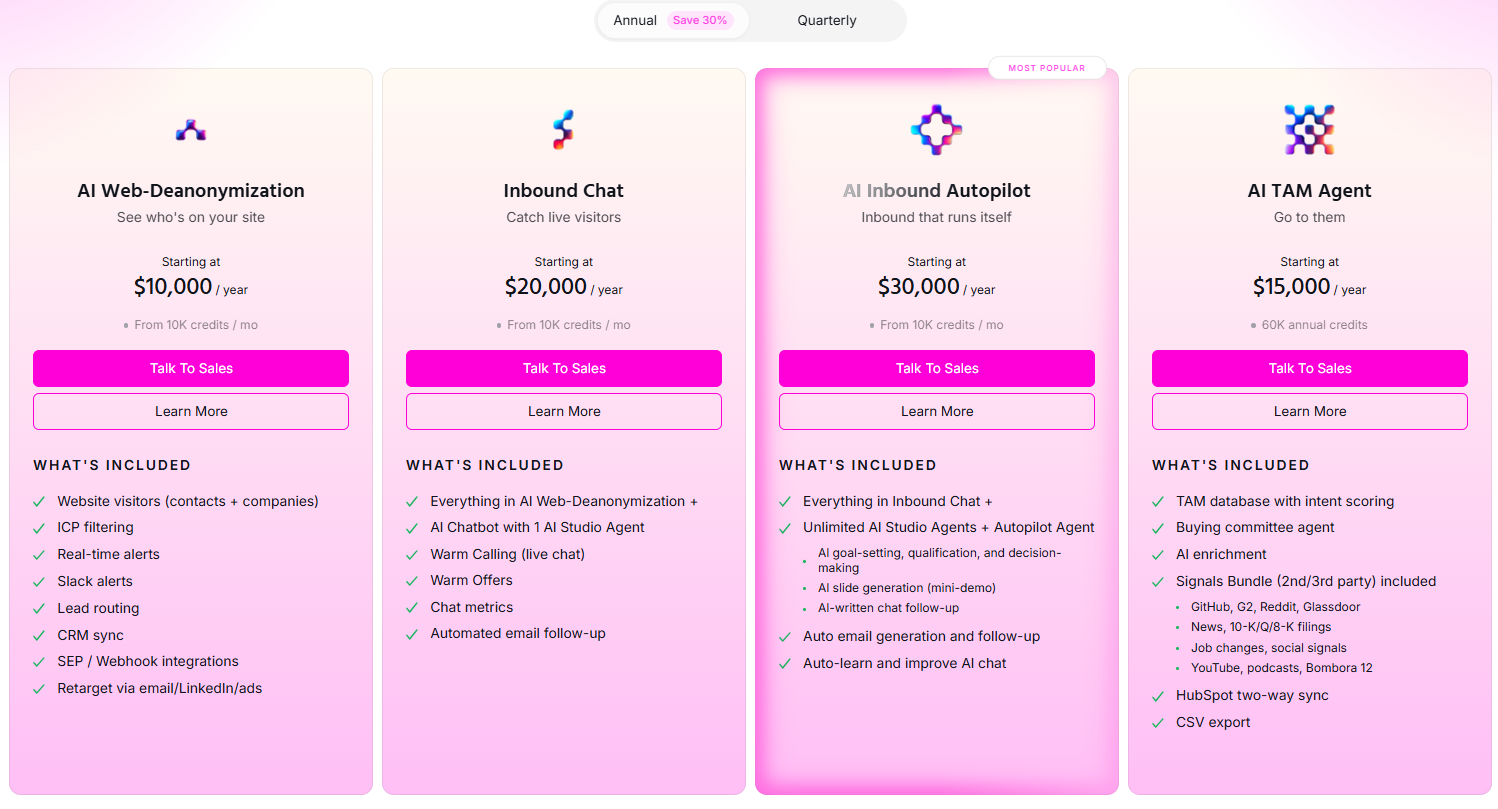
Pricing
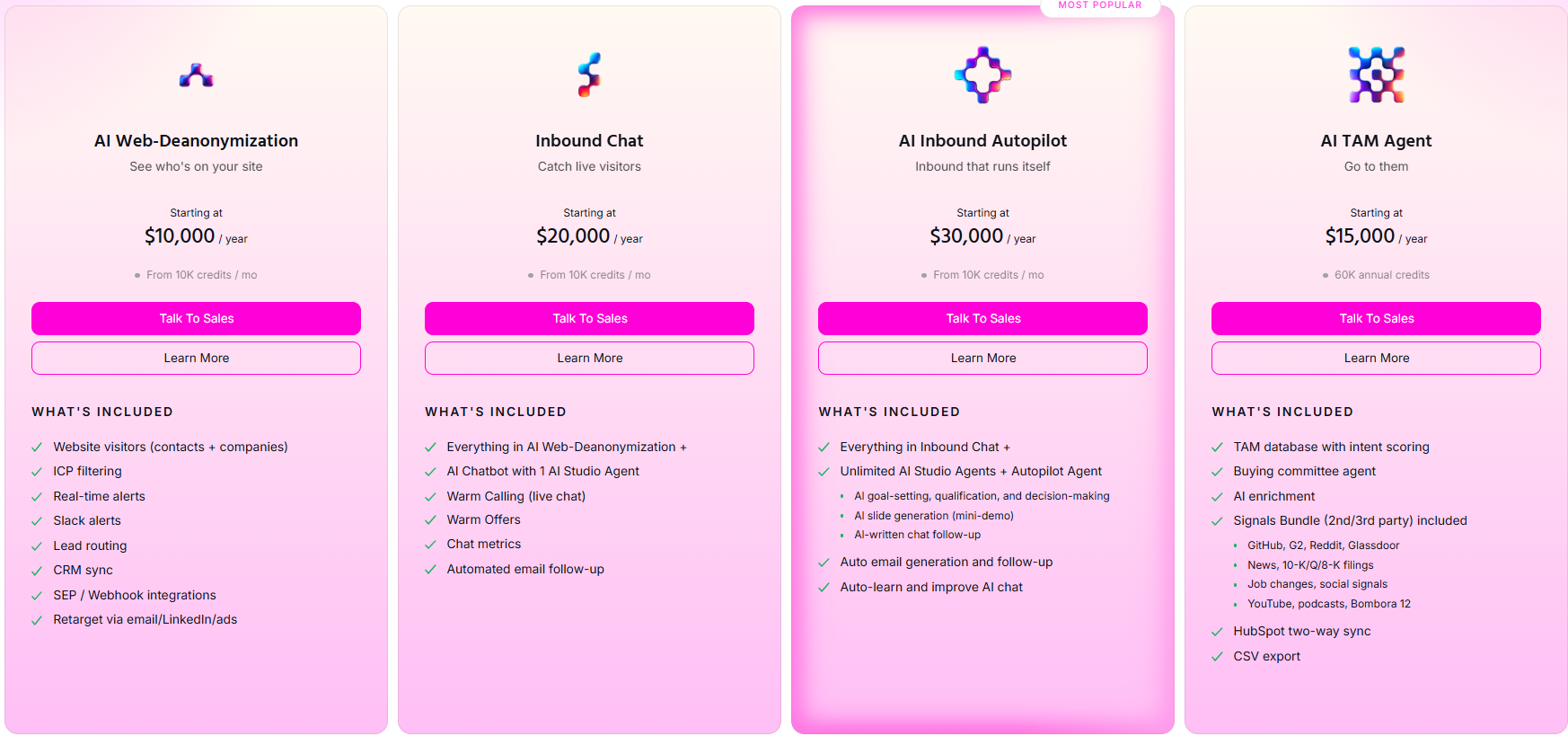
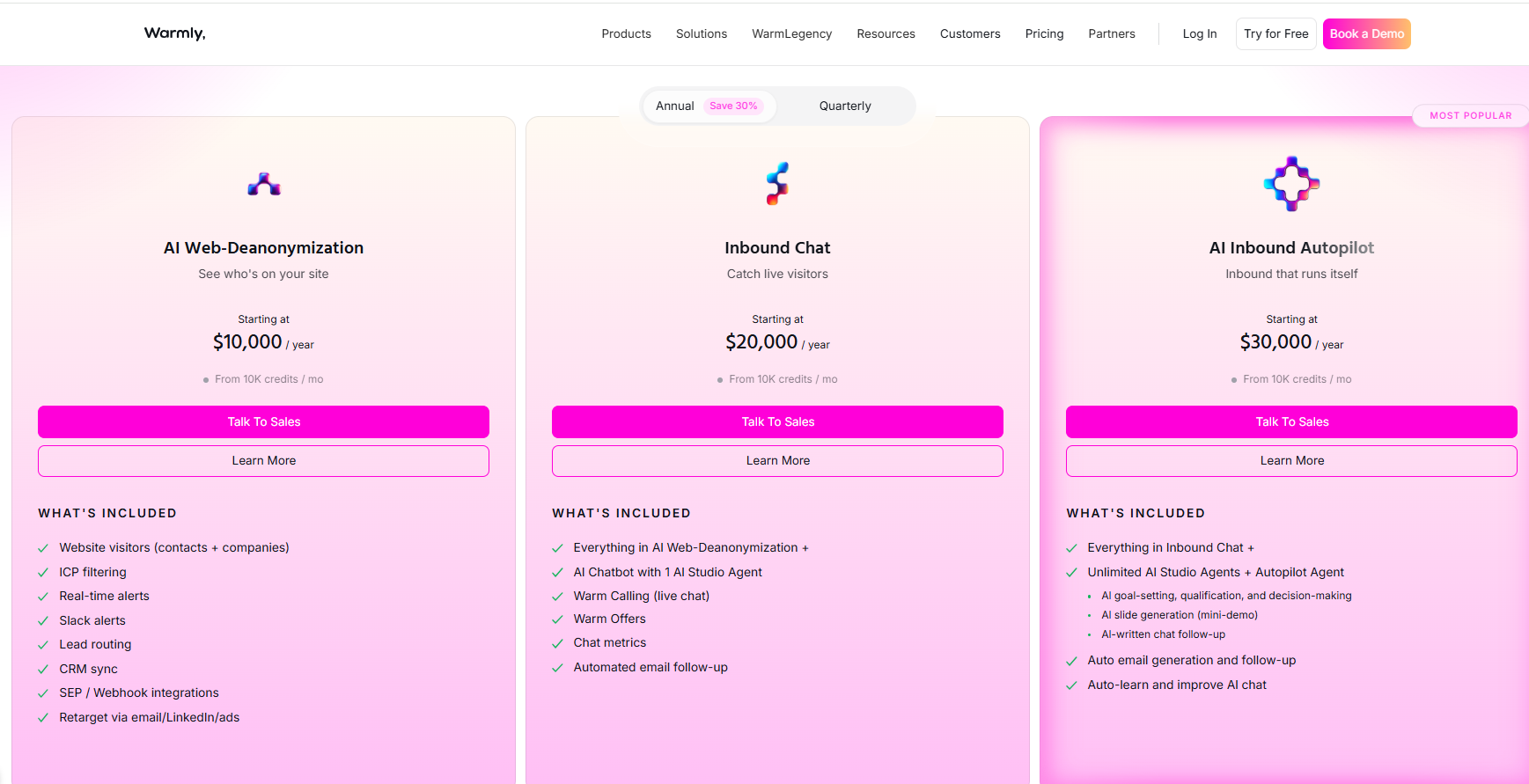
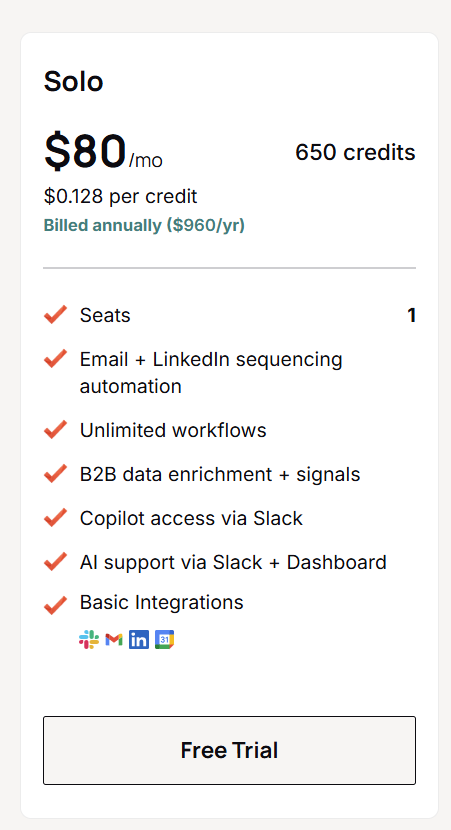
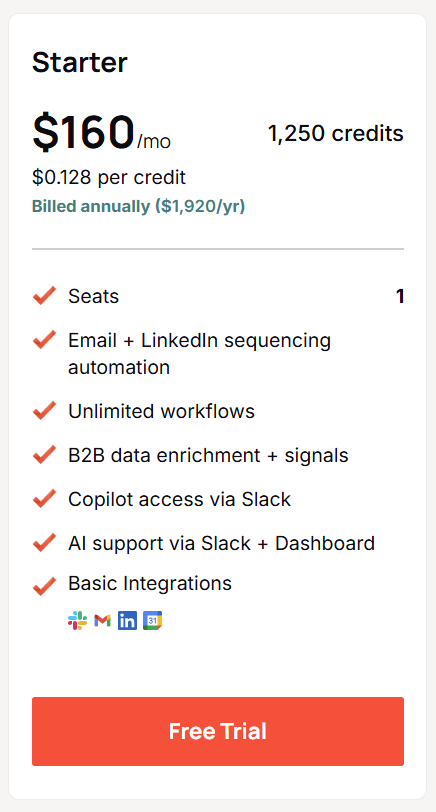
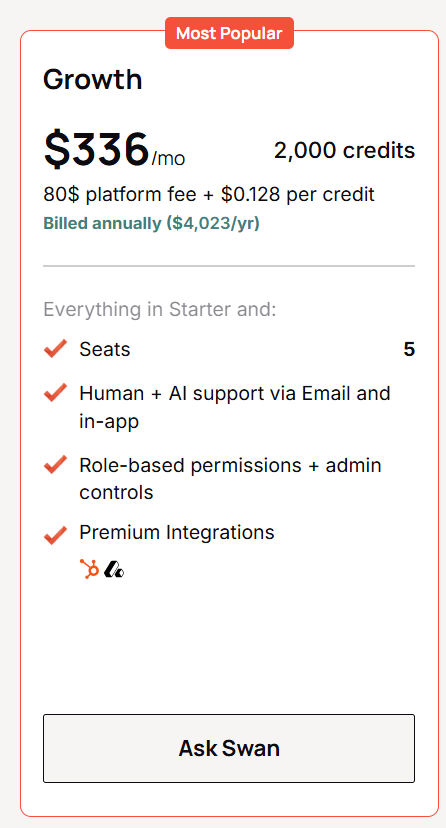
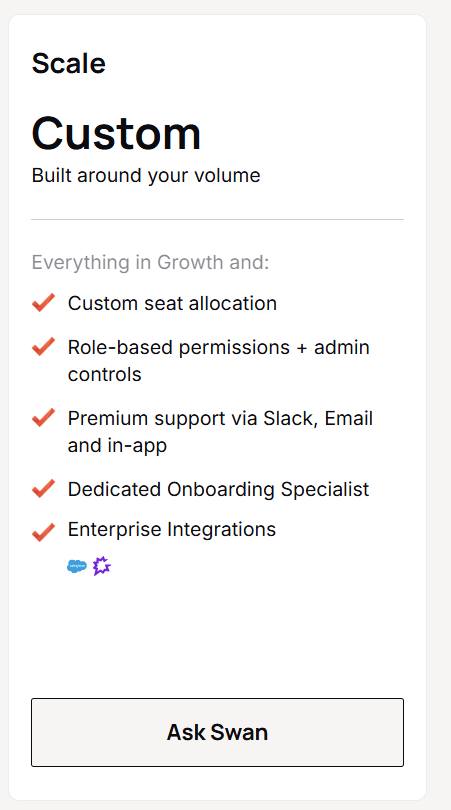
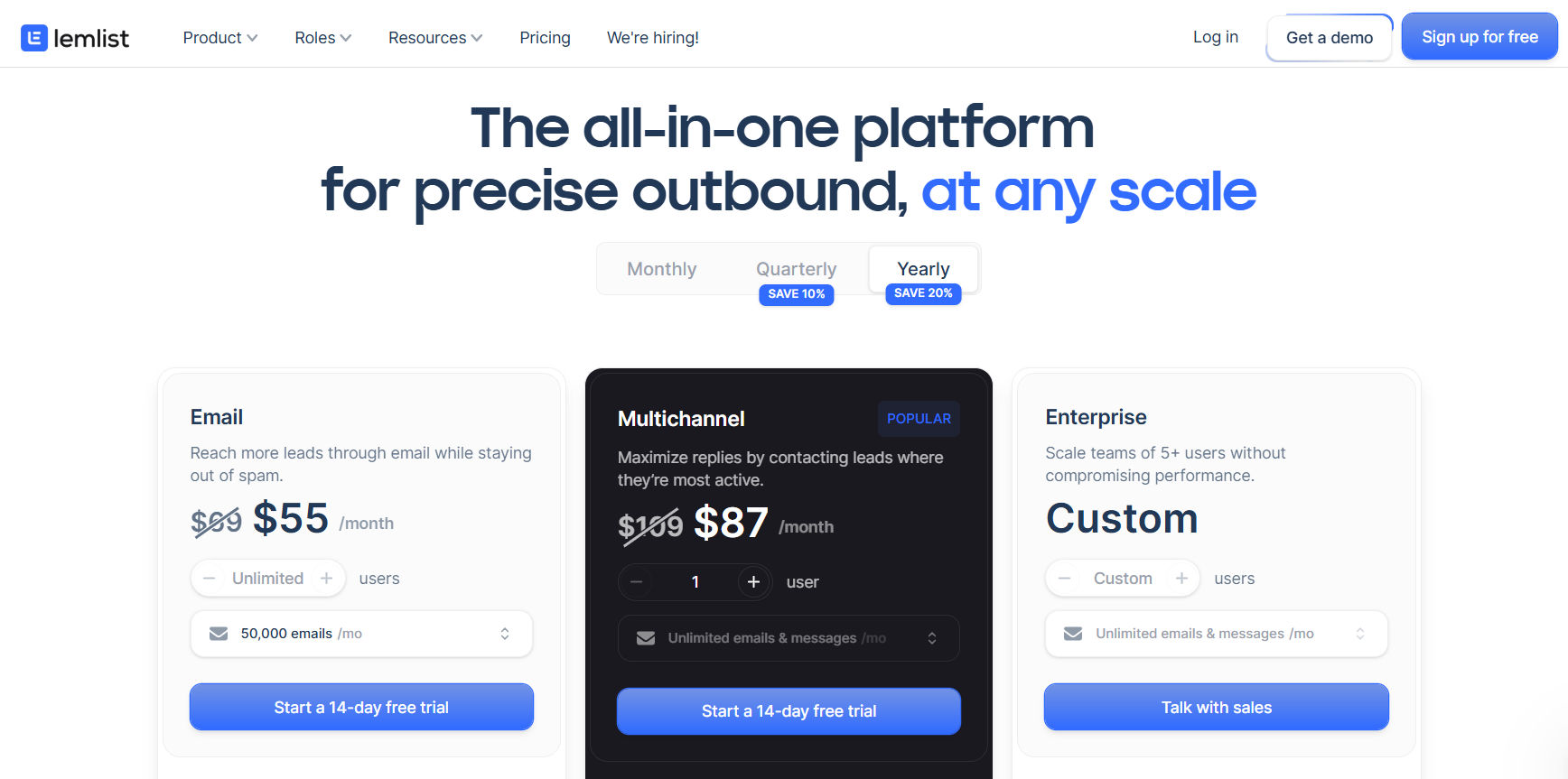
Warmly has a free tier plus three paid products that stack, and paid plans can be billed quarterly to try or annually for roughly 30% off.
- Free: identify up to 500 website visitors per month at the company level, with real-time Slack alerts and no automation.
- AI Web-Deanonymization: starts at $10,000/year and identifies your visitors at both the contact and company level, with ICP filtering, real-time Slack alerts, lead routing, CRM sync, and retargeting across email, LinkedIn, and ads.
- Inbound Chat: starts at $20,000/year and adds the AI chatbot, Warm Calling live video, Warm Offers, and automated email follow-up.
- AI Inbound Autopilot: starts at $30,000/year and adds unlimited AI Studio agents, autonomous qualification and decision-making, and self-improving AI chat.
Pros & Cons
✅ Person-level and company-level identification, worldwide.
✅ On-site engagement is built in: AI chat, live video, popups, and microsites.
✅ Outbound orchestration and inbound conversion share one intent model.
✅ A free plan lets you prove out the concept before committing budget.
❌ Needs real website traffic to get a good ROI.
#2: Leadfeeder
Best for: European teams that want reliable company-level identification sourced from trade registers, without requesting a custom quote.
Similar to: Lead Forensics, Snitcher.
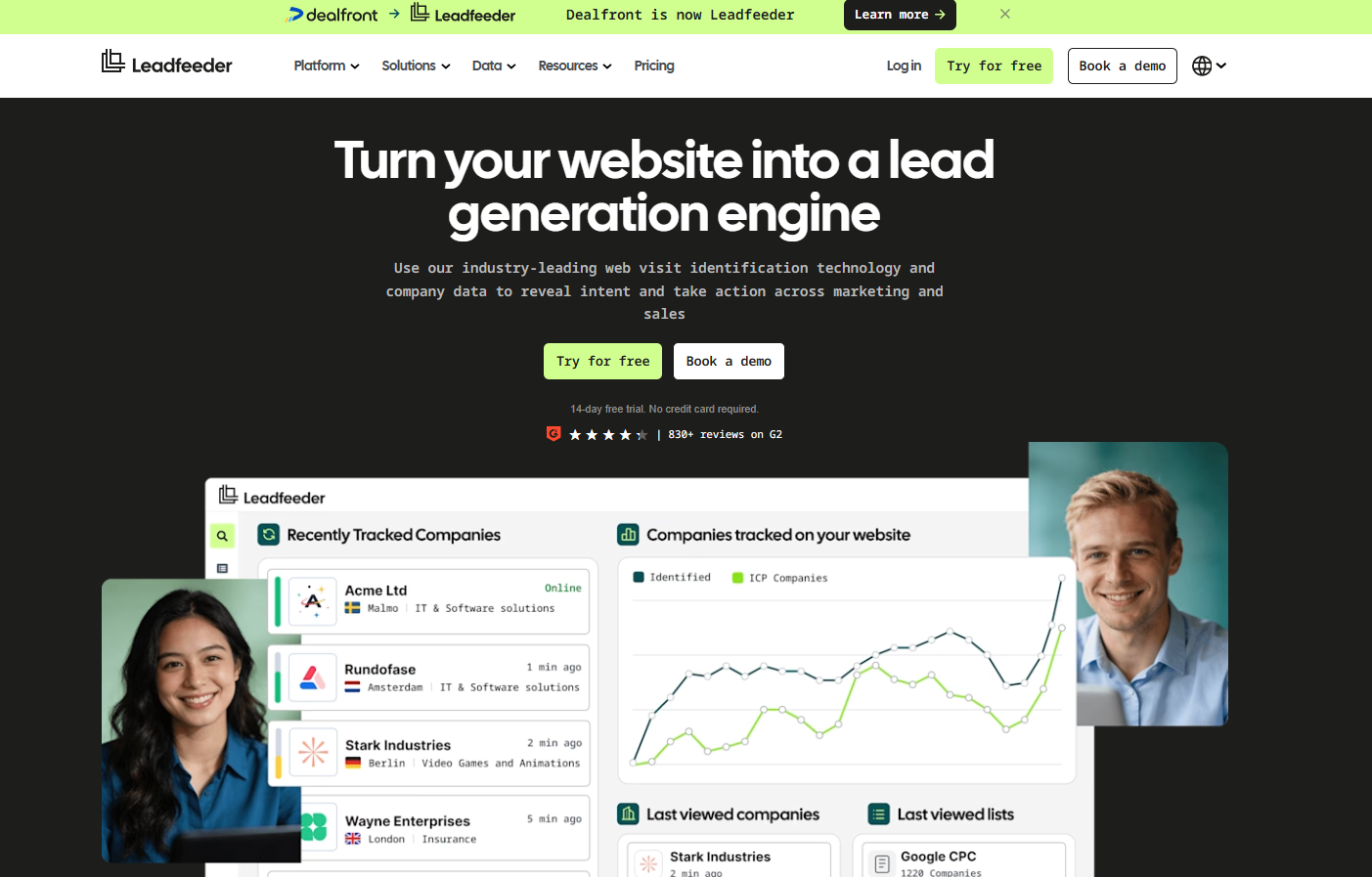
Leadfeeder ties anonymous website traffic to European trade-register firmographics and pushes matched accounts into your CRM.
Features
- Web Visitors: Identifies the companies browsing your site and shows which pages they viewed.
- Trade-register data: Pulls firmographics from official European registries for stronger accuracy on EU accounts.
- CRM push: Sends matched accounts to Salesforce, HubSpot, Pipedrive, Dynamics, and Slack.
- Intent filtering: Lets you build feeds of high-value accounts based on behavior and firmographics.
Pricing
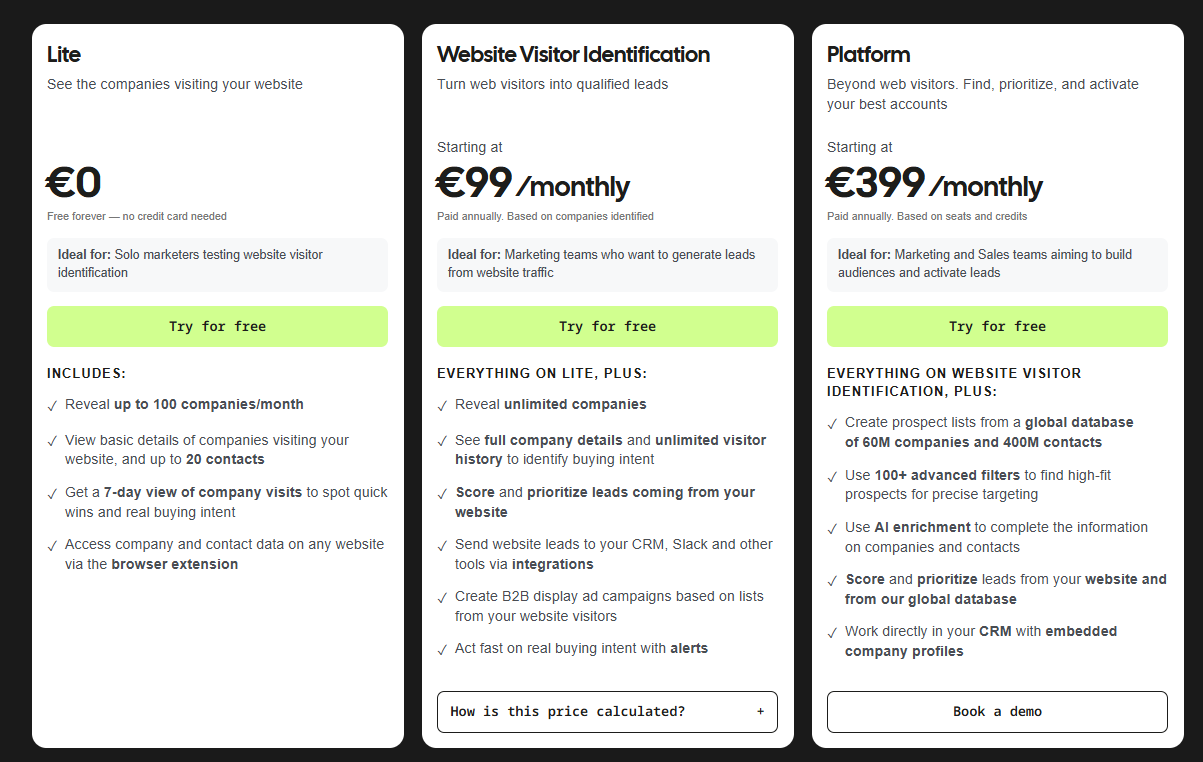
Leadfeeder offers a free plan and two paid tiers, with contact data priced as a separate module.
- Lite: Free forever for up to 100 company identifications per month, 20 contacts, and a 7-day view of company visits.
- Website Visitor Identification: From €99/month (annual billing, priced by companies identified) for unlimited company reveals, CRM sync, alerts, and ad campaign lists.
- Platform: From €399/month (annual, priced by seats and credits) for access to a 60M company and 400M contact database, AI enrichment, and embedded CRM profiles.
Pros & Cons
✅ Strong European company data drawn from official trade registers.
✅ A free plan and published visitor-tier pricing, uncommon among enterprise-leaning rivals.
✅ Native CRM push to Salesforce, HubSpot, Pipedrive, and Dynamics.
❌ Company-level identification only, no person-level.
#3: Lead Forensics
Best for: Teams that depend on same-day company alerts and want a vendor with a long support track record.
Similar to: Leadfeeder, ZoomInfo.

Lead Forensics draws on a large reverse-IP database that matches visiting companies in real time and surfaces decision-maker contacts alongside firmographic detail.
Features
- Real-time identification: Matches visiting companies against a database it says covers 1.4 billion IP addresses.
- Decision-maker contacts: Adds names and contact details for people inside identified accounts.
- Visitor scoring: Flags which accounts are worth a rep's attention first.
- CRM integrations: Connects with Salesforce, HubSpot, Pipedrive, Zoho, and Dynamics.
Pricing
Lead Forensics does not disclose pricing publicly; you'll need to contact their team for a quote.
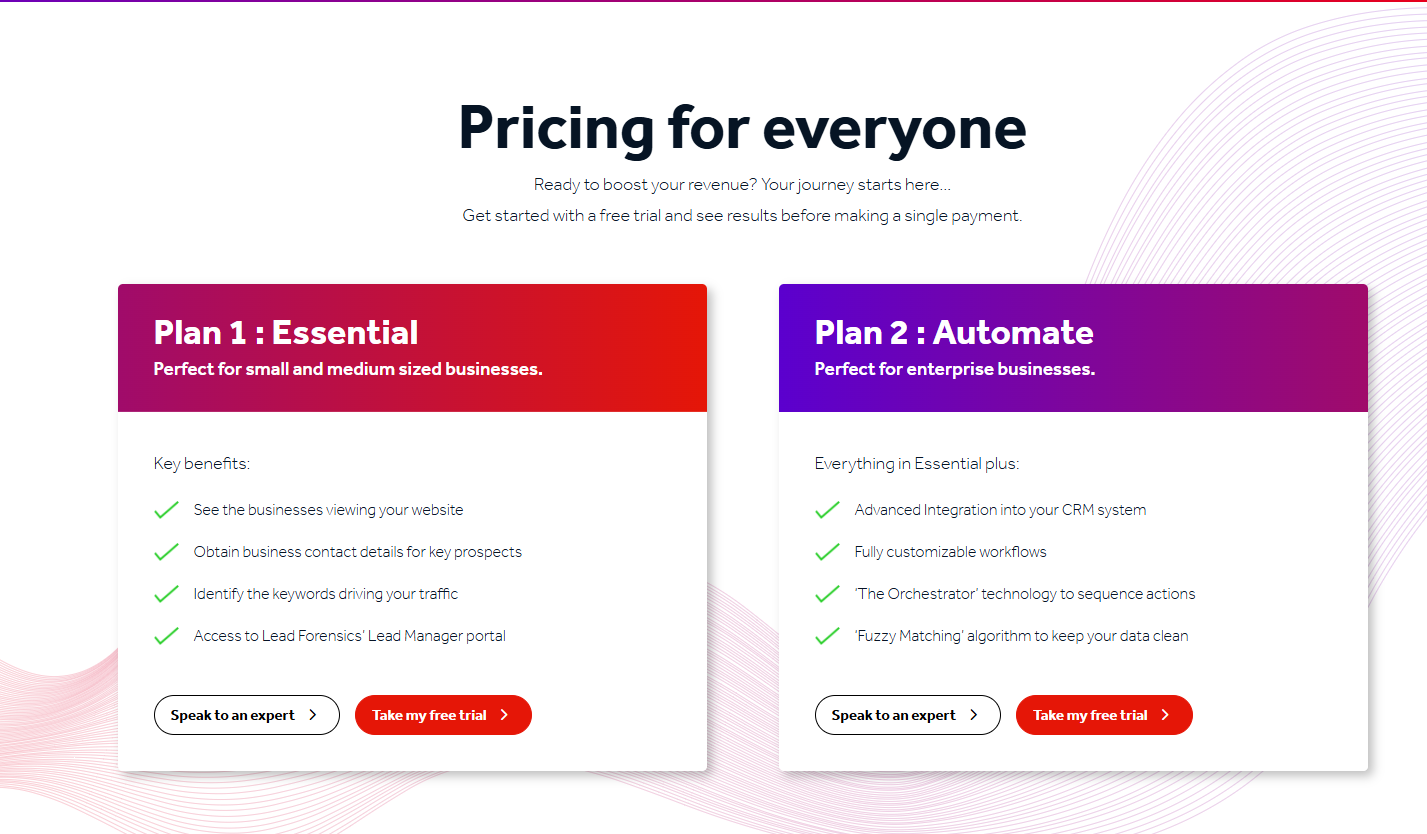
Pros & Cons
✅ Real-time company alerts backed by a large, long-running IP match database.
✅ Native Salesforce integration.
✅ Onboarding and ongoing training.
❌ Pricing is custom.
#4: Snitcher
Best for: Budget-conscious SMB and mid-market teams that work inside Google Analytics 4 and want transparent pricing.
Similar to: Leadfeeder, Albacross.
Snitcher matches website visitors to companies and feeds the enriched data straight into Google Analytics 4, adding a person-level signal to the company match.
Features
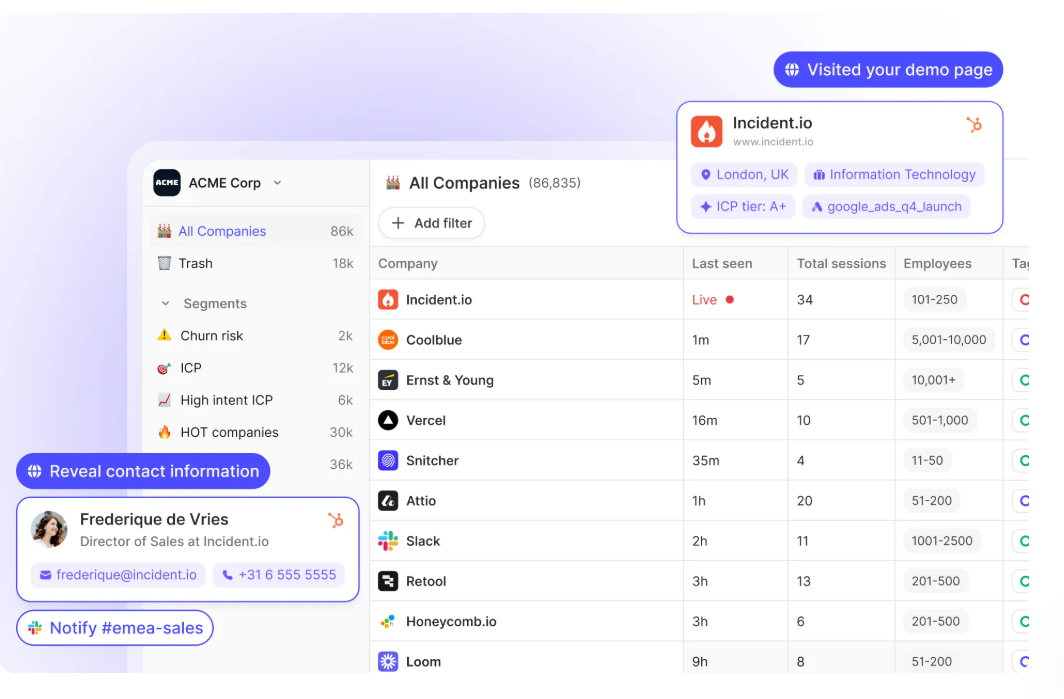
- Company identification: Reveals the businesses visiting your site and tracks their journey across pages.
- GA4 integration: Feeds enriched visitor data straight into Google Analytics 4.
- Person-level layer: Adds individual-level signals to the company match.
- Lead scoring: Automates prioritization so reps focus on the warmest accounts.
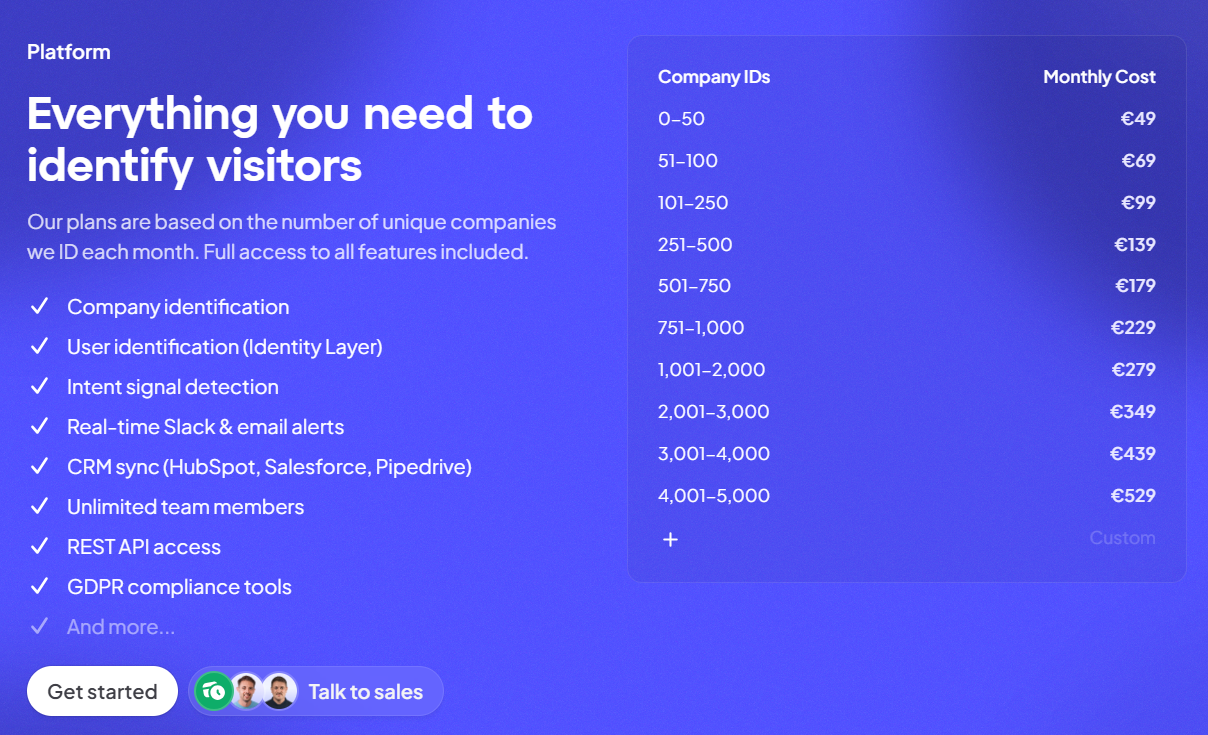
Pricing
Snitcher prices by the number of companies you identify each month, with every feature included on every tier.
- Entry pricing: starts from €49/month and scales up with volume.
- Billing: annual plans lower the monthly rate.
- Contact reveals: individual contact data costs extra on top of the base plan.
- Trial: 14 days, full access, no card required.
Pros & Cons
✅ Published, usage-based pricing with every feature on every tier.
✅ Direct Google Analytics 4 integration that most rivals don't match.
✅ Person-level signals in addition to company identification.
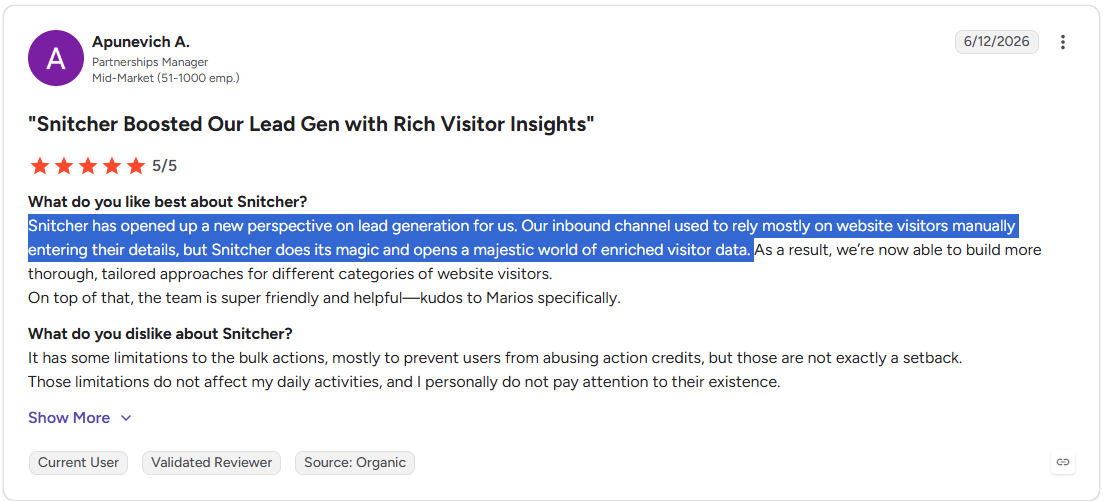
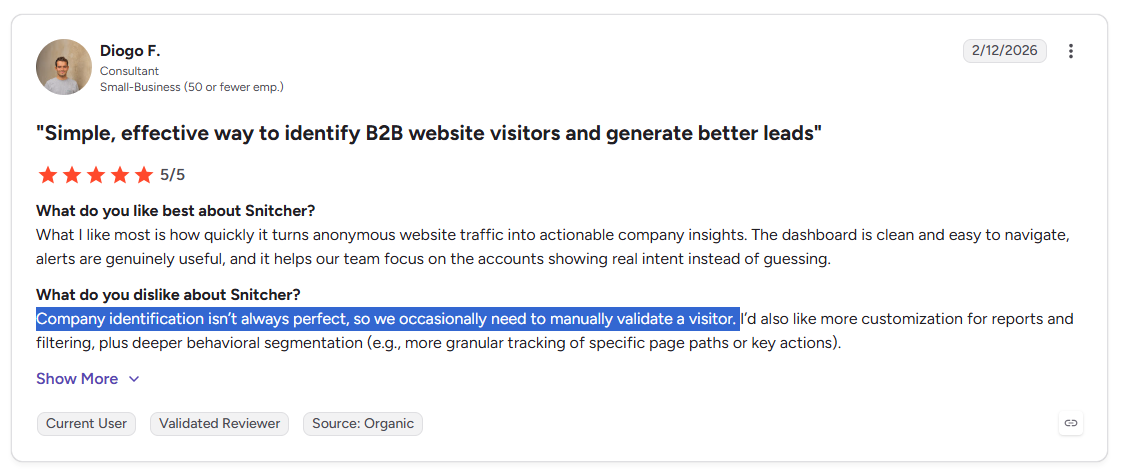
❌ Company identification isn’t always perfect, according to a G2 review.
#5: Albacross
Best for: Smaller European teams that want a GDPR-first tool with a low, published entry price to pilot visitor identification.
Similar to: Leadinfo, Snitcher.
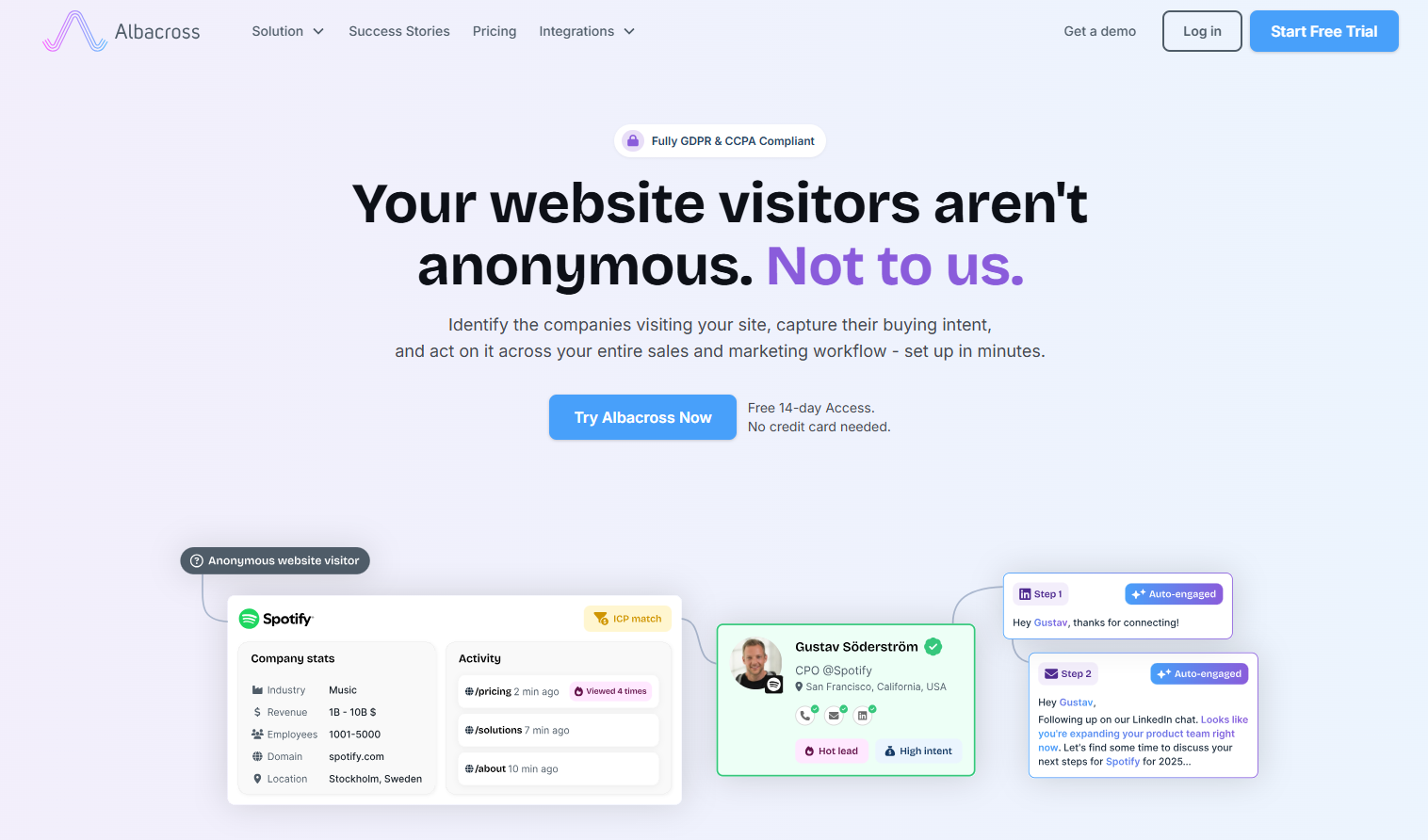
Albacross identifies visiting companies from European registry data and keeps the whole setup GDPR-first, with EU data residency built in.
Features
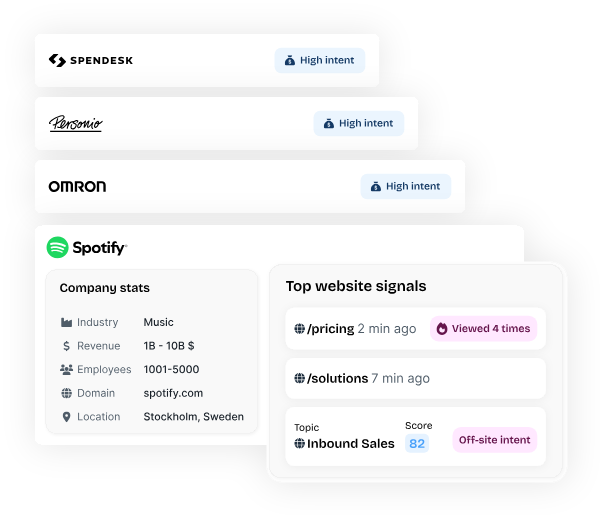
- Company identification: Matches anonymous traffic to companies with strong European coverage.
- Bombora intent: Adds third-party intent signals to the first-party website data.
- Auto-segmentation: Groups incoming leads by built-in and custom filters.
- Native CRM sync: Connects with HubSpot, Salesforce, Pipedrive, and Slack.
Pricing
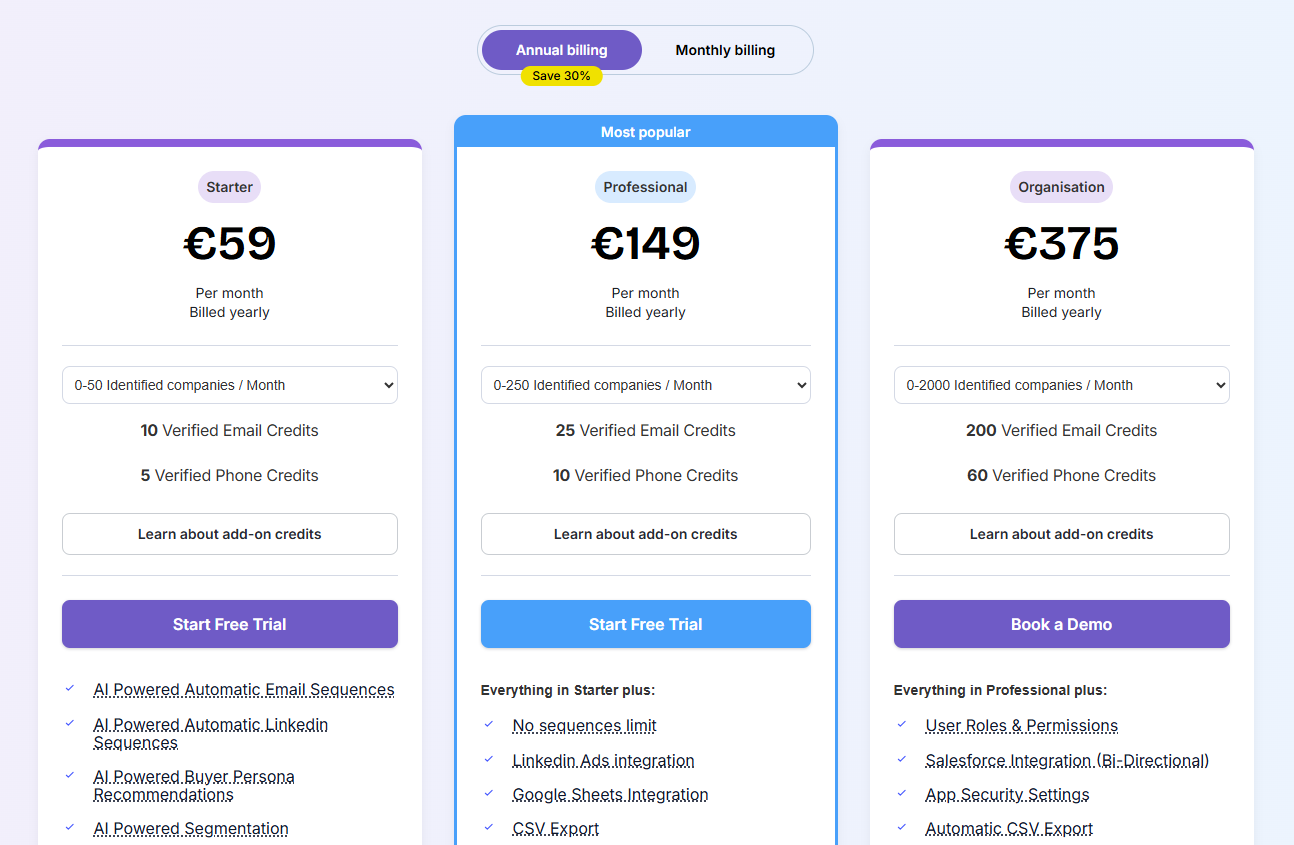
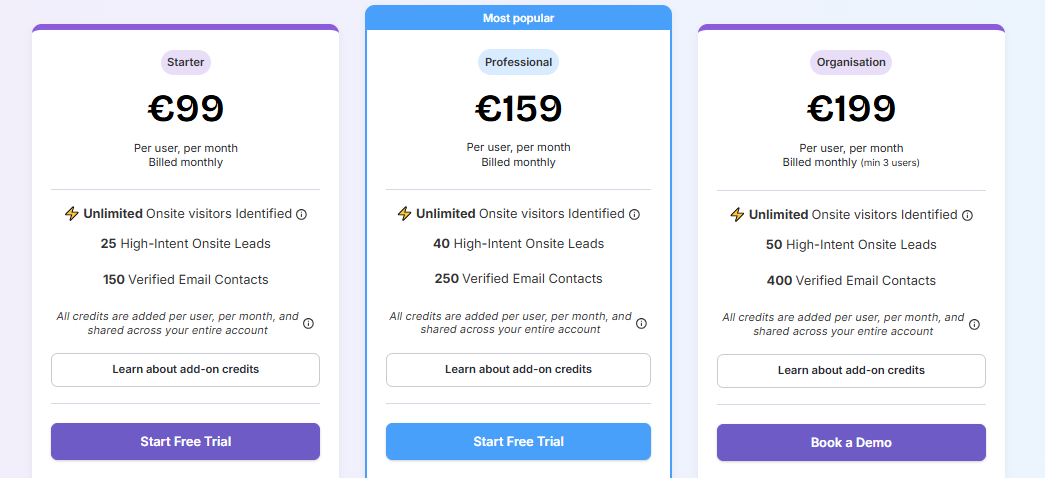
Albacross publishes three annual tiers that scale by the number of companies you identify.
- Starter: €59/month billed annually for up to 100 identified companies.
- Professional: €149/month billed annually for up to 1,000 companies.
- Organisation: €375/month billed annually for 5,000 companies and up.
Monthly billing runs higher than the annual rate, and there's a 14-day trial.
Pros & Cons
✅ GDPR-first with EU data residency.
✅ Published pricing that starts low for European teams.
✅ Bombora intent and native CRM integrations.
❌ Company-level only; no person-level reveal.
#6: Leadinfo
Best for: Benelux, DACH, and now North American SMB teams that want an easy daily workflow with chatbot and automation add-ons.
Similar to: Albacross, Leadfeeder.
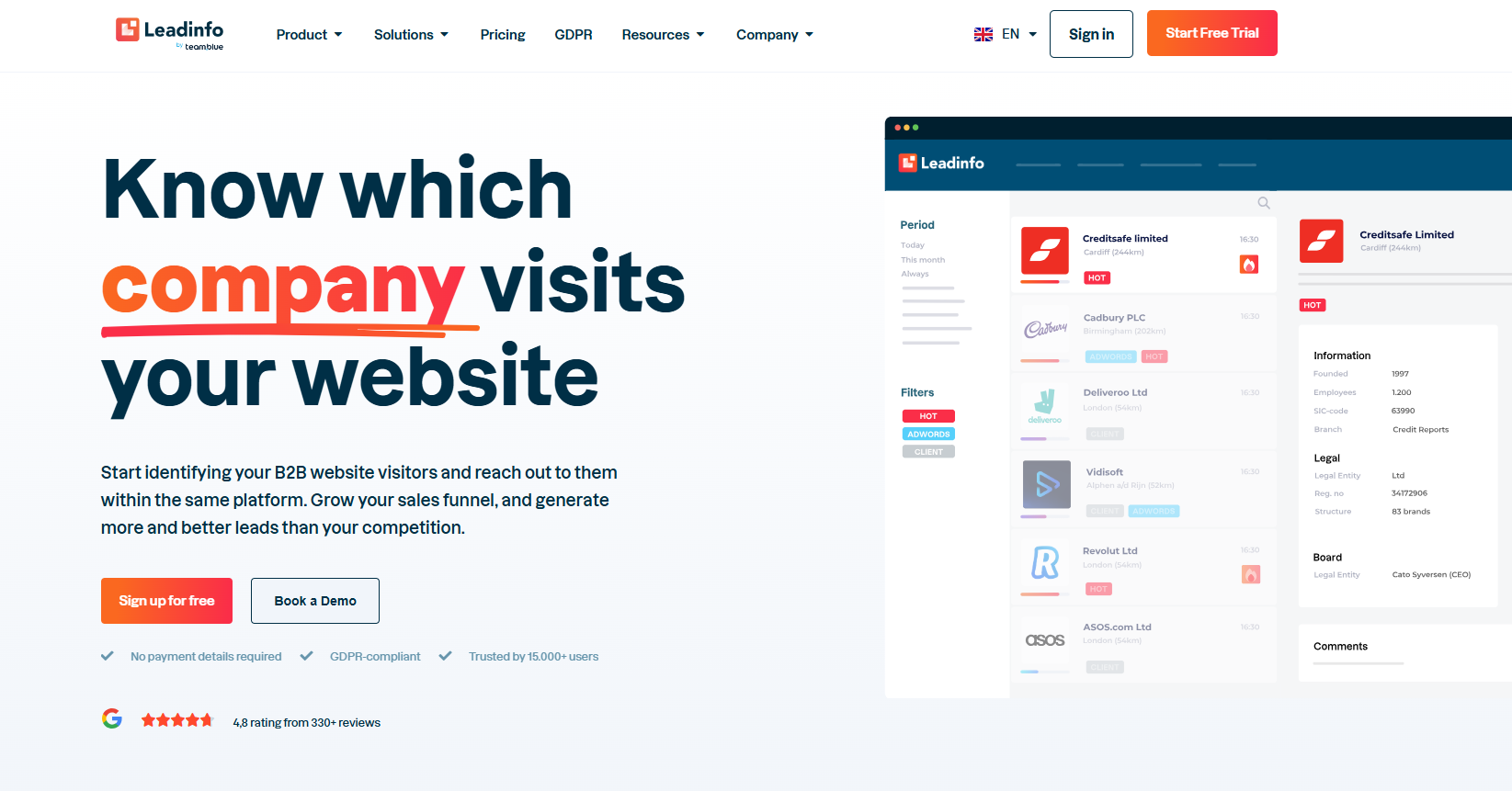
Leadinfo reveals company-level visits across more than 200 countries and pairs the data with a chatbot, website personalization, and automation add-ons.
Features
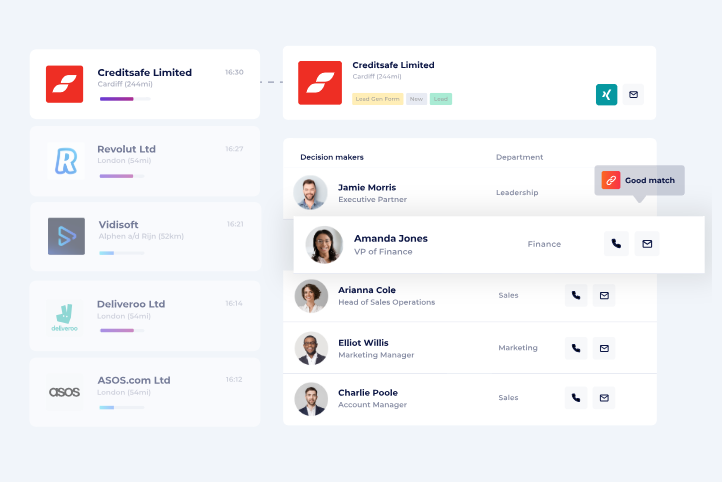
- Company identification: Matches visits to a database of 220 million-plus companies worldwide.
- Leadbot: A built-in chatbot that engages visitors on site.
- Liquid Content: Personalizes website content by visitor profile.
- Autopilot: Automates follow-up actions based on visitor behavior.
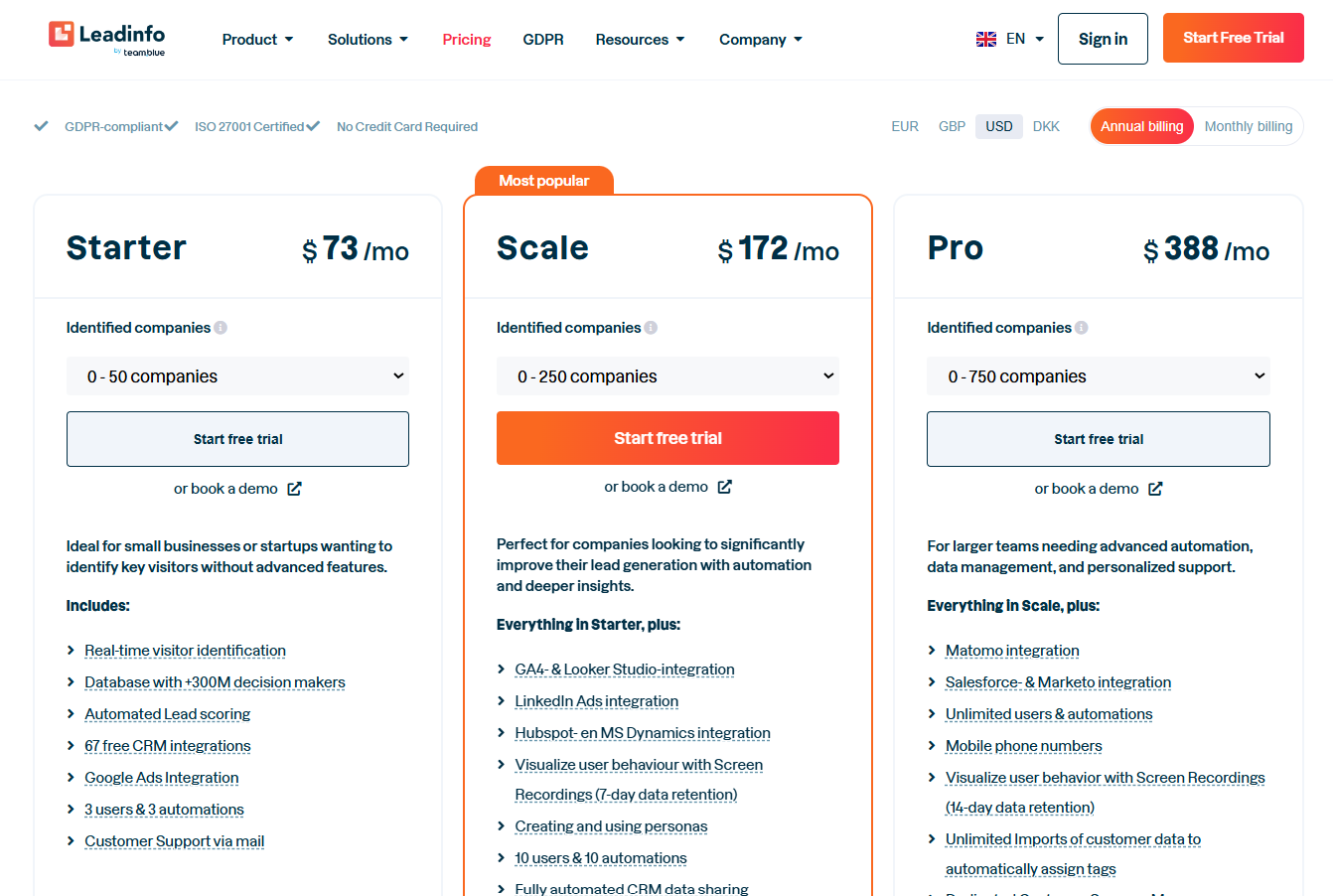
Pricing
Leadinfo runs three plans priced by identified companies, with feature add-ons sold separately.
- Starter: from $73/month, scaling by the number of companies identified.
- Scale: from $172/month, adding GA4 integration and session recordings.
- Pro: from $388/month with unlimited users and a dedicated CSM.
Pros & Cons
✅ Broad coverage across 200-plus countries, now including North America.
✅ Chatbot, personalization, and automation available as add-ons.
❌ No free plan.
#7: RB2B
Best for: US-based teams after a fast, low-lift way to see which individuals are on their site.
Similar to: Snitcher.
RB2B spots individual US visitors and sends their LinkedIn profiles to Slack in real-time.
Features
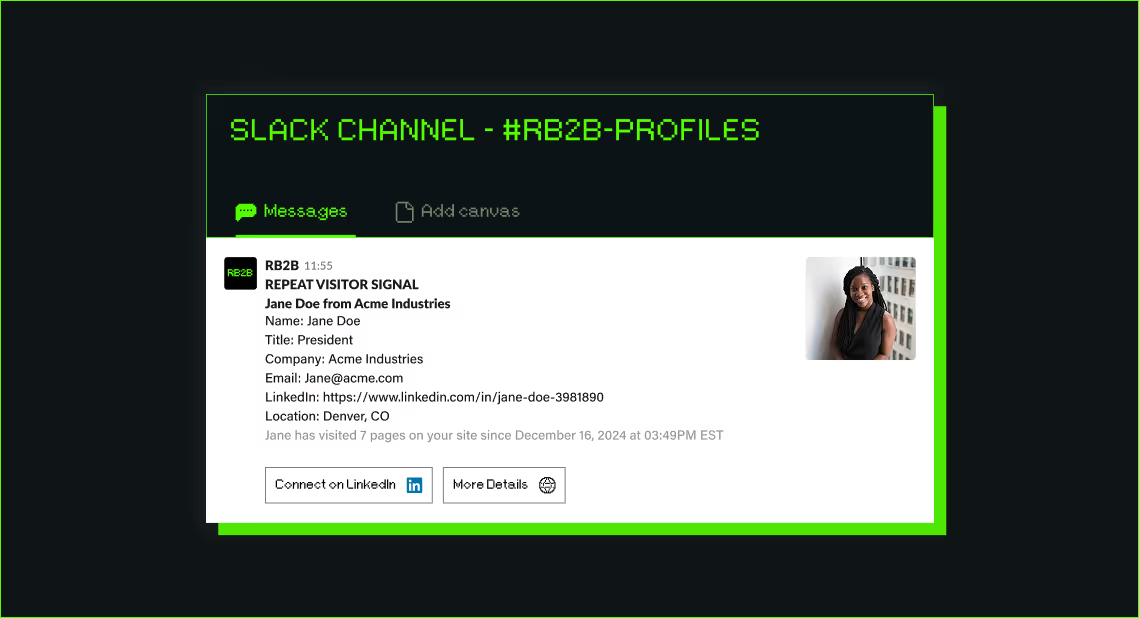
- Person-level ID: Reveals the individual behind a US visit, alongside their company.
- Slack delivery: Pushes LinkedIn profiles and names to Slack in real time.
- Filters: Lets you drill down to high-value visitors.
- Integrations: Connects with HubSpot, Salesforce, Apollo, Clay, and Zapier on paid plans.
Pricing
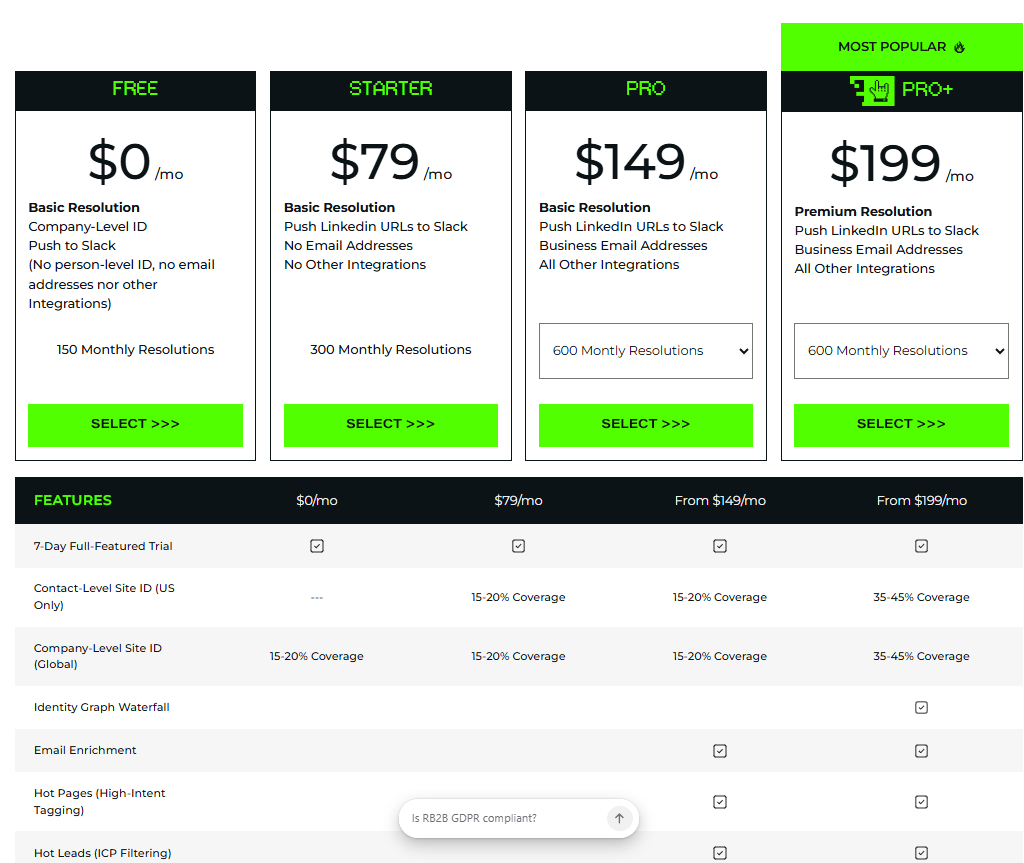
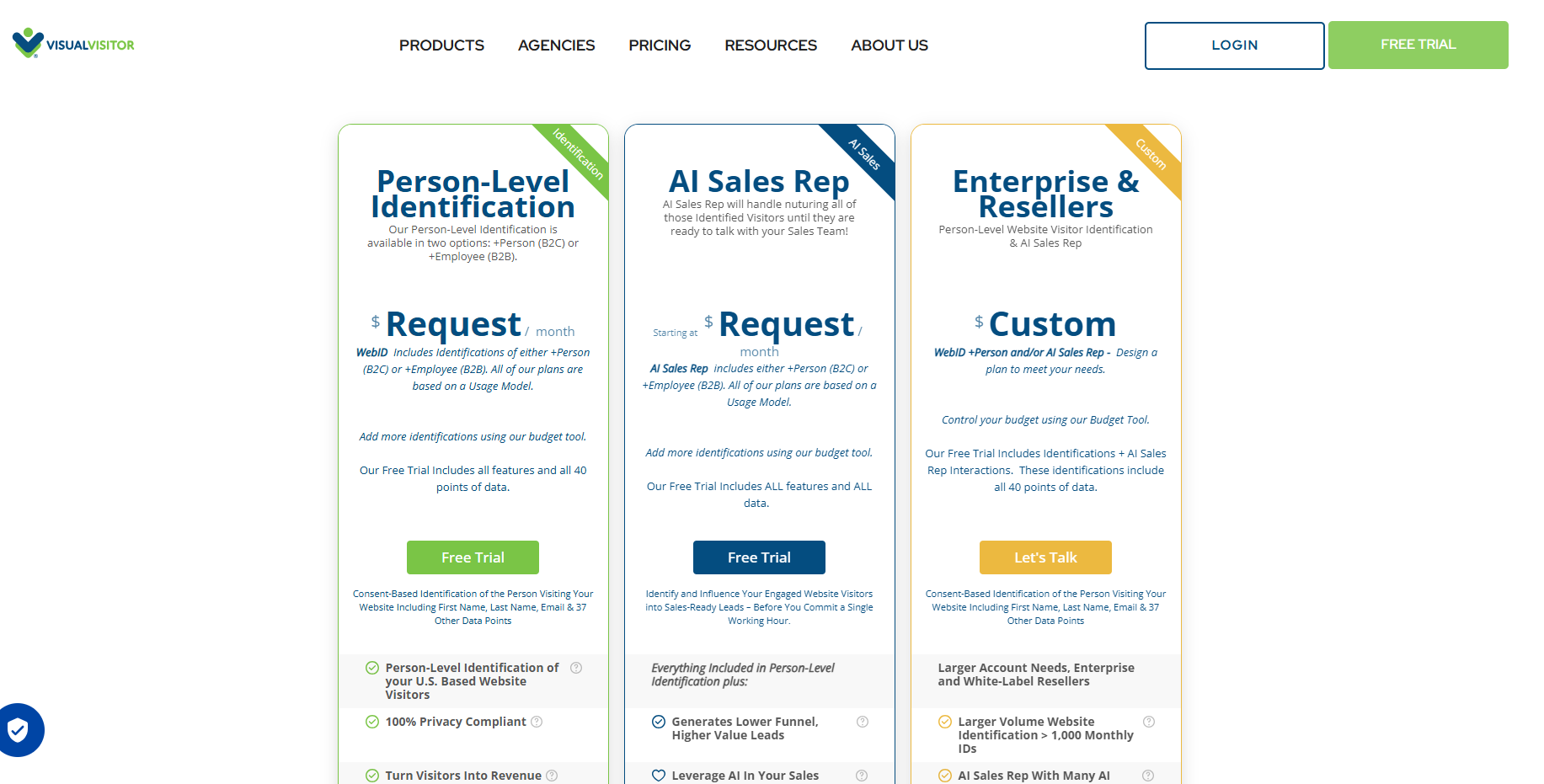
RB2B has a free plan and three paid tiers priced by monthly resolution credits.
- Free: 150 company-level resolutions per month to Slack, with no person-level ID since January 2026.
- Starter: $79/month for 300 resolutions with LinkedIn URLs and US person-level ID.
- Pro: from $149/month for 600 resolutions plus business emails and integrations.
- Pro Plus: from $199/month with wider resolution coverage.
Pros & Cons
✅ Person-level identification delivered to Slack in real time.
✅ A free entry point and low paid tiers.
✅ More than 50 integrations, including HubSpot, Salesforce, and Clay.
❌ The paid versions are expensive for a solo founder, according to a G2 review.
#8: ZoomInfo
Best for: Enterprise revenue teams that need one of the deepest contact databases plus company-level visitor ID at scale.
Similar to: 6sense, Lead Forensics.
ZoomInfo pairs a huge B2B contact database with WebSights, its website visitor identification module, and adds intent data and a sequencer for outreach.
Features
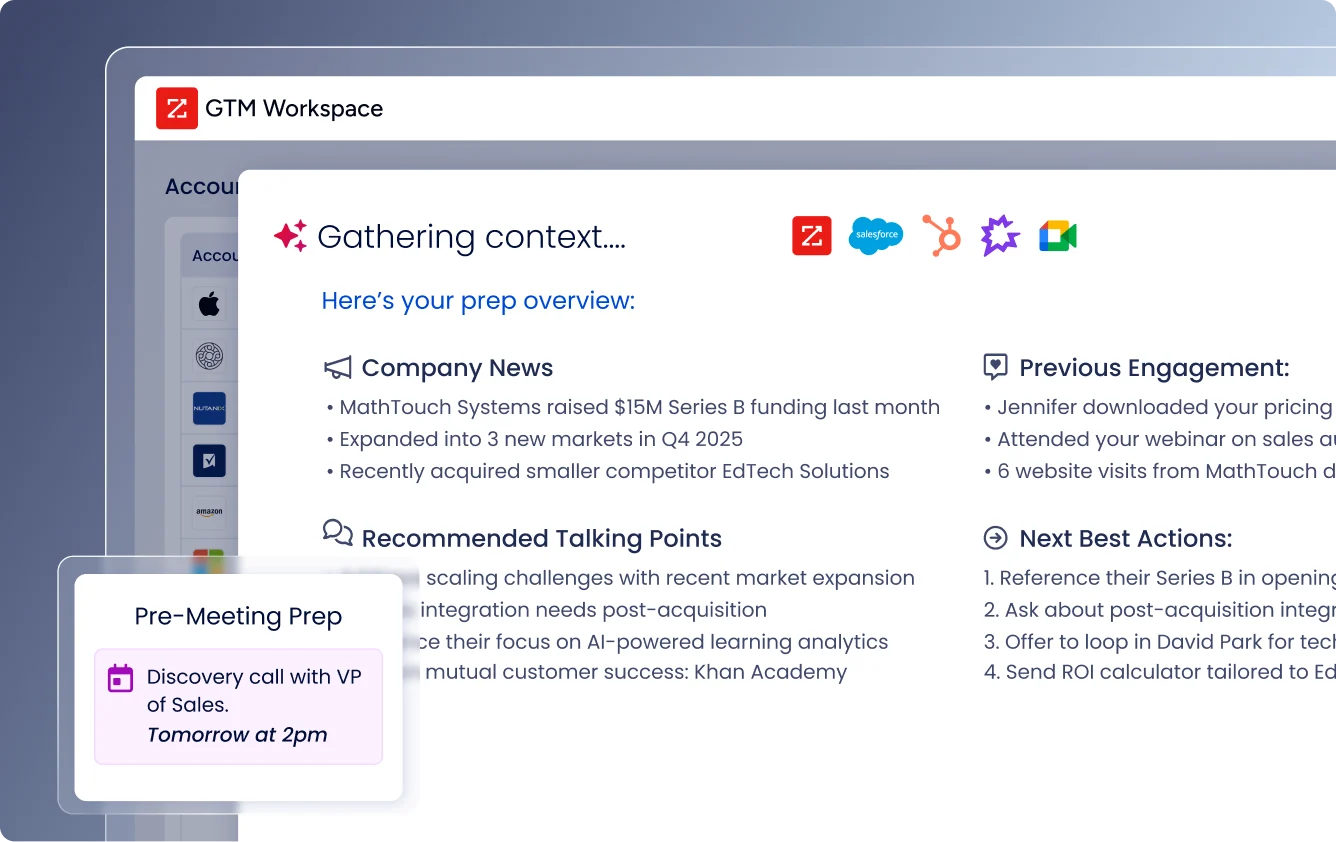
- B2B database: Hundreds of millions of contact and company profiles with enrichment.
- WebSights: Identifies the companies visiting your website.
- Intent data: Surfaces accounts researching your category across the web.
- Engage: A built-in sequencer for outreach.
Pricing
ZoomInfo doesn't disclose pricing publicly; you'll need to contact their team for a quote. ZoomInfo Lite is a free tier for limited use.
Pros & Cons
✅ One of the deepest B2B contact and company databases available.
✅ WebSights adds company-level visitor ID to the data platform.
✅ Buying-committee mapping and intent at enterprise scale.
#9: 6sense
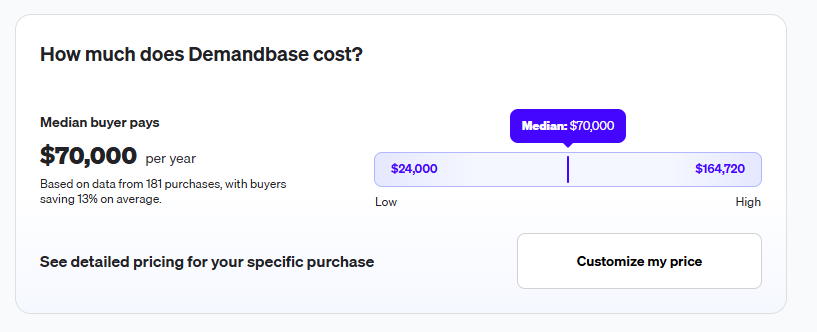
Best for: Enterprise ABM programs that can fund a predictive engine and want intent aggregated from several providers.
Similar to: ZoomInfo, Demandbase.
6sense is a Revenue AI platform built around predictive account scoring, with website deanonymization and third-party intent feeding the model.
Features

- Predictive scoring: Ranks accounts by buying stage and fit using AI models.
- Website deanonymization: Identifies companies on your site and folds them into account scores.
- Multi-source intent: Aggregates signals from several third-party providers.
- Advertising: Runs targeted campaigns off the same account data.
Pricing
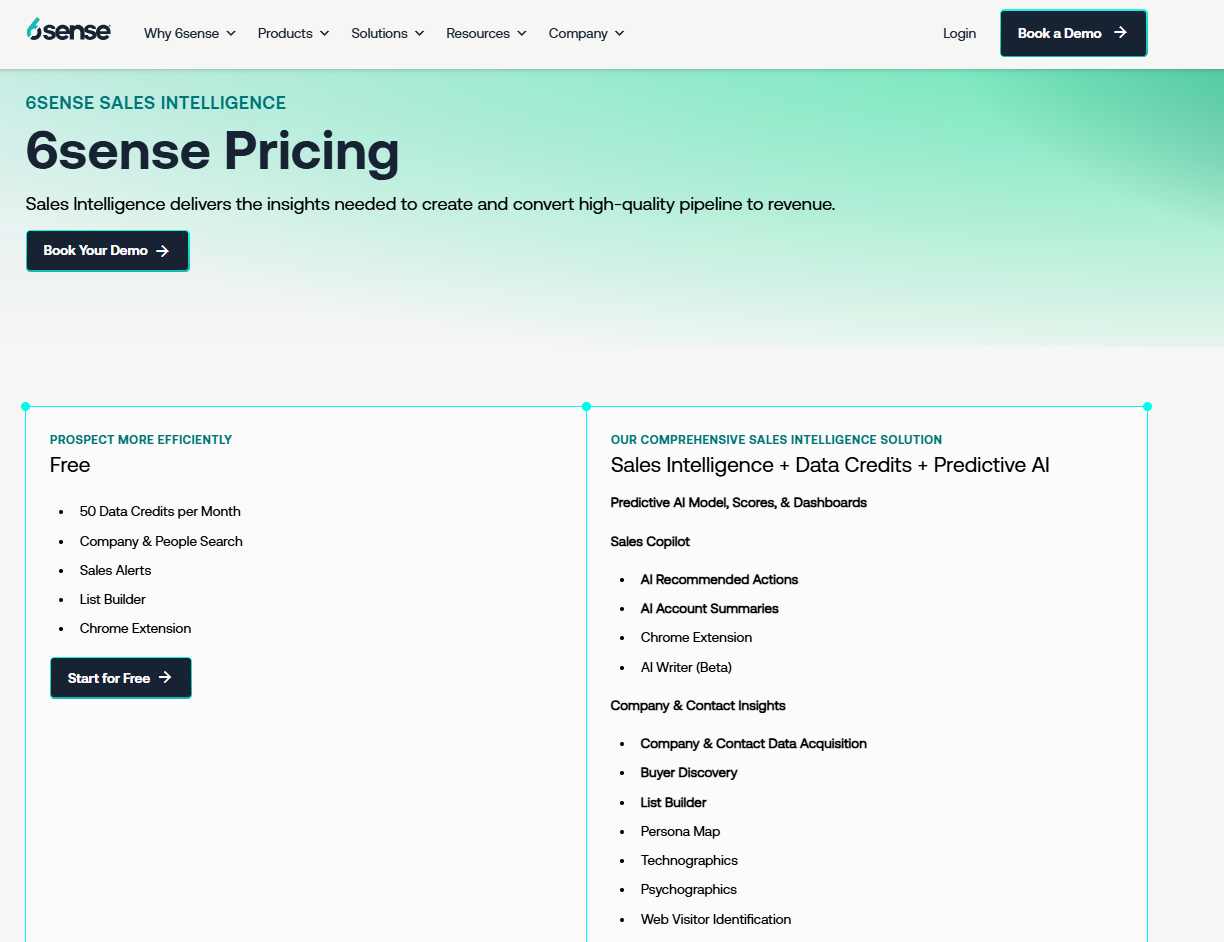
6sense has a free plan with 50 credits/month covering company and people search, sales alerts, and a Chrome extension.
If you need more, you can upgrade to one of 6sense’s plans:
- Sales Intelligence + Data Credits + Predictive AI, which combines enriched company and contact data with predictive AI models and Sales Copilot for advanced, AI-driven selling.
- Sales Intelligence + Data Credits, which adds scalable data acquisition and enrichment tools, without predictive AI.
- Sales Intelligence + Predictive AI, which combines predictive analytics with Sales Copilot, without requiring data credit add-ons.

Pros & Cons
✅ Predictive scoring that prioritizes accounts well for large ABM motions.
✅ Website deanonymization plus multi-source third-party intent.
✅ Advertising and orchestration in one platform.
❌ Pricing is not public.
#10: Salespanel
Best for: SMB and mid-market marketers who care about buyer-journey attribution and first-party, cookieless tracking.
Similar to: Albacross, Leadfeeder.
Salespanel follows the full buyer journey across your site and scores leads with a mix of rules and AI, deanonymizing visits at the account level along the way.
Features
- Journey tracking: Follows touchpoints across forms, pages, chats, and email campaigns.
- Account reveal: Deanonymizes visiting companies from website traffic.
- Lead scoring: Combines rule-based and AI scoring to prioritize leads.
- Cookieless tracking: Uses first-party and server-side tracking that survives cookie loss.
Pricing
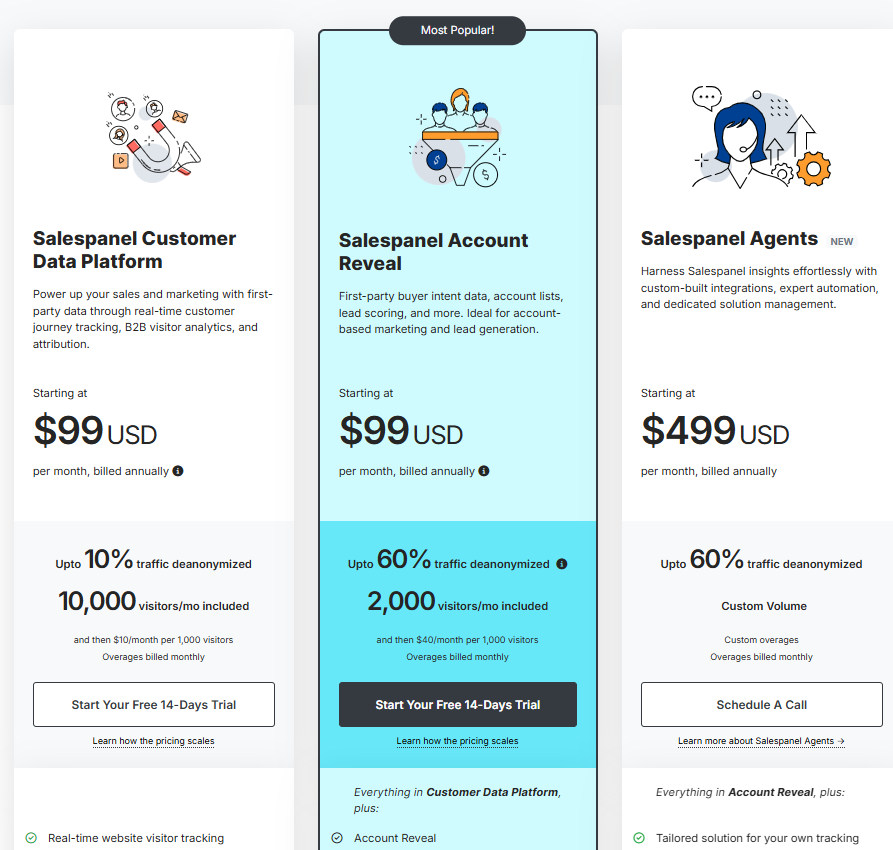
Salespanel splits into three plans billed annually, with the two entry tiers sharing a price but differing in what they reveal.
- Customer Data Platform: $99/month for up to 10,000 visitors with up to 10% deanonymized.
- Account Reveal: $99/month for up to 2,000 visitors with up to 60% deanonymized.
- Agents: $499/month for custom volume.
Pros & Cons
✅ Full buyer-journey tracking across domains and channels.
✅ First-party, cookieless, server-side tracking.
✅ Rule-based and AI lead scoring.
❌ Annual plans only.
Which alternative fits your team?
IPFingerprint does one job cleanly. If you mostly want to know which businesses are reading your site and which Google Ads phrases brought them there, it holds up, and the free trial makes it easy to test before you commit.
In terms of alternatives, many of the tools here stop at identification.
They'll tell you a company showed up, and a few will tell you which person, but almost none of them close the gap between spotting the visit and acting on it before the buyer clicks away.
Warmly is built to close that gap. It names the individual, engages them on-site with chat and live video, and follows up off-site with outbound, all reading off one intent model.
If your team has real traffic and you're tired of watching identified visitors go cold, Warmly's free plan is the low-risk way to see person-level identification on your own site.
And if your needs are lighter, one of the tools above will likely do the job for less.
You can start with Warmly's free plan to identify your first 500 visitors, or book a demo if your team needs the full Inbound and TAM agent setup.
⚠️ Disclaimer: This article was last updated on the 29th of July, 2026, and if there's any misinterpretation of the information, please contact us, and we will fact-check it.
![Visual Visitor Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a69b9fa762af138b5cb0c9a_Visual%20Visitor%20Pricing%20Is%20It%20Worth%20It.png)

![10 Best Visual Visitor Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a61c37a83ca9b05b07e1476_visual%20visitor%20alternatives.png)





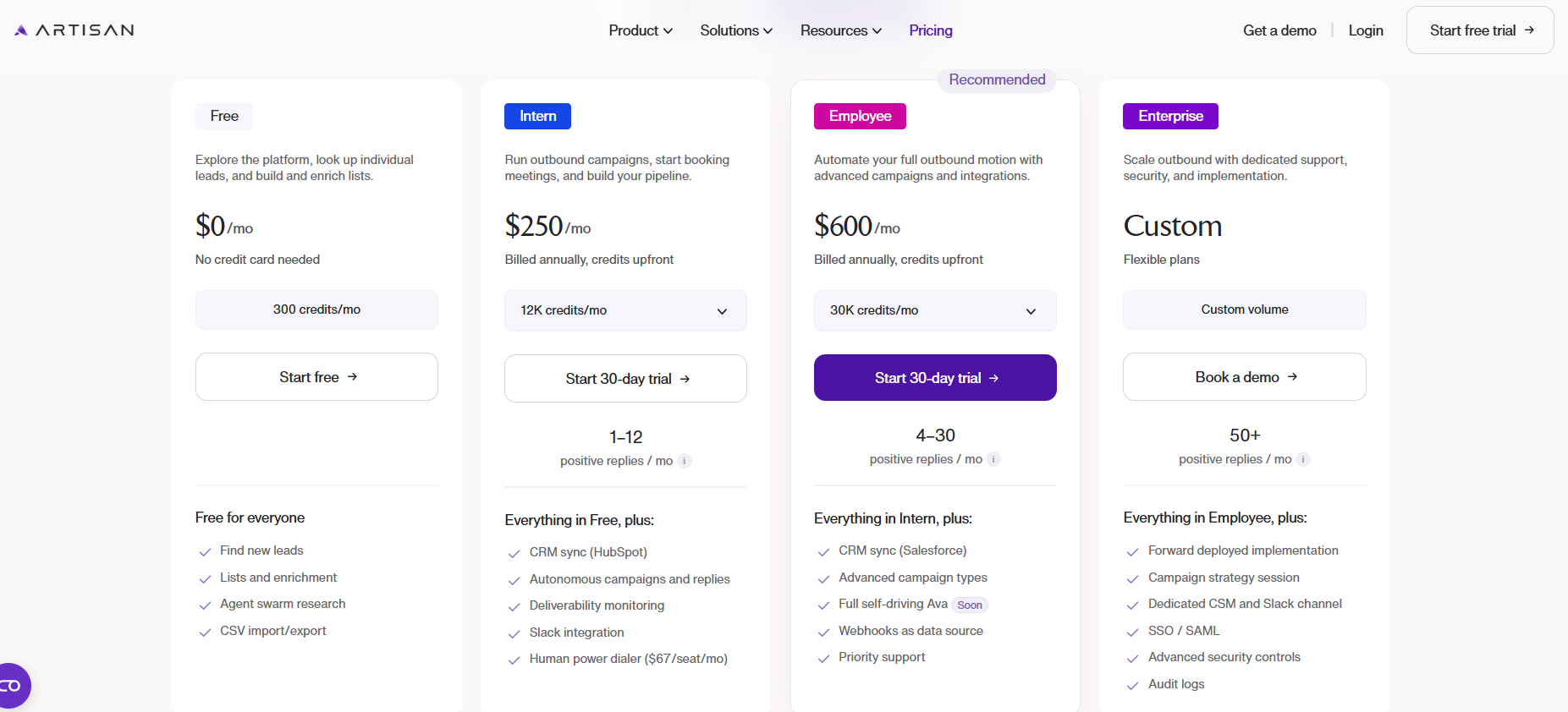
![Artisan AI Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a50d9d6673a4a522a93bce2_artisan%20ai%20pricing.png)

![10 Best Salesloft Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a50d85693a51868bfa50f01_salesloft%20alternatives.png)


![Swan AI Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a4613cc82de0944cc3f889d_swan%20ai%20pricing.png)

![10 Best Artisan AI Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a461258d8b098ce533f8b5f_artisan%20ai%20alternatives.png)


![10 Best Swan AI Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a418038ba577e5a48992a46_swan%20ai%20alternatives.png)
![Snitcher Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a416c8fdb39053fc92efbe9_snitcher%20pricing.png)



![Demandbase Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a353caddcd5ecf848e46ea7_demandbase%20pricing.png)