Why are we doing this
In many expert domains (for example law or medicine), the core world model is relatively stable and deeply codified. If you can gather the right evidence, the “correct” decision framework changes slowly.
Go-to-market is different: - the market shifts constantly, - buyer behavior changes by segment and quarter, - channel economics move quickly, - and small context changes can flip what the best next action should be.
That means the challenge is not only “answer correctly once.” The challenge is to continuously maintain the organization-specific world model and make good decisions as conditions move.
This harness exists to do exactly that: 1. build and maintain a living world model for each organization, 2. enforce safe, auditable decision execution, 3. learn from outcomes and human corrections, 4. compound decision quality as models and data improve.
This is the strategic moat: not just automation, but a continuously improving, organization-specific GTM decision system.
0) Comprehensive overview (all pieces together)
This is the full runtime + memory + governance map.
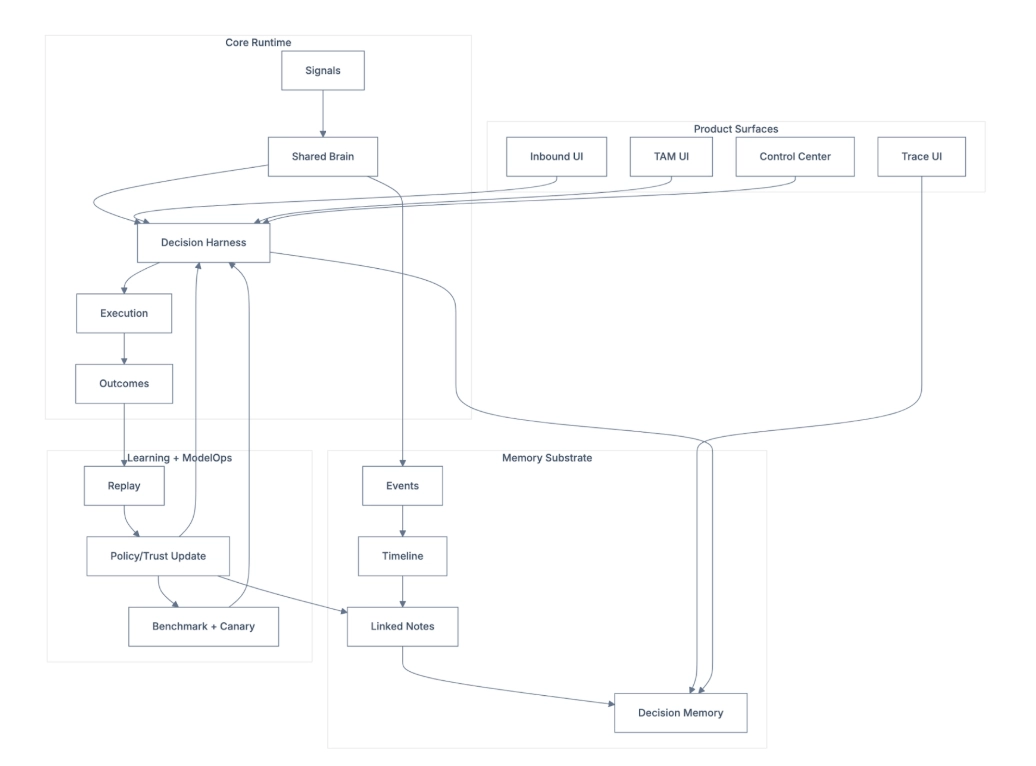
Comprehensive System Overview
What this means in one sentence
Signals come in, the system decides whether to act, acts safely through guardrails, measures outcomes, and learns back into a shared GTM brain.
1) End-to-end operating loop
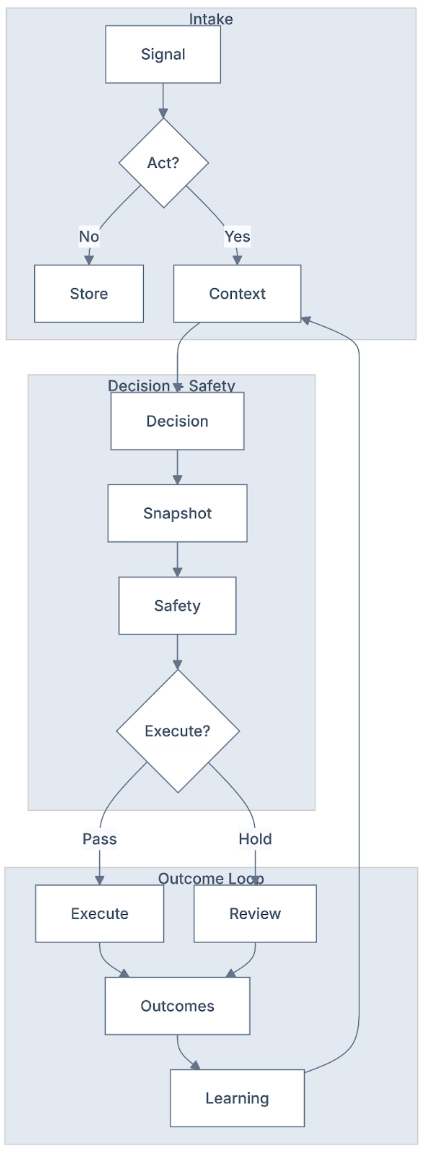
Signal to Trusted Action
Every signal follows the same loop:
- Signal intake A trigger arrives: web behavior, chat, CRM update, intent surge, or scheduled run.
- Action triage The first decision is: act now, later, or not at all.
- Context retrieval If action is needed, the system pulls relevant context from shared memory.
- Decision boundary The system chooses a candidate next action.
- Safety gate Trust, policy, cooldown, duplicate checks, and ownership controls decide pass/hold.
- Execution or hold If pass, actions execute. If hold, actions are queued for review/reschedule.
- Outcome writeback Replies, meetings, and downstream business results are attached to the decision.
- Learning writeback Future decisions improve from what actually worked.
2) Shared GTM brain: memory and context substrate
The shared brain is the cross-lane source of truth for marketing, inbound, TAM, and operators.
Memory layers
- L0 Raw Event Ledger
- Ground truth of what happened and when.
- Supports replay, audit, and forensic analysis.
- L1 Timeline + Episodic Memory
- Fast summaries for low-latency runtime decisions.
- Lets agents respond quickly without loading full history.
- L2 Zettelkasten Linked Notes
- Connected facts, evidence, hypotheses, objections, and conclusions.
- Enables progressive context walk only when deeper context is needed.
- L3 Decision + Policy Memory
- Stores what decision was made and which policy state existed at that time.
- Critical for hindsight: “given what we knew then, was that the best decision?”
- L4 Outcome-Linked Knowledge
- Connects outcomes back to decisions.
- Creates a closed learning loop from action to result.
Important principle: snapshot at decision time, not every signal
The system does not take heavy snapshots for every incoming signal. It snapshots the world model at decision boundaries.
Why this is better:
- lower cost,
- cleaner audit trail,
- better replay quality,
- and clearer responsibility for each action.
3) Concurrency, trust, and execution safety
Safety here is mechanical, not “hope the prompt behaves.”
A) Ownership lock (traffic-cop)
Only one active owner can control a target entity during a decision window.
Business outcome:
- prevents contradictory actions,
- prevents sends from parallel lanes,
- keeps sequencing deterministic.
B) Cooldown + duplicate suppression
Before execution, the system checks whether recent actions already happened on that account/contact.
Business outcome:
- avoids overo-contact,
- protects brand trust
- reduces wasted budget.
C) Trust gate (fail-closed)
High-risk actions only pass when policy + trust + authorization criteria are met.
Business outcome:
- unsafe actions do not silently execute,
- low-confidence actions route to review,
- autonomy increases only when evidence supports it.
D) Trust gate observability + human-in-the-loop (where you see it)
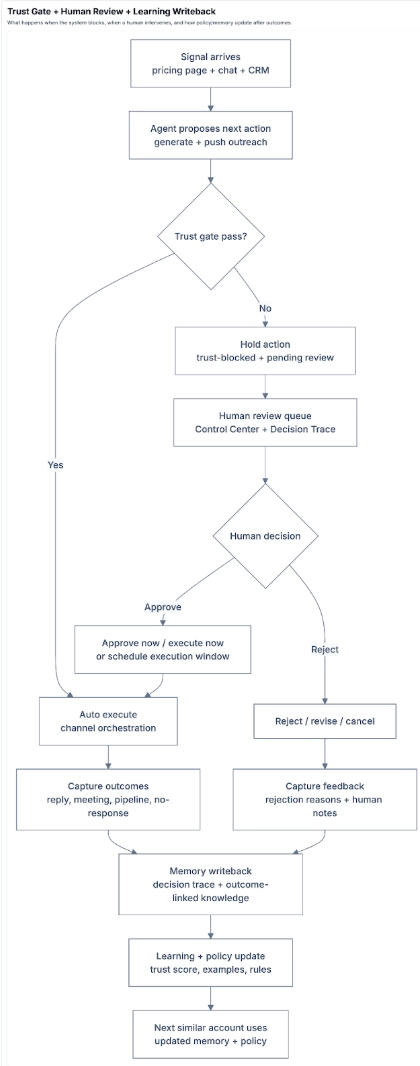
Trust Gate, Human Review, and Learning Writeback
Trust-gate activity is visible in four operator views:
- Trust-blocked review queue Shows actions that were held because trust was below threshold.
- Scheduled actions queue Shows actions that passed trust but were delayed in a review window (with countdown).
- Decision Trace UI Shows pass/hold/scheduled reason, trust score at decision time, and action outcome.
- Control Center trust panel Shows trust levels by action type (email generation, outreach push, paid audience push) and trend over time.
How trust gets updated (plain language)
Trust is updated from what humans do and what outcomes happen:
- Human review signals
- repeated approvals increase trust,
- repeated rejections decrease trust.
- Execution outcomes
- positive outcomes (reply, meeting booked) raise trust more,
- negative outcomes (bounce, no response at scale) reduce trust.
- Pattern learning Repeated human corrections create policy patterns (for example, “skip this domain class” or “reconsider this persona class”).
End-to-end example: blocked outreach -> human approval -> policy update
Scenario: A target account visits pricing, chat reveals urgency, agent drafts a 3-step outreach sequence.
- Agent proposes execution for outreach.
- Trust gate evaluates and holds execution (score below threshold).
- Batch enters human review queue with full rationale.
- Human edits one message, approves two contacts, rejects one contact.
- Approved actions execute; rejected path is canceled.
- Decision Trace records:
- original decision,
- trust-gate reason,
- human override,
- final execution outcome.
- Outcomes arrive (reply + one meeting booked).
- Learning writeback updates:
- trust score for similar action type,
- reusable examples from approved/performing messages,
- policy hints from rejection reasons.
- Next similar account starts with improved defaults and less review friction.
4) Inbound + TAM as one coordinated system
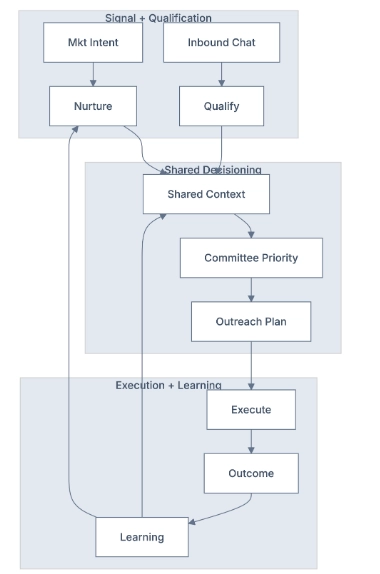
Sales and Marketing Journey
Inbound and TAM are separate lanes, but they run on one shared memory substrate.
Why this matters for executives
Without a shared brain, teams optimize locally and conflict globally. With a shared brain, all lanes learn from the same outcomes.
Practical journey
- Marketing captures high-intent activity.
- Inbound agent qualifies and captures objections.
- Shared account context updates instantly.
- TAM chooses next best committee actions using updated context.
- Safety-gated execution runs only eligible actions.
- Outcomes write back to the same account memory.
- Future inbound and TAM behavior both improve from that result.
5) Canary Model Rollout
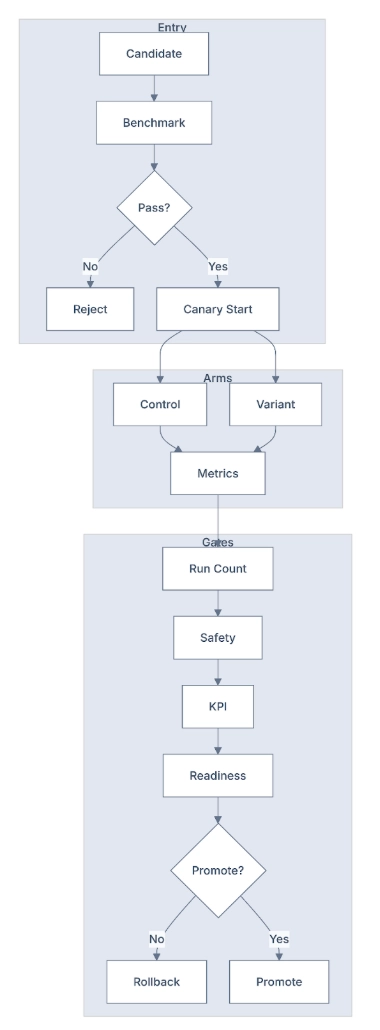
Canary Model Upgrade Example
What it is
A canary model rollout is a controlled live test lane for model or policy upgrades before full rollout.
Why it exists
A model can look better in a demo but still hurt production quality. Canary rollout prevents that.
When it is used
Any time the decision engine changes in a meaningful way:
- model version change,
- prompt/policy logic update,
- tool-routing behavior change,
- risk-threshold adjustment.
How it works in plain terms
- Create candidate New model/prompt configuration is prepared.
- Golden dataset baseline check Candidate must pass offline checks against known-correct labeled examples.
- Split live traffic Small live slice is split between current system (control) and new system (variant).
- Compare both sides Evaluate quality, safety, and business metrics side-by-side.
- Gate decision
- If variant is better or safely equivalent -> promote.
- If variant regresses safety or business outcomes -> hold/rollback.
Golden Dataset (What It Is, in Plain Language)
Golden dataset = a hand-validated set of examples where we know the correct answer with high confidence.
For GTM, this includes: - whether the company truly matches ICP criteria, - whether a title maps to the correct buying persona, - whether a detected behavior is a real intent signal (not noise), - whether the recommended action is policy-safe for that context.
It is the baseline contract the model must satisfy before touching live traffic.
Marketing example: web scrape -> labeling -> canary
Scenario: A prospect account is scraped from website + social + CRM context. The system must decide if this should enter a high-priority outbound motion.
Golden dataset labels (known-correct examples):
- Company type label Example: “B2B SaaS, 200-1000 employees, North America” = ICP Tier 1.
- Persona label Example: “Director of Revenue Operations” = Approver persona for this play.
- Signal label Example: “Visited pricing + compared competitor page in same session” = high-intent signal.
- Action label Example: “Generate personalized outreach + suppress paid retargeting for 48h” = correct first action.
How the rollout works:
- New model is scored on this golden dataset first.
- If it misses critical labels (ICP/persona/signal/action), it does not proceed.
- If it passes, it enters canary on a small live slice.
- Live metrics then validate real-world behavior (reply rate, trust blocks, duplicates, meeting quality, spend efficiency).
- Only after both baseline correctness and live safety/KPI pass does full rollout happen.
End-to-end marketing example
- You launch a new “pricing-page follow-up” messaging model.
- 10% of eligible traffic enters the upgrade test.
- Half uses current messaging (control), half uses new messaging (canary variant).
- Over a fixed window, compare:
- reply quality,
- meeting creation,
- trust-block rates,
- duplicate/cooldown incidents,
- spend per useful outcome.
- Result:
- if variant increases meetings without safety regressions, promote to broader traffic.
- if variant improves replies but causes higher trust blocks, keep it in test and revise.
This lets leadership move fast on model gains without risking production quality.
6) Learning system
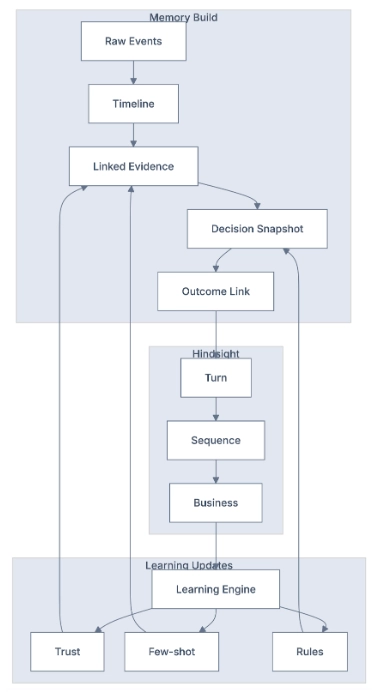
Learning System
What it is
Learning is the mechanism that turns outcomes into better future decisions.
The three learning levels
- Turn-level Was each individual message/action good and policy-safe?
- Sequence-level Was the ordering/timing/channel mix good across multiple steps?
- Business-level Did this path create meetings, pipeline, and revenue efficiently?
End-to-end marketing example
Scenario: a target account visited pricing, then engaged chat, then entered nurture + TAM outreach.
- Turn level The first follow-up email gets a reply but low sentiment score. System marks that pattern as partially effective.
- Sequence level Analysis shows better outcomes when chat follow-up happens before paid retargeting, not after. System updates sequencing preference.
- Business level Two sequence variants are compared:
- Variant A: lower reply rate but higher meeting-to-pipeline conversion.
- Variant B: higher reply rate but weak downstream conversion. System prioritizes Variant A for similar accounts.
- Policy/trust update High-performing patterns are promoted. Poor patterns are deprioritized or blocked for similar contexts.
- Next cycle Future campaigns start with improved sequence defaults automatically.
Net effect: the system compounds commercial quality over time instead of repeating mediocre playbooks.
7) Budget and token optimization (operating model)
This harness is not only an accuracy system; it is also a cost-optimization system.
What is being optimized
- token spend,
- tool-call spend,
- channel spend,
- human review time,
- cost per qualified outcome,
- cost per meeting/pipeline dollar.
How optimization works
- Progressive disclosure for context Start with fast/cheap memory, go deeper only when needed.
- Action gating Don’t execute expensive actions when trust/safety is insufficient.
- Canary economics checks Promotion requires not just quality safety, but healthy cost efficiency.
- Outcome-weighted budget allocation Budget shifts toward sequences/channels with stronger downstream conversion, not vanity engagement.
- Visibility loop in UI Operators can see spend, decisions, and outcomes in one place and adjust thresholds/policies.
Executive view
This turns GTM automation into a measurable optimization function: maximize qualified business outcomes under safety and budget constraints.
8) Visibility and control (not a black box)
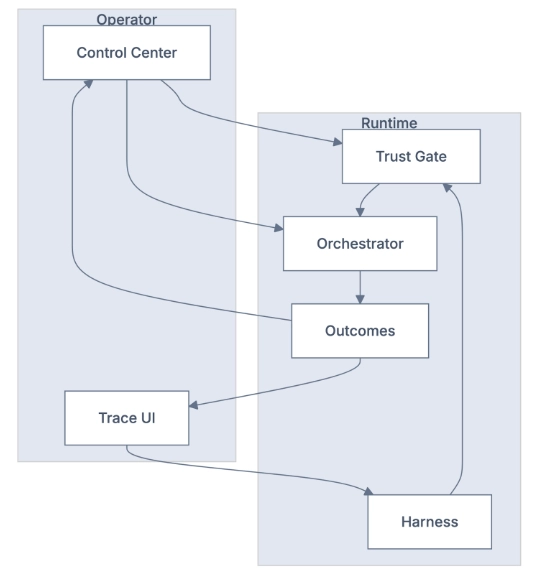
UI Control Plane and Runtime
A core design principle: agent behavior must be inspectable and controllable.
Control Center UI gives
- policy and trust controls,
- autonomy/approval settings,
- experiment + upgrade-test status,
- safety + budget dashboards,
- rollout controls.
Decision Trace UI gives
- what action was selected,
- why it was selected,
- what evidence/context was used,
- what policy state applied,
- what happened after execution.
9) Extensibility layer: API + MCP tool surface
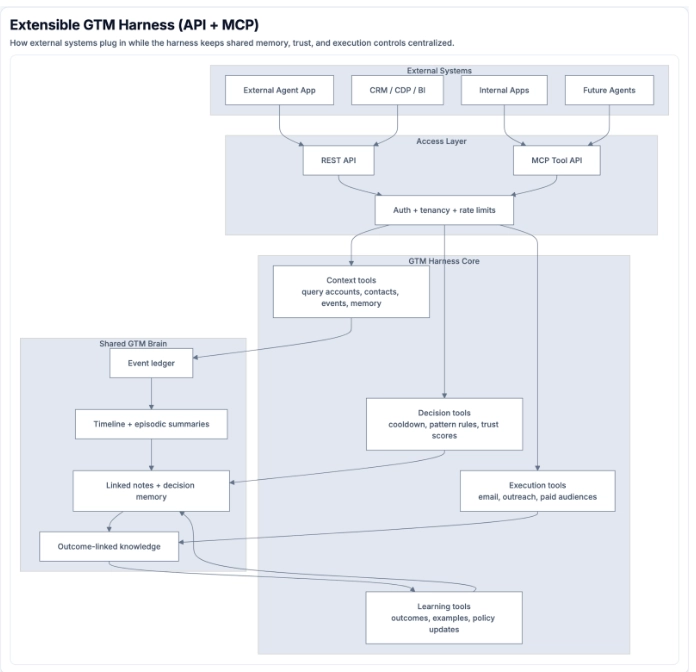
Extensible GTM Harness API + MCP Layer
The harness is designed to be an extensible GTM runtime, not a closed app.
Think of it as a GTM-specialized agent platform: - broad action capability like a general agent runtime, - constrained by GTM-specific trust, policy, and execution controls.
How external systems connect
External systems (internal copilots, workflow engines, CRM apps, and other agent systems) connect through:
- REST API For operational workflows, dashboards, approvals, and reporting.
- MCP tool API For agent-native tool calling from chat/assistant environments.
Both routes converge into the same harness core, so behavior stays consistent and auditable.
Tool-call categories the harness exposes
- Context + retrieval tools Examples: queryaccounts, getaccount_detail, get_account_contacts, get_account_events, get_account_memory, run_sync.
- Decision + safety tools Examples: logdecision, querydecisions, check_cooldown, get_pattern_rules, get_trust_scores, get_score_breakdown.
- Execution tools Examples: generateemailbatch, pushoutreach, pushlinkedin_audience, push_meta_audience, push_youtube_audience.
- Research + knowledge tools Examples: web_search, find_similar_companies, search_documents, analyze_transcript, get_recent_outcomes.
- Policy + settings tools Examples: updateicptier_rules, reclassify_icp_tiers, update_persona_rules, reclassify_personas, blacklist_domain.
Why this matters for enterprise stack integration
- External systems can orchestrate user-facing workflows while this harness remains the governed decision + memory backend.
- New channels and actions can be added as tools without redesigning the whole system.
- Every external integration inherits the same trust gates, traceability, and learning loops.
10) Practical rollout path
Phase 1: Instrumented control
- Connect core signal sources.
- Turn on traceability + trust gates.
- Keep autonomy narrow until observability is stable.
Phase 2: Unified learning
- Run inbound + TAM on the same memory substrate.
- Attach outcomes to decisions consistently.
- Activate turn/sequence/business learning loops.
Phase 3: Scaled autonomy
- Use canary model rollout for all major model/policy changes.
- Expand autonomous scope only where quality + safety + economics pass.
11) Final framing
This is not a chatbot layer. It is a governed GTM decision system.
The strategic value is:
- one shared world model,
- safe and auditable execution,
- continuous outcome-linked improvement,
- and explicit budget optimization at scale.
That is what creates durable compounding advantage for enterprise GTM operations.
Last Updated: March 2026