The day a sales team killed marketing's email program
Last week I jumped on a call with a head of marketing at a mid-market B2B company. Smart guy. New in seat. Walked into a brand he respects and a sales team that hates him.
He told me what happened. He sent a couple of campaigns. Targeted, thoughtful, on-brand. Marketing-led. The kind of campaign you write a deck about. Sales got the alert. Sales lost their minds. It escalated to the CRO. The CRO turned it off.
"No more emails. Like, you're not allowed to send emails out. We need to have a postmortem on this."
He's still in seat. He still has a number. He still has a CMO who needs marketing-sourced pipeline. He just can't send the thing marketing has used to generate pipeline for the last fifteen years.
I asked him what happened with the previous administration. He didn't know all the details. But what he pieced together was that the old team had sent emails to the wrong people. People sales was already talking to. People sales didn't want to talk to. People who weren't in the database for a reason. Sales got burned. Then they got PTSD. Then the second they saw a marketing email this quarter, the whole organism flinched.
This story is not rare. I hear a version of it almost every week now. And here's what I want every demand gen leader and head of marketing reading this to understand:
Sales was right. Not because marketing should never email. Because marketing as a function has been doing the wrong thing for years, and AI is making the wrong thing infinitely worse.
The good news is the right thing is more powerful than the old wrong thing. The right thing is what got our team from one million in pipeline in February to three point two million in pipeline in March, with a smaller team and a smaller ad budget than we'd ever run.
This post is the playbook for how to actually do it. Step by step. With the tools we use, the gotchas we hit, and the parts that still hurt.
If you read The Gospel of Gravity, this is the operating procedure for the worldview it lays out. If you haven't, you don't need to. The tactics work either way. The worldview just makes them make sense.
If you're a head of marketing or running demand gen and your sales team is one bad campaign away from telling you to shut it all down, this is for you.
Why this is happening to every marketer right now
A few things broke at the same time and the combination is what's killing marketing programs right now.
Start with inbox infrastructure. Google and Microsoft have spent the last two years getting ruthless about deliverability. Cold email volume from B2B SaaS exploded after ChatGPT shipped. Every founder with a laptop figured out they could generate ten thousand "personalized" emails in an afternoon. So Google tightened the screws. Open rates dropped. Spam folder routing got more aggressive. A domain that was healthy in 2023 is in a Google Workspace penalty box in 2026 if you haven't been careful with it.
Then there's the buyer. The average decision maker in your ICP gets somewhere between 30 and 100 cold emails a day. They get LinkedIn DMs from fake profiles. They get bot calls. Their tolerance for unsolicited generic outreach is zero. Their tolerance for unsolicited specific outreach is maybe four seconds. If your email looks like the other 99 in their inbox that day, you're invisible.
And then there's the political reality inside the company. Sales teams have always been a little suspicious of marketing emails. Now they're past suspicious. They're scared. They've seen what bad AI-generated outreach does to a brand. They've heard the horror stories from peer companies. They have customer-facing reputations on the line. So the second marketing tries to send anything that even smells like automation, sales has a CRO-level escalation queued up before you've finished saying "campaign."
You can rage against this. Plenty of marketers do. They tell me "but we can't hit our number without volume." They're right. They also still can't send the emails. The political ground has shifted and yelling about it doesn't unshift it.
All three of those breaks are downstream of the same shift. The wand got into every hand at the same time. Every marketer has the same AI copywriter, the same sequencer, the same playbooks. Volume stopped being a moat the moment volume became a button. What's left is the part the wand can't conjure. A following that trusts you. A worldview the model recommends when buyers ask. A field strong enough that matter you spent money on doesn't drift back out.
So what do you do?
You stop trying to convert people who don't know who you are. You build a following that wants to hear from you. And you use the wand to do the boring infrastructure work underneath.
Marketing's new job is two things at once
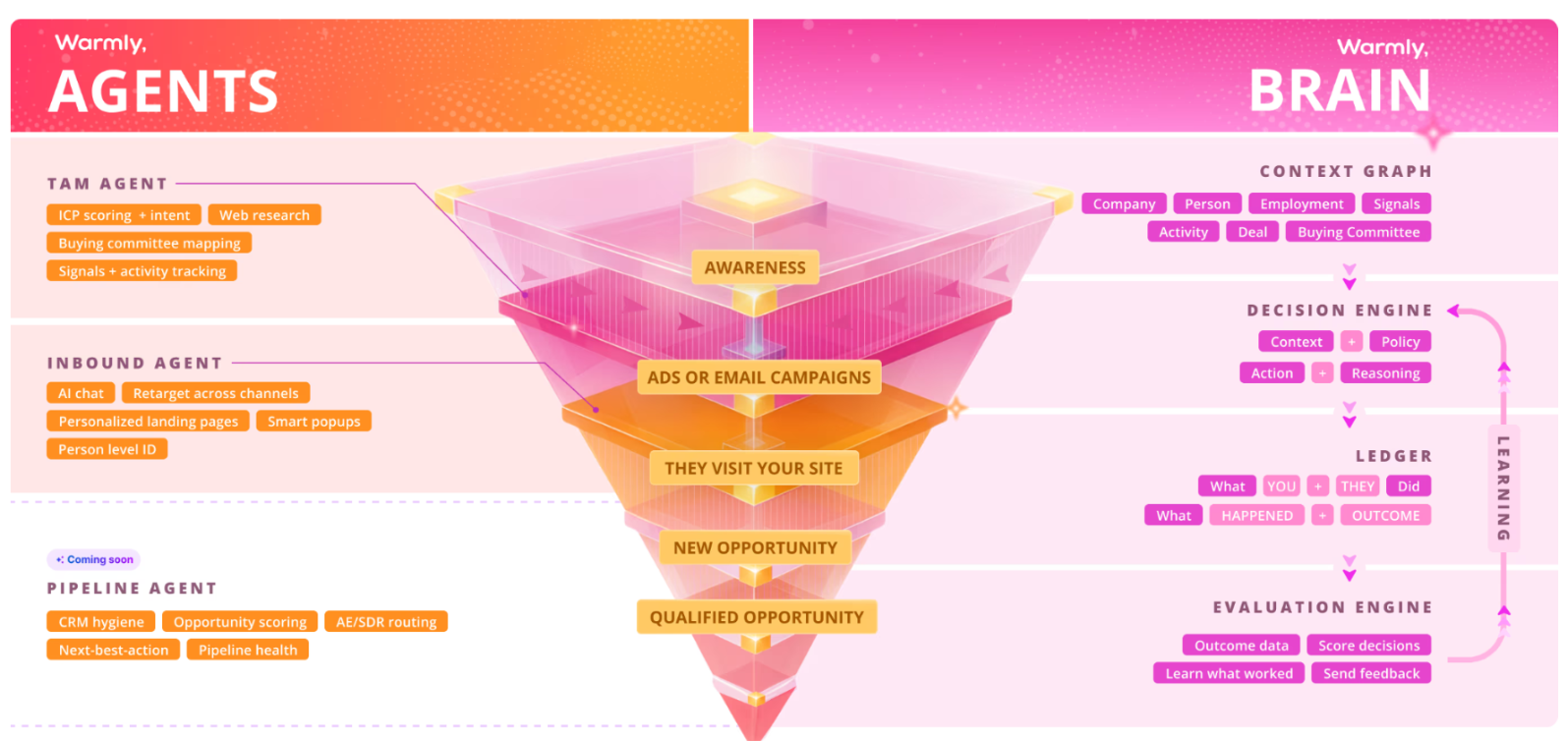
The job is push and capture.
Push as many of the right people as you can through your orbit. Drive the traffic. Spend the ad dollar. Publish the post. Run the podcast. Show up in the AI search result.
Capture as many of them as you can once they're there, and keep them. Not just the ones in a buying cycle this quarter. Everyone. The follower who will be in market eighteen months from now, who has been reading your stuff in the background the whole time, is the actual prize. Most marketing teams ignore her because she does not show up cleanly in the quarterly attribution report. She is the one who buys.
If you only push, the matter passes through your orbit and out the other side. You spent money. You did not collect anyone. If you only capture, you starve, because there is no new matter to keep. Both halves are the work. Together they produce gravity.
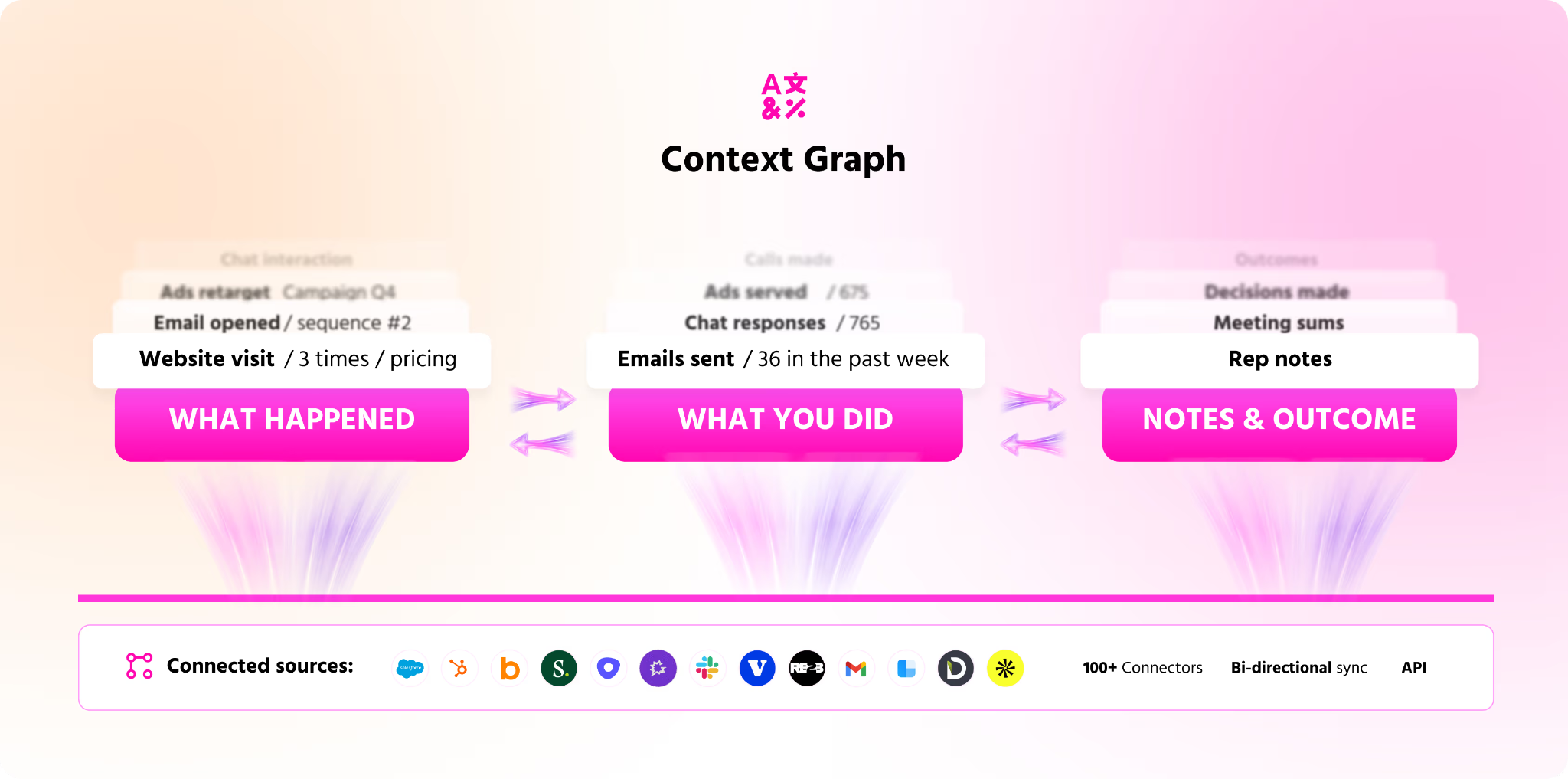
The math that makes this real: you probably spend fifty thousand a month on ads. Maybe more, maybe less. Your ad clicks convert at 1 to 2 percent if you are average and 6 to 8 percent if you are really good. Of the people who click through and never fill out a form, you used to know nothing. Now, with the right stack, you can identify who they are, what company they work for, what page they were on, and how interested they really are. Those are your followers in waiting. You spent money to get them into your field. You don't get to lose them.
When I explained this to the head of marketing whose email program got shut down, he had a moment. He said, "wait, so we can identify people who are hitting the site and bouncing?" Yes. And once you can do that, the conversation about whether you can send emails changes entirely. You are not blasting cold prospects. You are recognizing warm visitors who already showed up.
The playbook below is not "how to send better cold emails." It is how to push the right matter through your orbit, capture it when it gets there, and keep it orbiting long enough that the next time the buying need comes around, you are the obvious answer.
The push: build the field
Steps 1 through 4 are about getting more of the right matter into your orbit. The website, the list, the infrastructure, the ads. The work that puts you in front of people who do not yet know you exist.
Step 1: Make yourself findable (build the dark matter)
Before you do anything else, your website has to be a thing that AI understands.
I'm not talking about traditional SEO. Traditional SEO still matters, but it's table stakes. The thing that's changed in the last 18 months is that one in nine of our inbound demos now comes from ChatGPT, Claude, or Perplexity. People aren't typing things into Google anymore. They're typing them into an AI. The AI is making a recommendation. You either show up in that recommendation or you don't exist.
The way you show up is to make your website the most complete, structured, factually dense knowledge base on what you do that exists on the internet.
Concretely, this means:
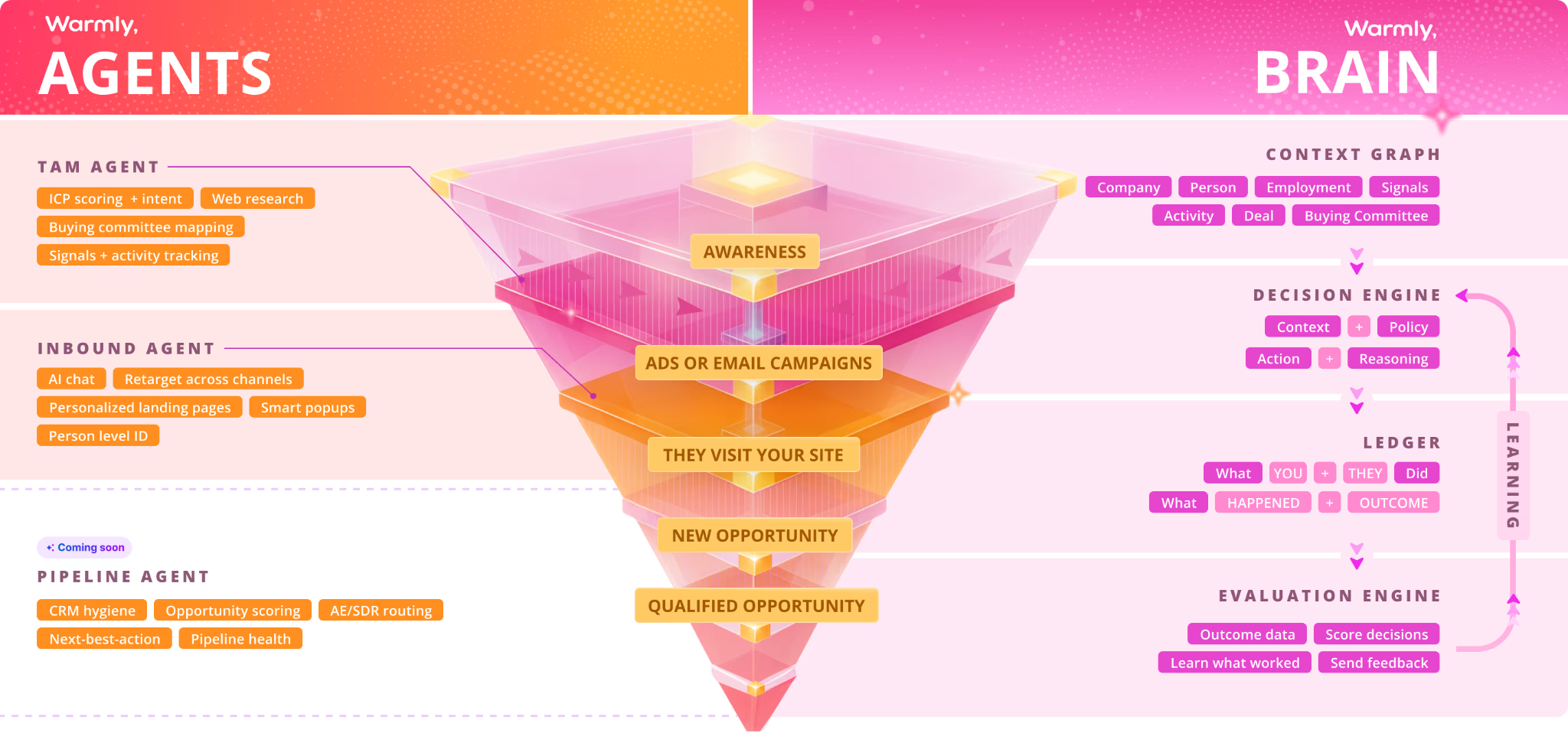
One page per concept your product does. If you have an AI agent that handles inbound, you need a page called Inbound Agent. If you have a TAM tool, you need a page called TAM Agent. If you have a context graph, you need a page called Context Graph. Every distinct capability gets its own page, with its own URL, its own structured data, its own crisp explanation of what it does and why it matters.
Link them all from the home nav. Every click away from your home page is a signal to Google that the page matters less. If your most important capability is three clicks deep, Google thinks it's a footnote. Put the important stuff one click away.
Answer the question in the first 500 words. AI scrapers are looking for the answer. They don't want to wade through five paragraphs of brand storytelling. State what the thing is. State what it does. State who it's for. Then go deeper.
Don't write off-topic blog posts. This one is going to sting if you have a content team that loves to write thought leadership about adjacent topics. Google's algorithm changed in 2025 and now penalizes domains for writing about things that aren't their core business. If you're a CRM company and you publish a blog post about Kubernetes, Google docks that post and docks your domain authority on every other post. You're not a generalist publisher. You're a domain expert. Act like one.
Use structured data. JSON-LD, schema markup, OpenGraph tags. Boring infrastructure. Required infrastructure. AI scrapers love it.
Strip the JavaScript-only content. A lot of modern sites render everything in JavaScript. Crawlers can't always execute JavaScript. So your content disappears. If your hero section, your value props, or your testimonials only exist after a JavaScript bundle loads, you're invisible to half the crawlers.
For our team, the unlock was treating the website not as a marketing asset but as the canonical source of truth for what Warmly is and does. The knowledge doesn't live in my head. It doesn't live in Keegan's head. It lives in the website. Anyone, human or AI, who wants to understand what we do reads the site and gets the full picture.
To build this, we use Claude Code (Anthropic's terminal coding tool) plus our designer. I'll tell you exactly how this works in Step 8. For now just know that you can build, edit, and maintain a 100-page knowledge base site with a designer and a marketing leader. You don't need a content team of ten.
I'm not really a marketer. I was an engineer for ten years before this job. We rebuilt the website twice and watched our blog traffic crater for six months after a Google update before we figured out the AEO and GEO part. So when I tell you to do this, it's because we burned the time to learn it the wrong way first.
Step 2: Build the list (choose the audience your religion is for)
Most marketing efforts die at the list.
Either the list is too broad (everyone in your CRM, plus every cold lead you can buy, plus everyone who downloaded a whitepaper in 2021) or the list is too narrow (the 50 logos your CRO wants closed this quarter).
Neither works. Too broad and your engagement rates crater, your domains burn, and sales doesn't trust the lead routing. Too narrow and you can't generate enough surface area to fill the pipeline.
What works is the middle: a tight, current, multi-source TAM list of companies that match your ICP, with the buying committee mapped at each one, refreshed continuously.
Here's how we build it.
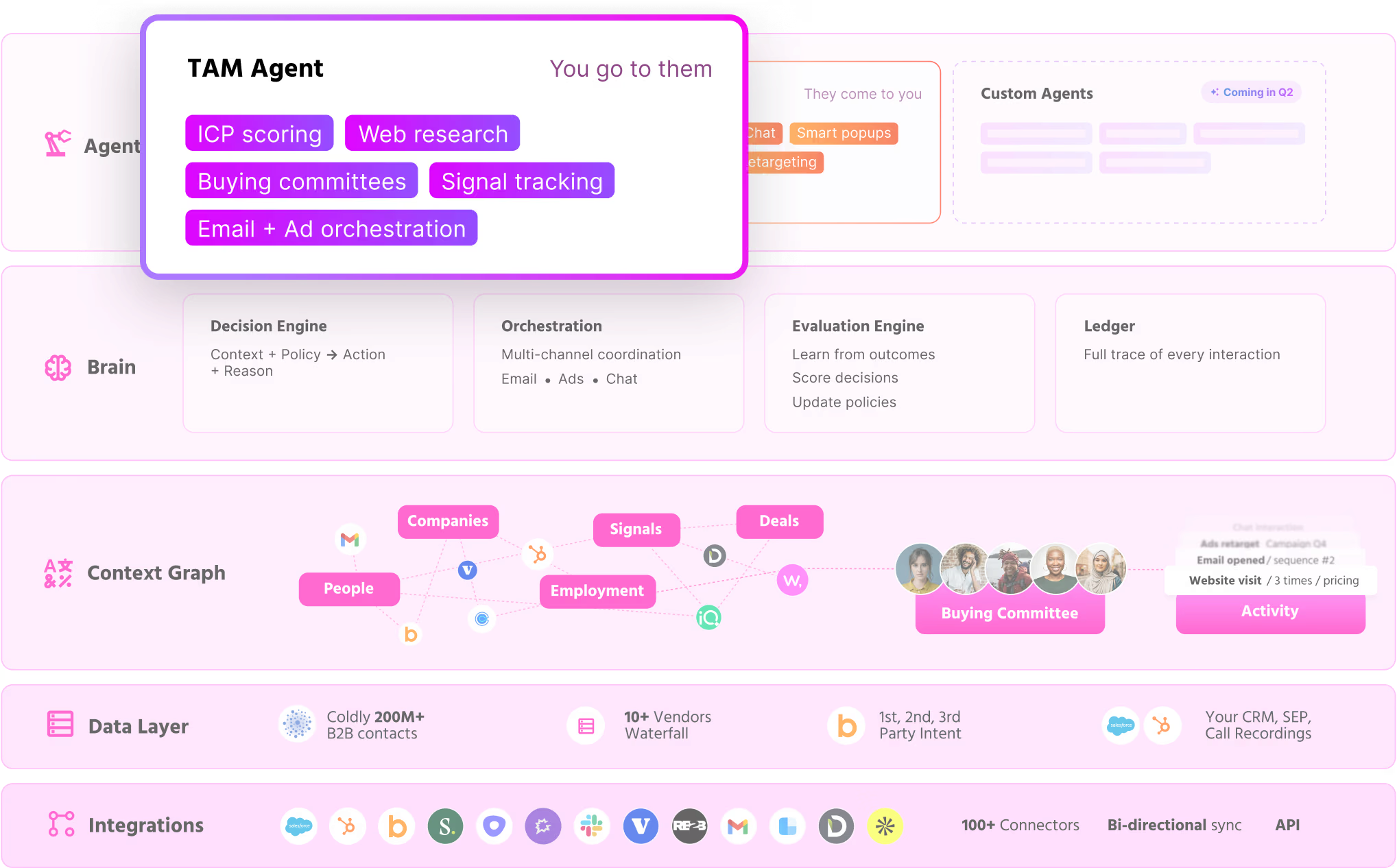
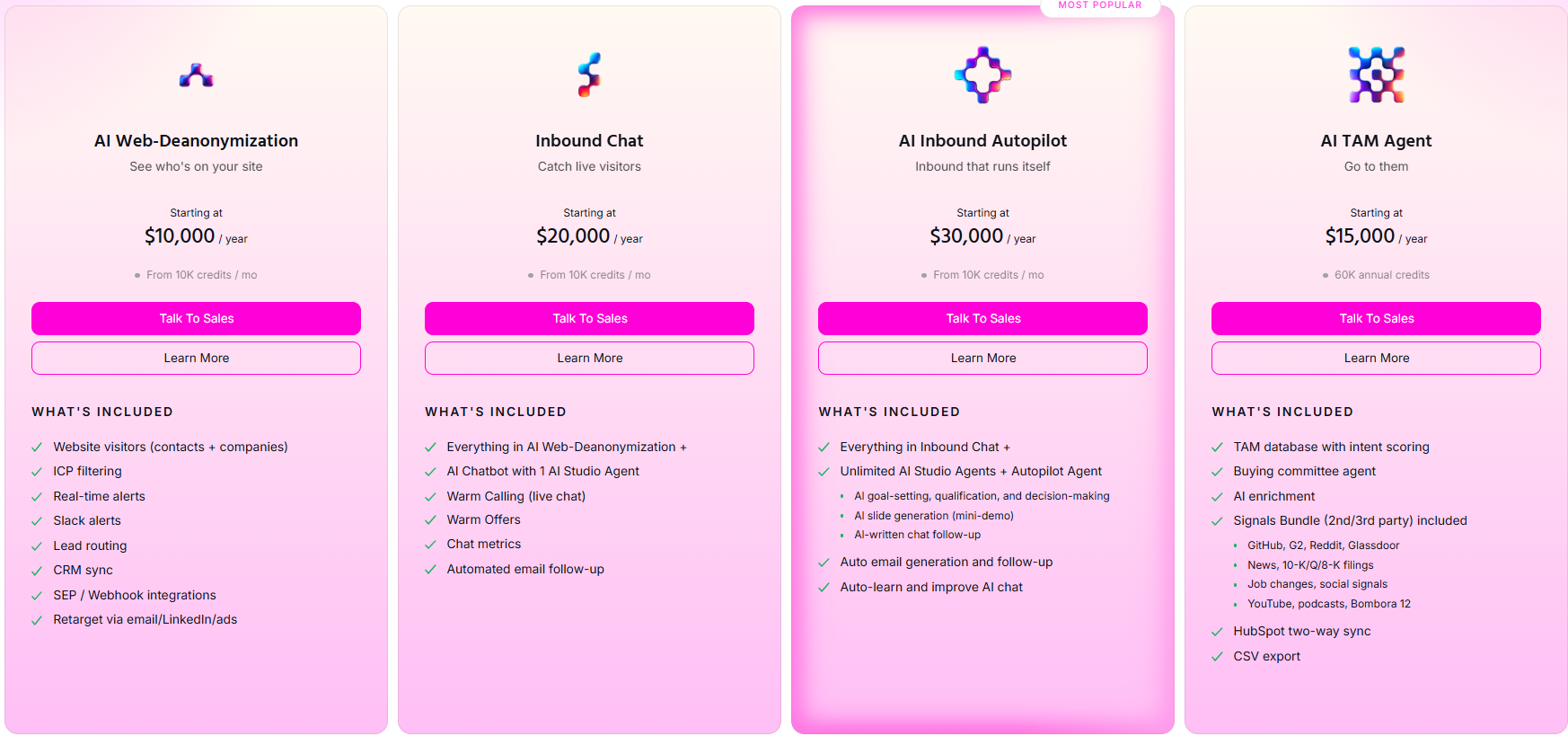
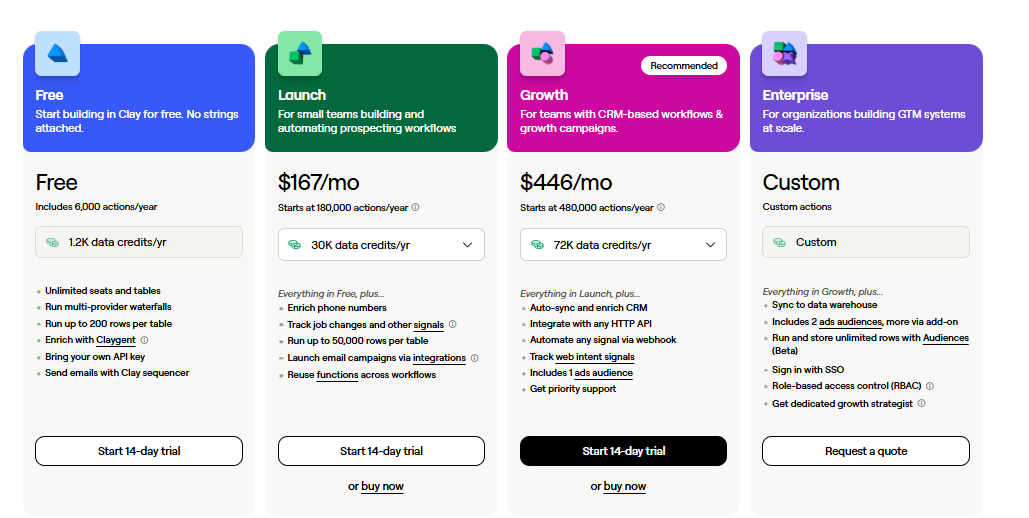
Source 1: Firmographic TAM. We use ZoomInfo or Apollo (or our own TAM Agent if you're a Warmly customer) to pull a list of every company in our addressable market based on size, vertical, location, tech stack, hiring patterns. This is your baseline. For us it's roughly 30,000 companies. For you it might be 5,000 or 80,000.
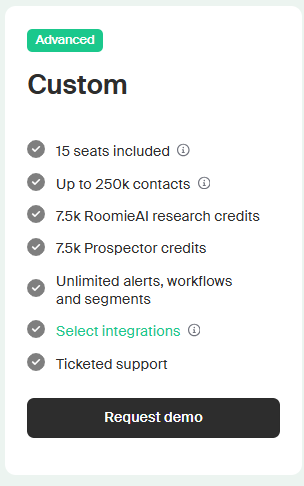
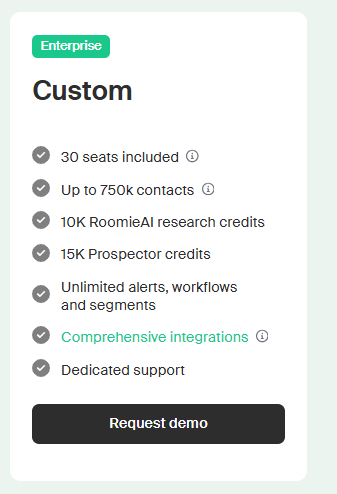
Source 2: Intent signals. We layer on intent: who's researching topics related to what we sell, who's hiring for roles that signal a buying motion, who's installed competitive tools, who's posted about a relevant problem. Tools like Bombora, BuiltWith, PublicWWW, Common Room, G2, and (yes) Warmly all do parts of this. The point isn't which tool. The point is you need a way to know which 5% of your TAM is actively in market right now.
Source 3: Behavioral signals. Who visited your site. Who opened your last newsletter. Who engaged with a LinkedIn post. Who showed up at a webinar. Who's already in your CRM as a dormant lead. Your existing audience is a goldmine and most marketers ignore it.
You cross-reference all three sources. The companies that show up in two or three of the three are your top tier. The ones that show up in one are your second tier. The ones in zero are your cold backlog.
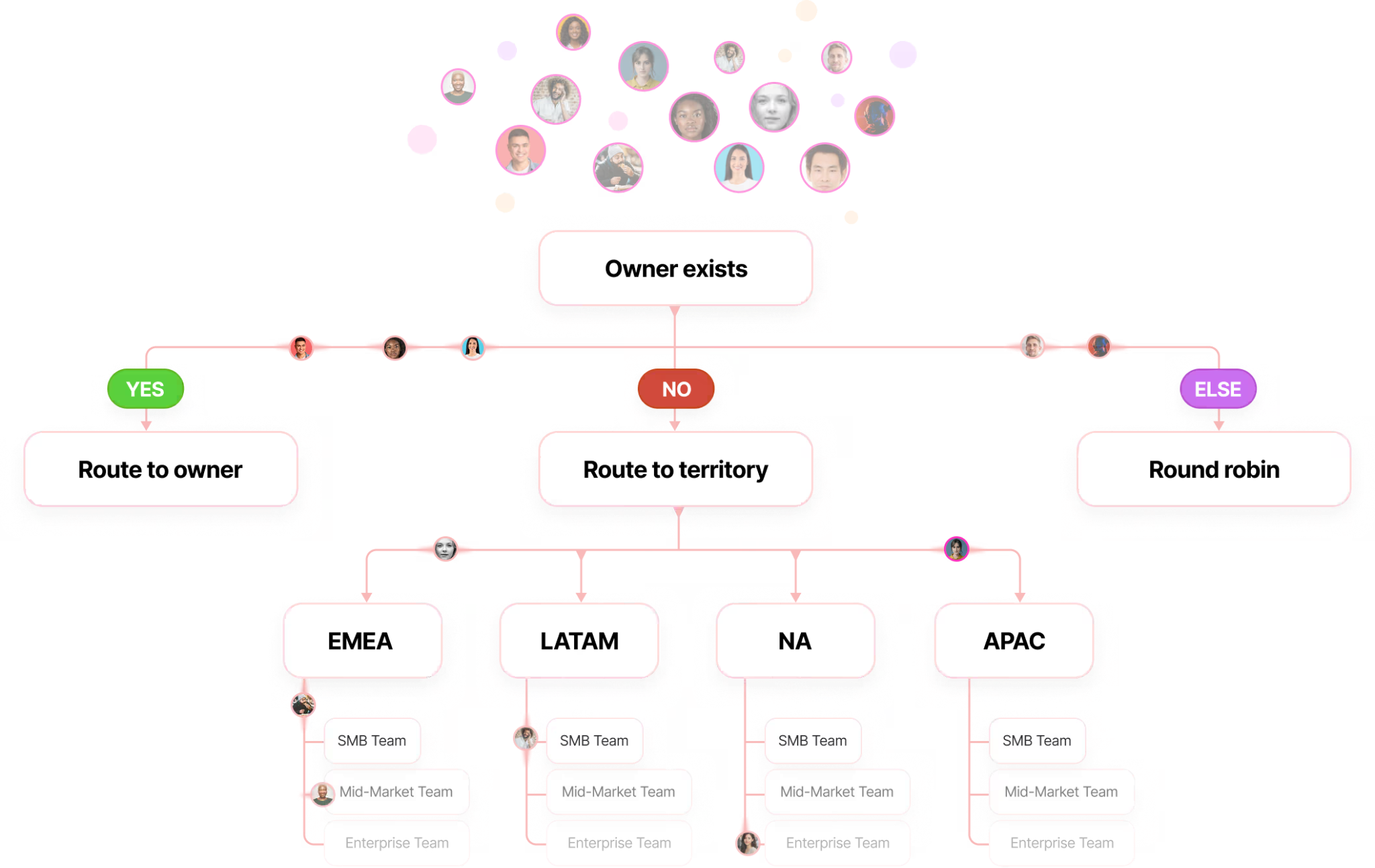
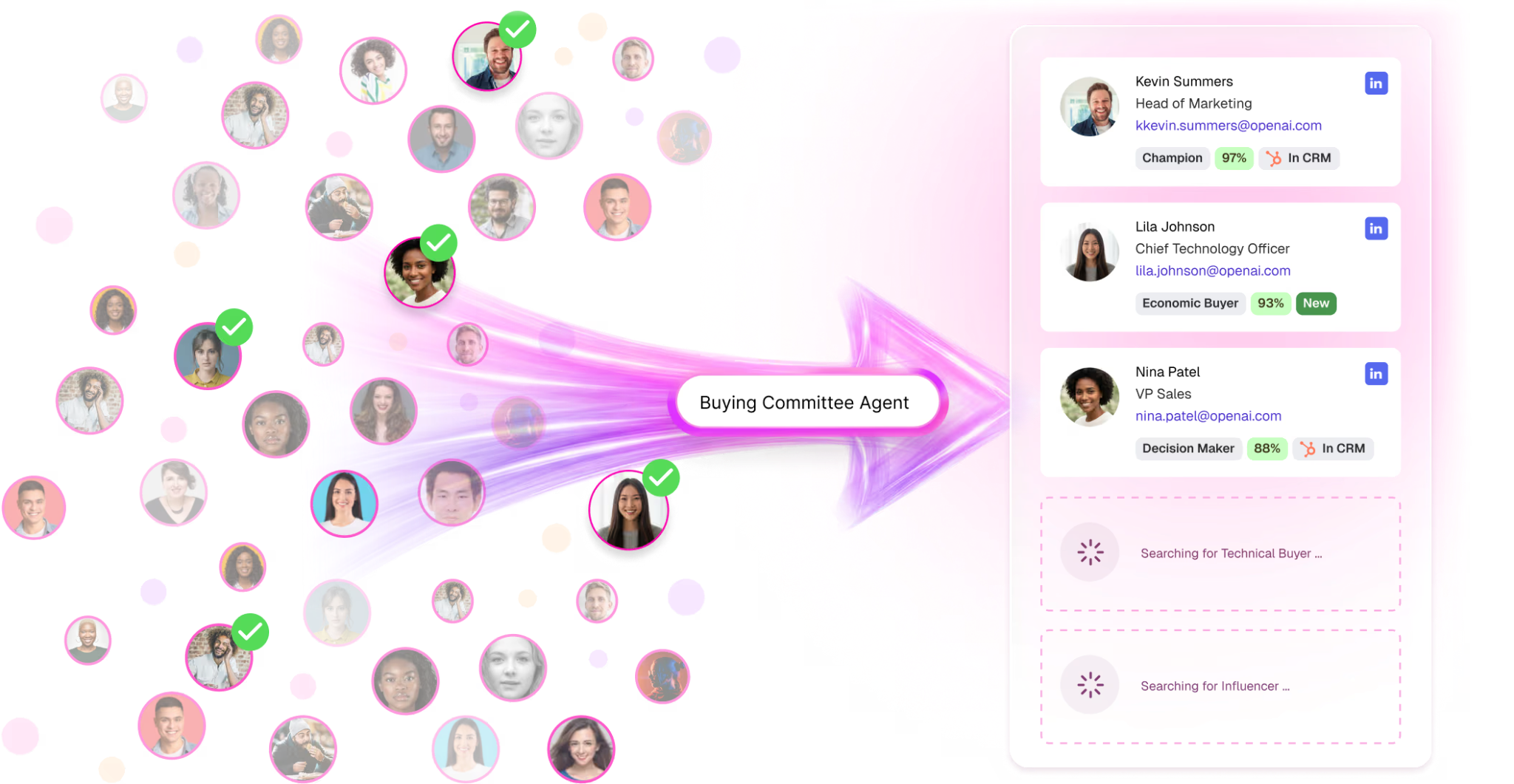
For each company in tier one and tier two, you map the buying committee. Not just one contact. The whole committee. For a typical mid-market B2B SaaS sale, that's 3 to 8 people: a champion (usually a director or manager who has the pain), an economic buyer (a VP or C-level who has the budget), and one or more end users or evaluators.
This is the part that used to be impossible at scale. You had to manually research each company, manually find the right people, manually verify their emails. It took a researcher 30 minutes per company. For a 5,000-company list, that's 2,500 hours of work. So nobody did it.
Now it takes 30 seconds per company because AI can do the research, find the people, verify the emails, and classify them by role and seniority. Our TAM Agent does it. Clay does it. Apollo's AI features do it. Pick a tool. The point is the work is now cheap.
Once you have the list, you don't just hand it to your SDR team and say "good luck." You orchestrate it across every channel simultaneously.
Through ads. You push the contact list and the company list into LinkedIn Ads, Meta Ads, YouTube. These platforms accept email lists, first-name/last-name/title/company lists, and account-based audiences. The exact same people getting your emails are also seeing your ads. An email plus an ad plus a LinkedIn message plus a familiar chat experience when they finally land on the site stacks in a way you cannot replicate with any single channel.
Through outreach. You push the contact list into your email sequencer (we use Instantly and Outreach, depending on the persona) and your LinkedIn automation (Salesflow, HeyReach). Email and LinkedIn touchpoints get queued up.
Through SDRs. You push the highest-tier accounts to your human SDRs for hand-touched calls, voice notes, and one-off personalized messaging.
Through retargeting. Anyone who lands on the site from any of the above gets cookied and added to your retargeting audience. You stay in front of them until they convert or leave the market.
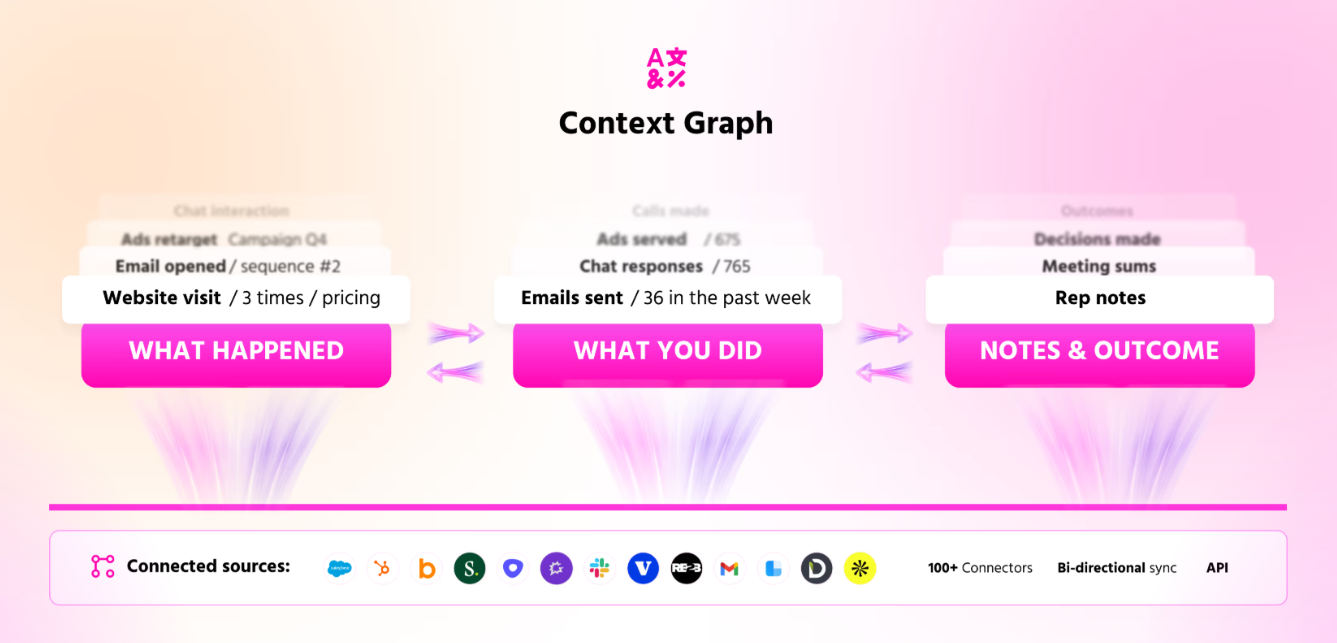
We use our orchestrator product to do this in one click. You can build the equivalent with Zapier, n8n, or just a Python script. The mechanics aren't sacred. The principle is: one list, every channel, all at once, automatically.
Here's the math on why this matters. If you hit each person once via email, your conversion rate is some baseline X. If you hit them via email and ads, your conversion rate is meaningfully more than X. If you hit them via email, ads, LinkedIn, and a retargeting sequence, your conversion rate is multiples of X. Buying decisions don't happen on one touch. They happen on the seventh or eighth touch, across multiple channels, over weeks or months.
The job of marketing is to engineer the seventh and eighth touch on every account in your TAM. Not to hope they happen.
Step 3: Fix the email infrastructure nobody talks about (sharpen the wand)
This is the part most marketers either don't know about or know about and refuse to do because it's tedious.
Email is the most powerful and most fragile channel in marketing. Powerful because it's effectively free at the margin. Fragile because Google and Microsoft will destroy your deliverability if you do it wrong.
If you only have one primary domain (yourcompany.com) and you blast it with marketing emails, here's what happens. Open rates drop. Reply rates drop. Bounce rates rise. Spam complaints rise. Google's algorithm decides your domain is a spammer. Your emails start landing in the Promotions tab, then in Spam. Eventually your sales team's individual emails start getting flagged too because they share the same domain. Now you've broken sales' ability to send a normal follow-up.
The fix is the email infrastructure your engineering brain hates and your marketing brain doesn't want to think about. Here it is in plain English.
You buy secondary domains. Not yourcompany.com. Things like trycompany.com, getcompany.com, hicompany.com. Cheap on Namecheap. Different TLDs work fine. You want 5 to 20 of them depending on volume.
You set up Google Workspace mailboxes on each domain. Each mailbox is a real human-looking inbox. Sarah Smith at trycompany.com. Mike Park at getcompany.com. Real names, real profile photos (use a service or generate them), real signatures. Yes, this means you're sending from "fictitious" reps. Yes, it's fine. Pretty much every serious outbound team does it. The alternative is burning your real domain, which is much worse.
You configure SPF, DKIM, and DMARC on every domain. This is the boring DNS-record-wrangling part. Skip it and your emails go to spam regardless of content.
You warm up the domains. You don't just buy a domain on Monday and blast 1,000 emails on Tuesday. You ramp slowly. Mailshake, Lemwarm, and Warmup Inbox are tools that do this for you. They simulate real conversation traffic on your new domains for 2 to 6 weeks before you send anything cold. Skip the warmup and Google flags you as a spammer in week one.
You cap volume per inbox. 30 emails per day per inbox is the safe ceiling. Try to send 100 and you'll get throttled or blocked. So if you want to send 600 cold touches a day, you need 20 inboxes minimum. We run 24.
You route replies into one place. Every inbox can receive responses. You don't want a salesperson logging into 24 inboxes a day. So you wire them all to a single response handler (a human SDR who watches them, or a tool like Instantly's unified inbox view). When a reply comes in, you route it to the right rep automatically.
Two ways to do this in practice:
Path A: Do it yourself. This is what our team does. Our ops person Desanka sets up the domains manually, creates the Google Workspace mailboxes, configures the DNS records, and adds them to Mailshake for warmup. It's a multi-day setup per batch of inboxes. Once it's done it runs forever.
Path B: Buy it as a service. Instantly and Smartlead both sell pre-warmed inboxes as part of their platform. You don't manage the infrastructure. The trade-off is you can only use those inboxes inside their platform. You can't, for example, use a Smartlead inbox in HubSpot or Outreach. For some teams that's fine. For us we run a mix.
This whole topic gets ignored because it's not glamorous. There's no thought leadership LinkedIn post in "we configured DMARC on 14 domains." But this is the foundation. Get this wrong and nothing else in the playbook works.
We have absolutely burned domains. More than once. I have opened Google Postmaster Tools and watched a domain reputation slide from High to Medium to Low over a ten-day stretch. It is a specific kind of stomach drop. You can rehab a domain, but it takes weeks. So we're paranoid about warmup now. You should be too.
Step 4: Run ads like you plan to quit them
Ads are a drug.
The first time you see ads work, you get hooked. You spend 10 grand, you get pipeline back. So you spend 20 grand. More pipeline. You spend 50 grand. More pipeline. Pretty soon you're at 200 grand a month and your CAC is climbing and your CFO is asking questions and you can't turn it off because you've made your number contingent on it.
I'm going to tell you this even though we sell more pipeline by running better ads: the goal of your ad program should be to wean yourself off ads.
Here's why. Ads are rented attention. The second you stop paying, the attention stops. You're not building anything. You're renting demand from Meta and Google and LinkedIn, and they get to set the price. The price always goes up. CPCs have been climbing for a decade. Apple's ATT broke Meta's targeting and made every conversion 30 to 50 percent more expensive overnight. iOS 17 broke more. Google's third-party cookie deprecation will break more. The trend is one direction.
The reason to run ads is to acquire net new awareness from people who don't know you exist, then convert that awareness into an owned audience you don't have to keep paying for. Ads are the top of the funnel. The bottom of the funnel is the audience you own.
What this looks like in practice. Run ads only to the buying committee at companies on your TAM list, plus your retargeting audience. That is it. Auto-optimization to "people who look like your converters" is how you accidentally pay to advertise to college students who will never buy. Push your TAM list directly into LinkedIn, Meta, and Google as a custom audience so the people getting your emails are also the people seeing your ads. Build the strongest retargeting audience you can: people who came to your site and bounced are roughly 10x more likely to convert than cold prospects, and our retargeting CTR runs around 8% versus 1 to 2% for cold.
The single number that matters more than CTR or CPC is ad spend as a percentage of marketing-sourced pipeline. If your following is growing, that ratio should be shrinking quarter over quarter. If it's not, you're renting demand instead of building it. That works until it doesn't, and then it stops working all at once.
The capture: keep matter in your field
Steps 5 through 7 are about what happens once the matter shows up. Most marketers spend almost all their budget on the push side and have almost no infrastructure on the capture side. That's the imbalance the next decade rewards fixing.
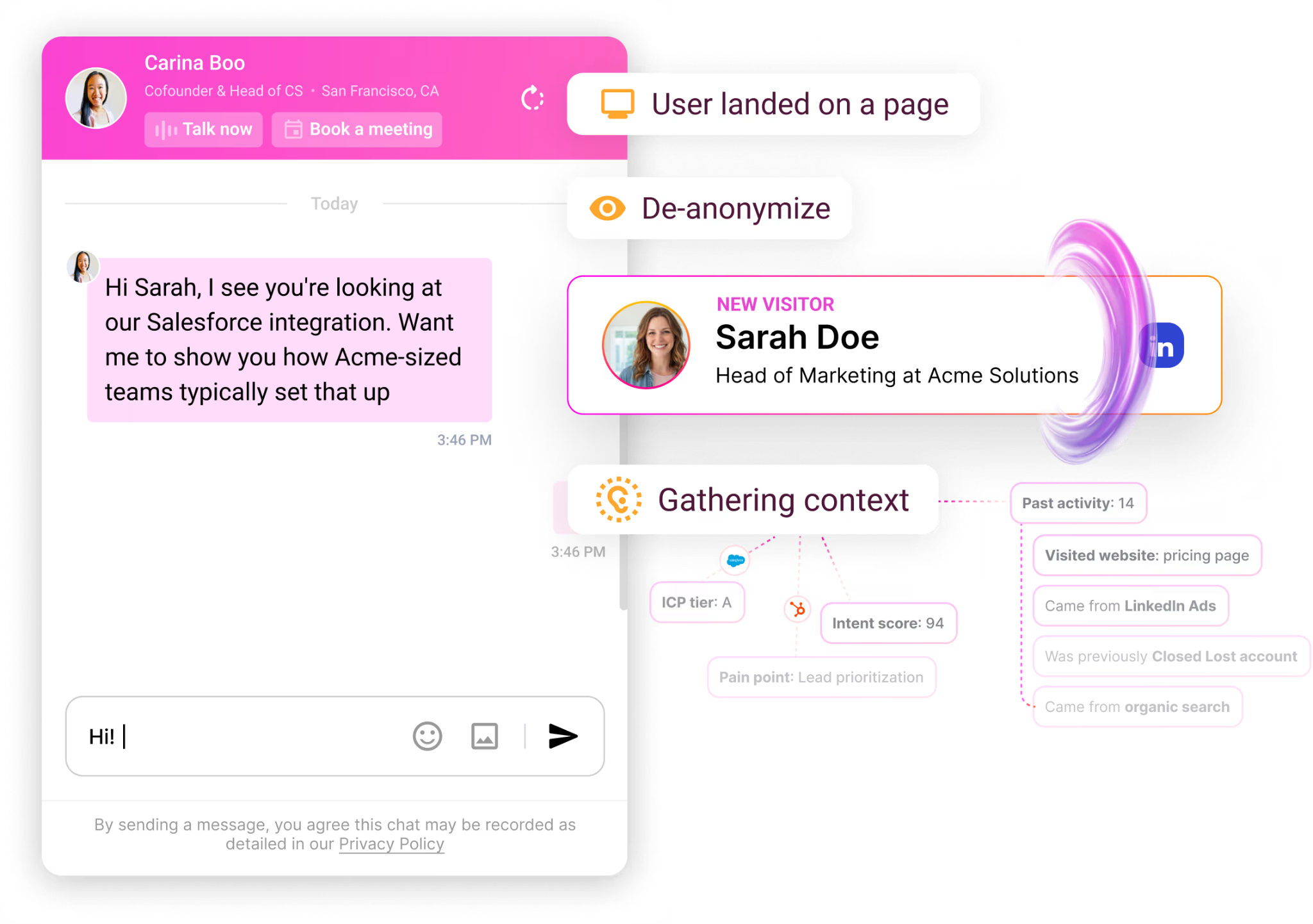
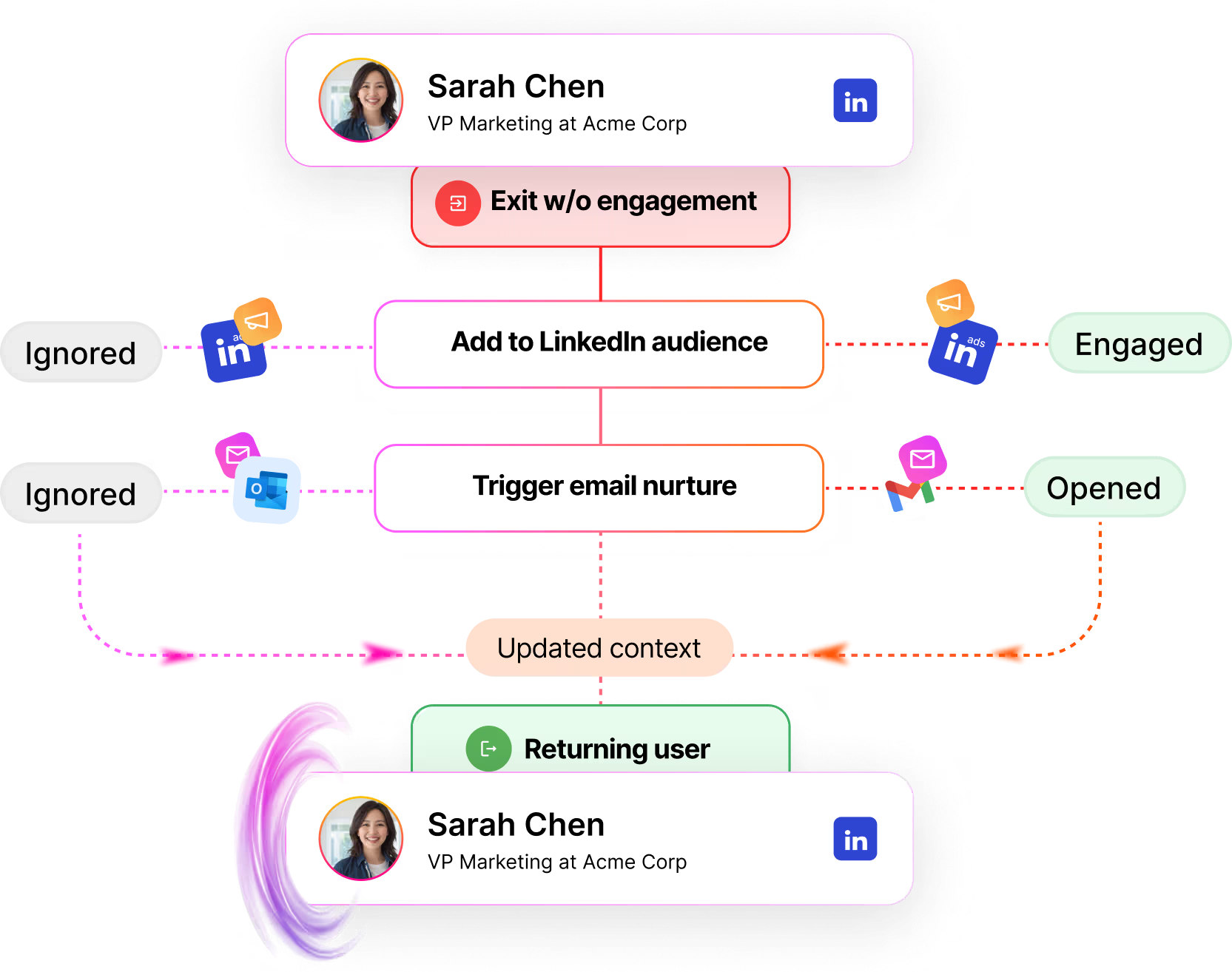
Step 5: De-anonymize and retarget (catch what enters the field)
This is the part that changes the whole shape of marketing.
Of the people who click your ads, your blogs, your social posts, only 1 to 3 percent fill out a form. The other 97 to 99 percent are invisible. You spent the money to get them to your site. They expressed enough interest to click through. And then you lost them.
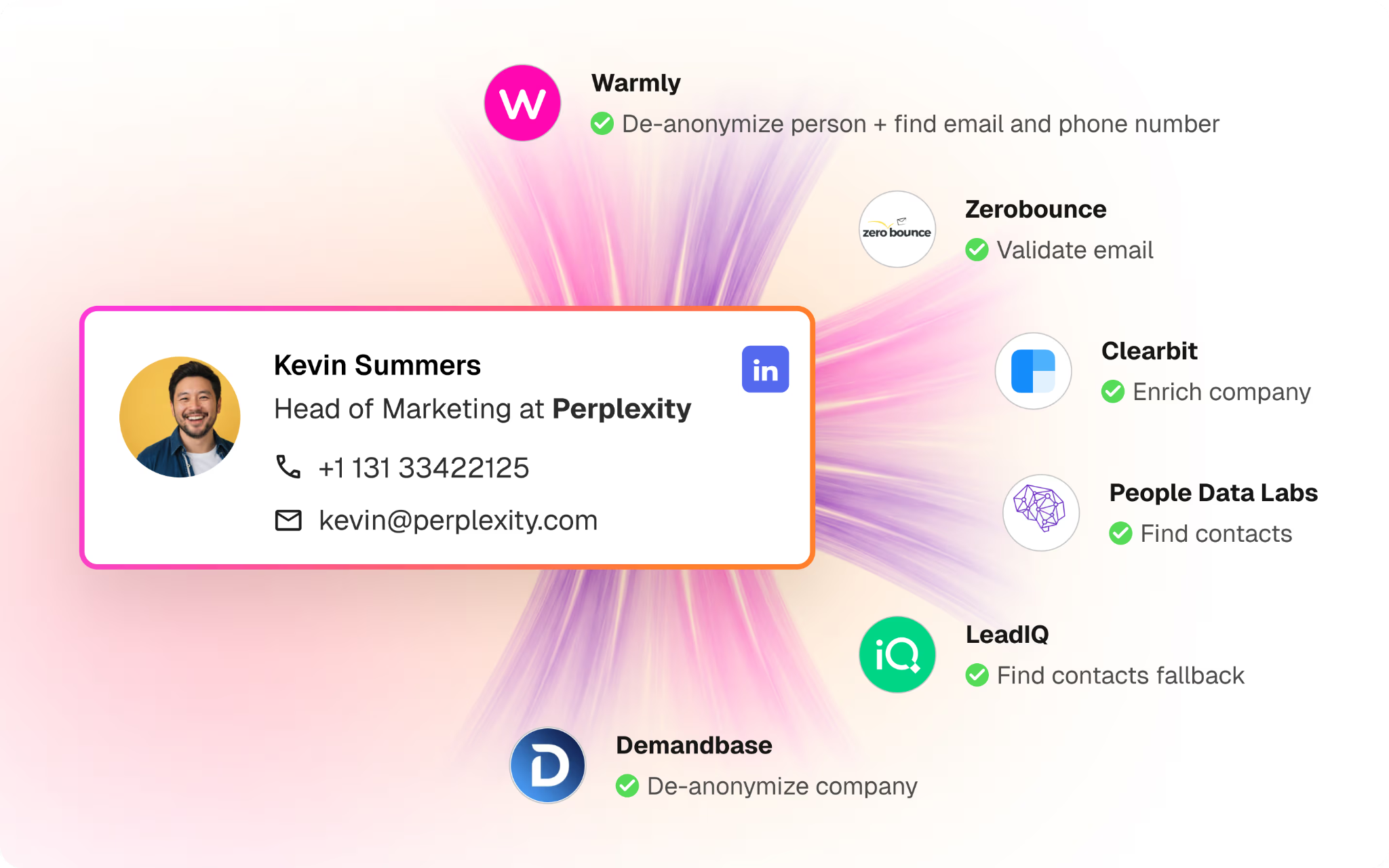
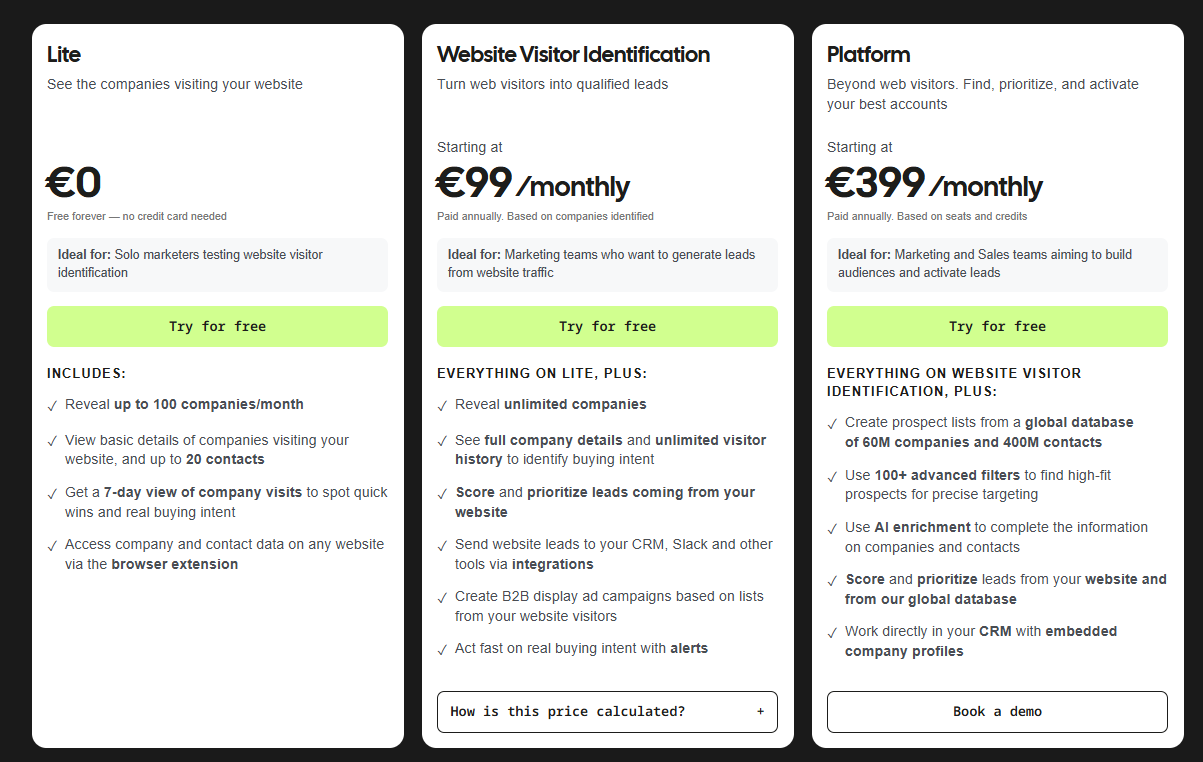
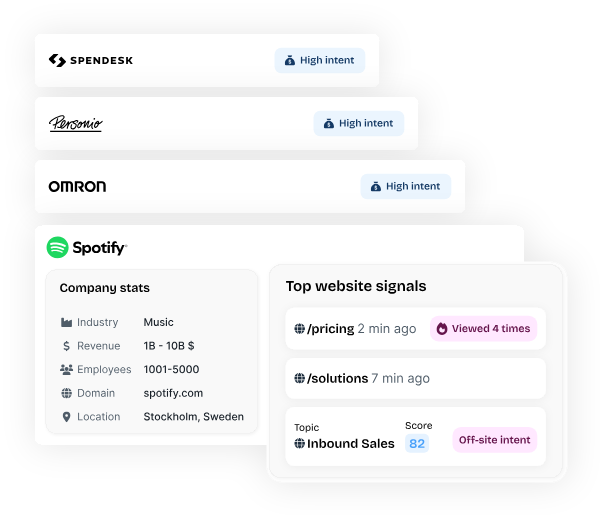
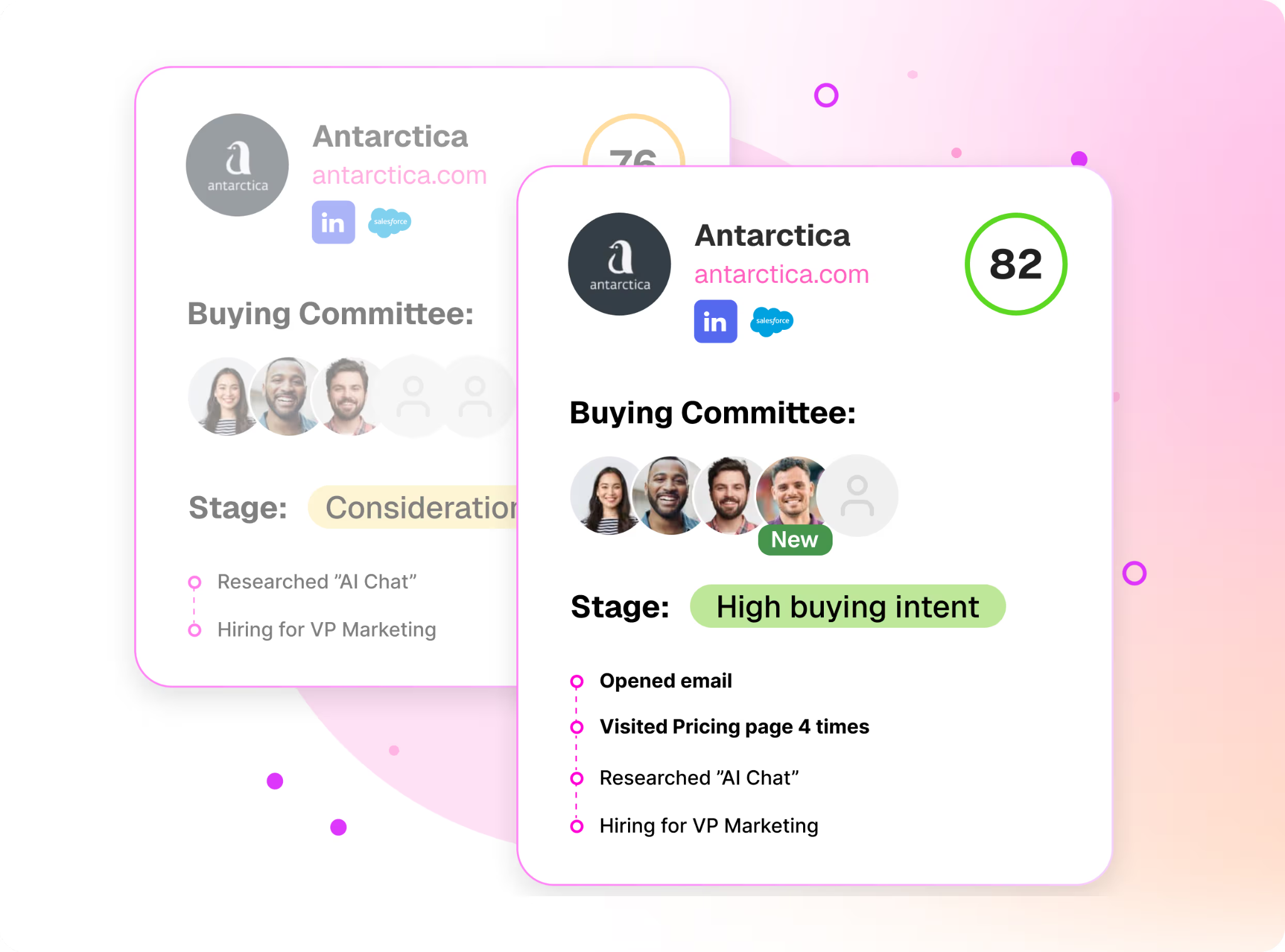
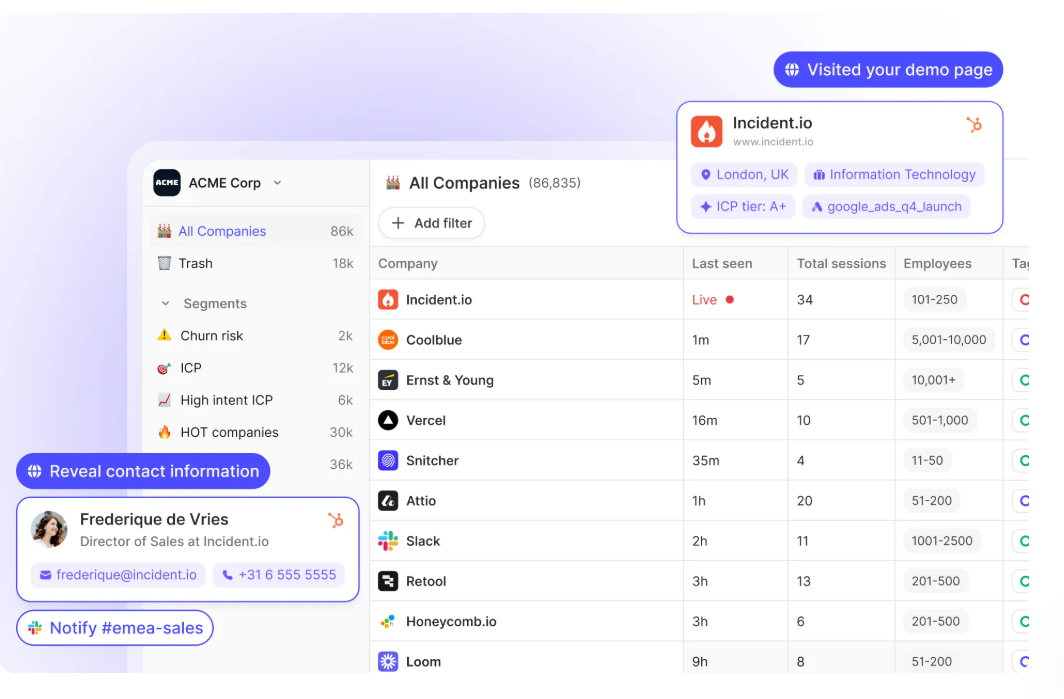
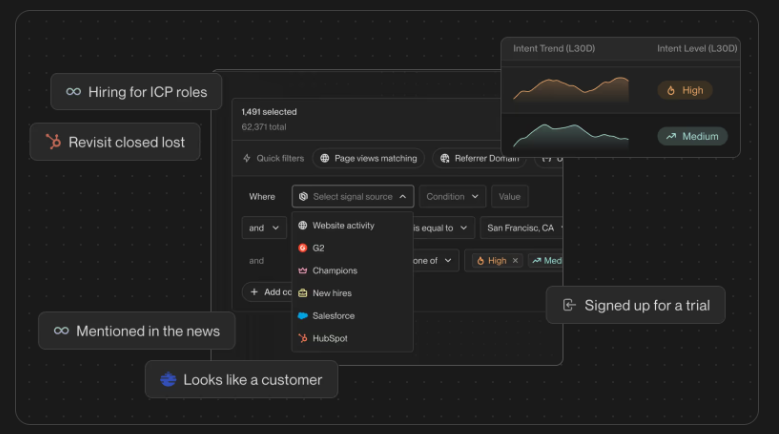
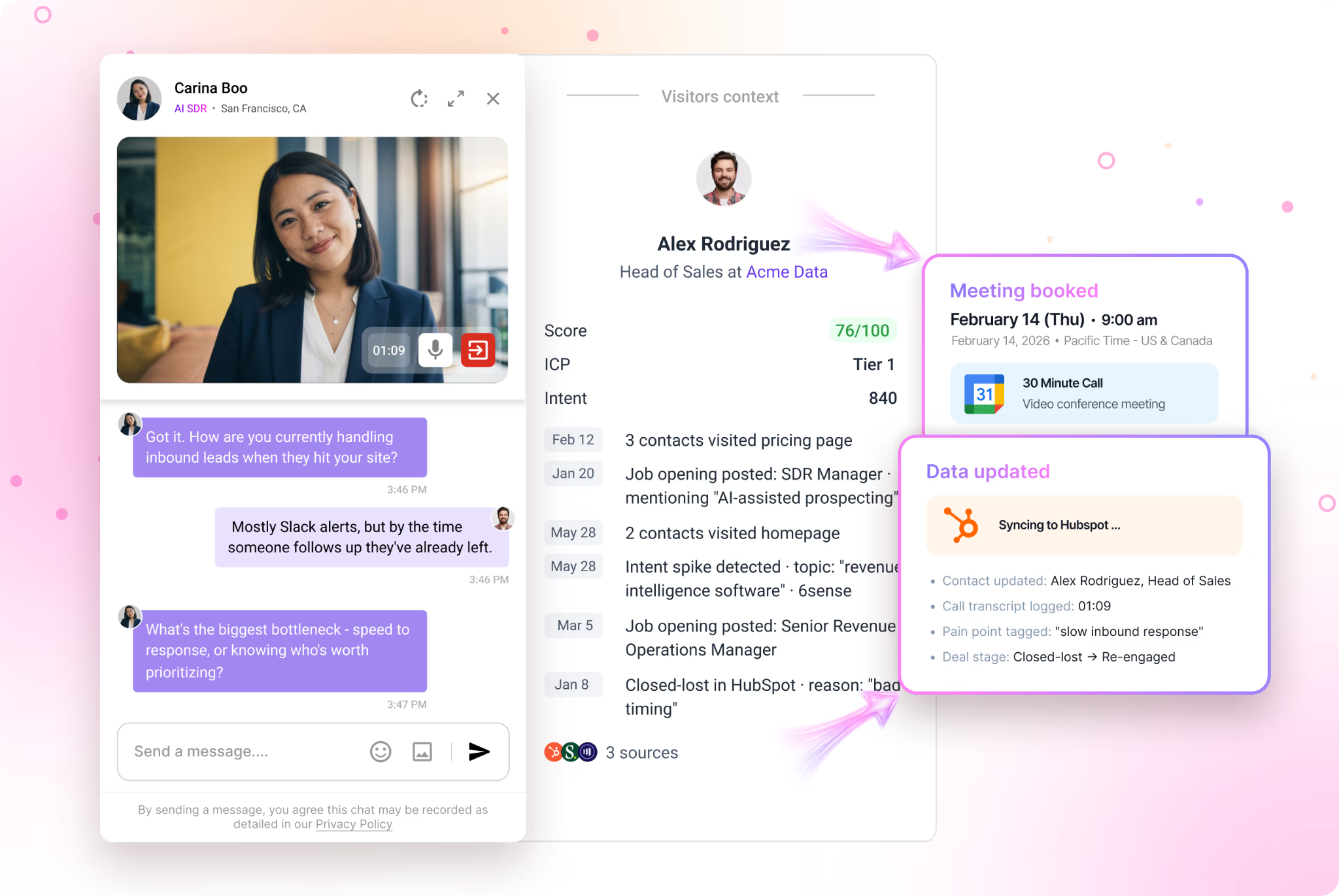
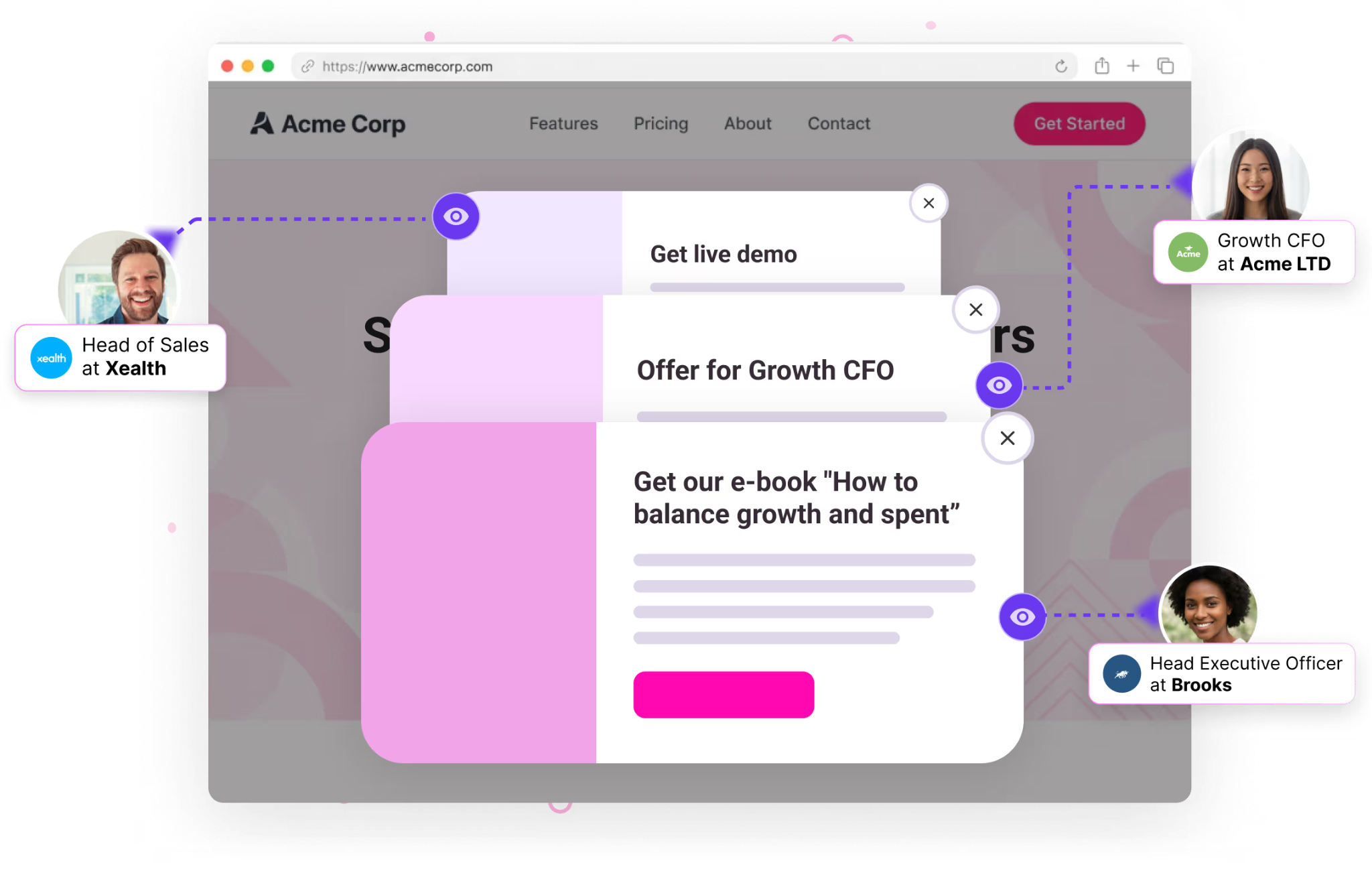
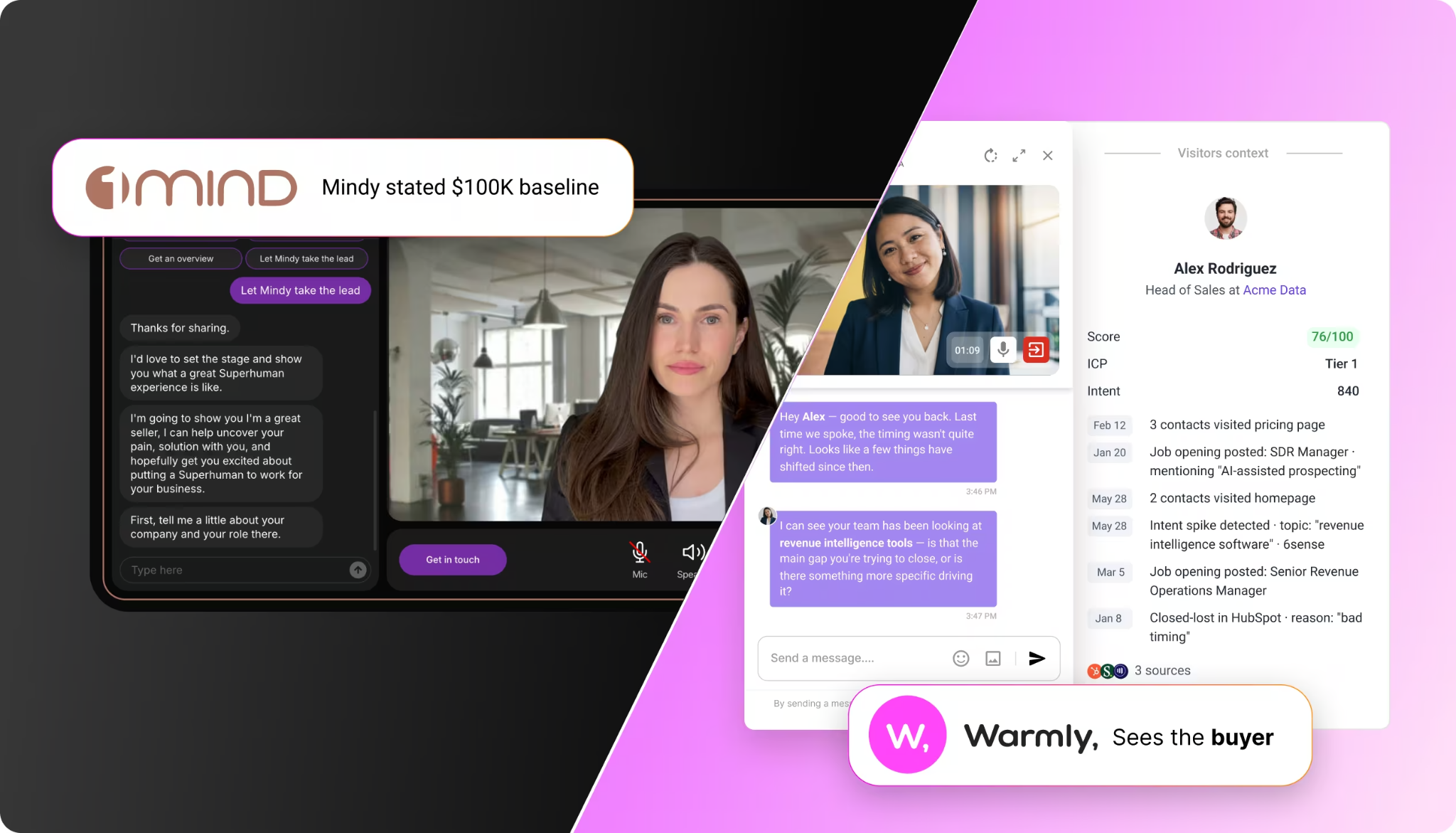
The technology to identify those visitors has gotten dramatically better in the last 18 months. Tools like Warmly, RB2B, Vector, Common Room, Clearbit Reveal, and ZoomInfo Websights all do parts of this. They use a mix of cookie matching, IP intelligence, third-party identity graphs, and behavioral fingerprinting to match the anonymous visitor to a real person at a real company.
Match rates vary. The honest truth is no vendor is at 100%. We're the highest in the industry on person-level match rate for our ICP because we integrated Vector and RB2B underneath and built our own identity graph on top, but we still miss visitors. Some people just can't be resolved. That's fine. You don't need 100%. You need enough to be useful.
Once you know who's visiting, you do three things.
One: Add them to your retargeting audience. Across LinkedIn, Meta, Google, YouTube. They came to the site. They're interested. They're going to see your ads now no matter where they go on the internet. This is the highest-ROI ad spend you can run.
Two: Add them to your newsletter list. Quietly. Not as a hard subscribe, but as an "engaged but unconverted" audience that gets value from you over time. They didn't ask to be subscribed, but they showed up at your site and engaged, so you're giving them something useful (not a sales pitch). If they don't want it, they can unsubscribe. The vast majority don't unsubscribe because the content is genuinely useful.
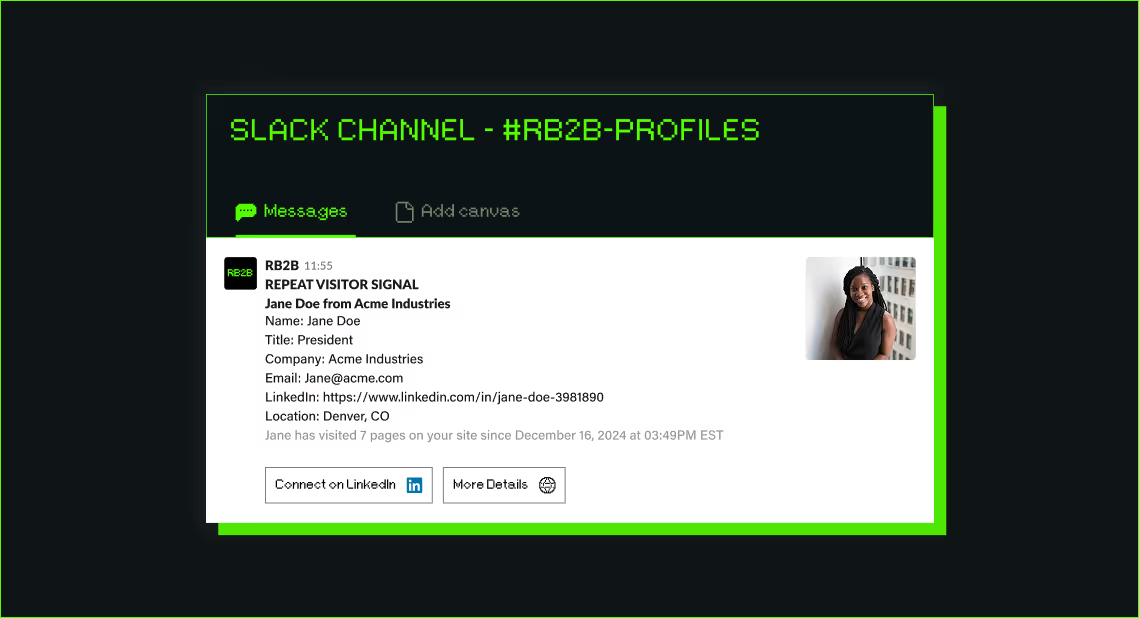
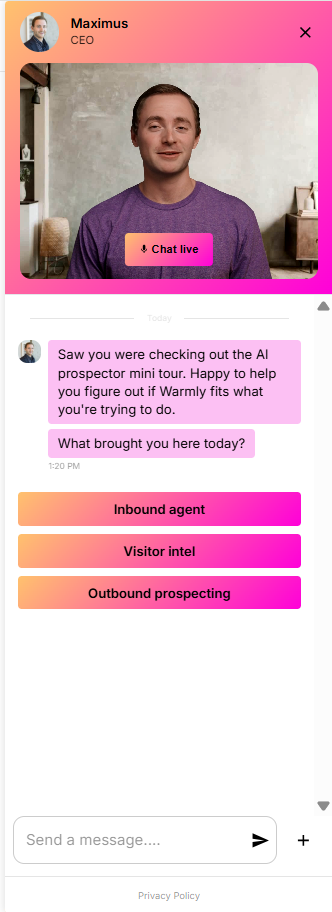
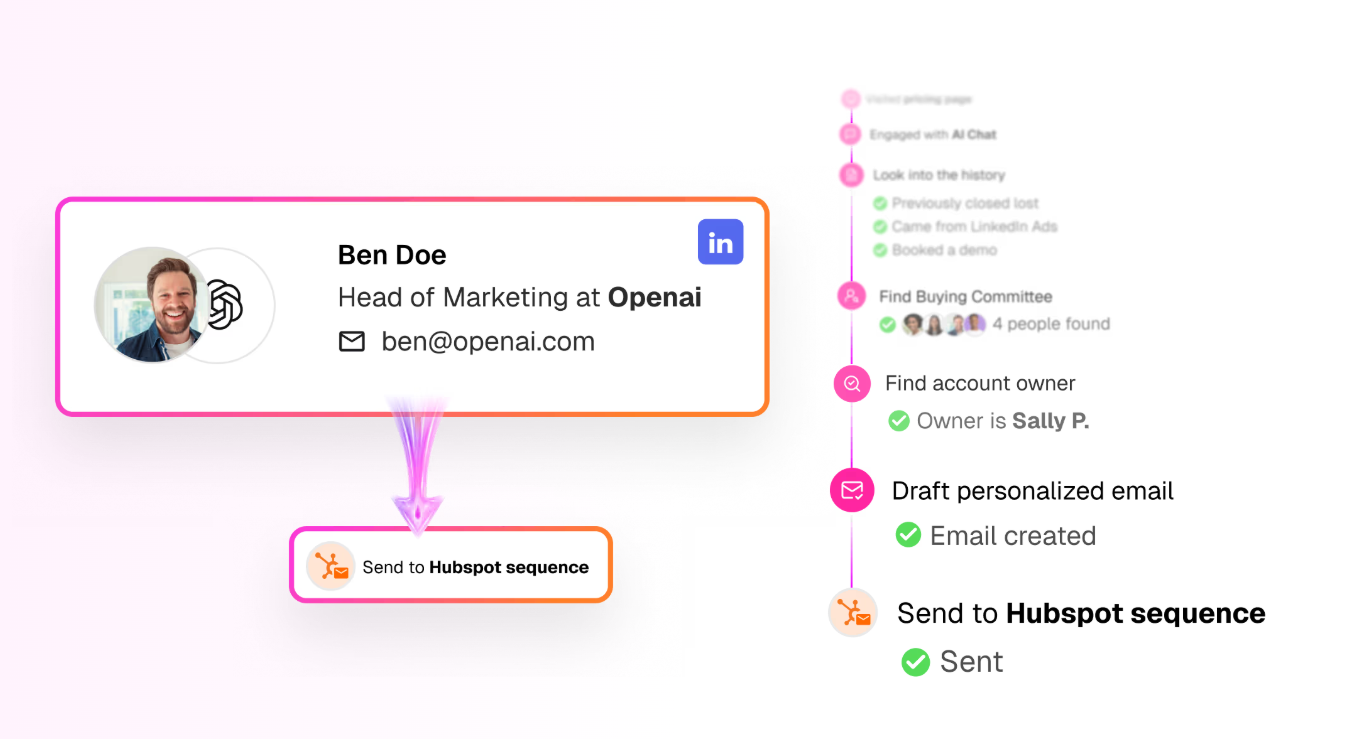
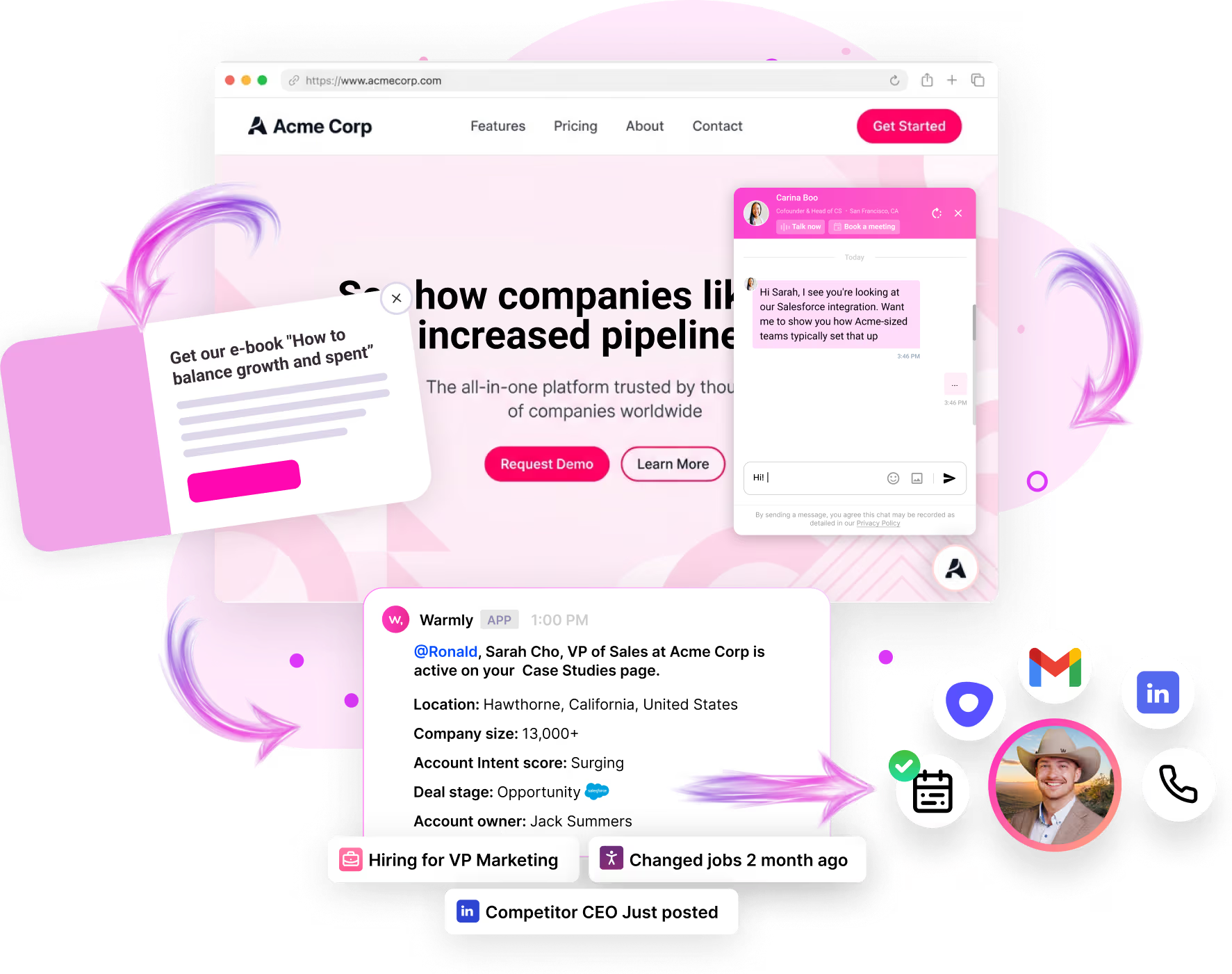
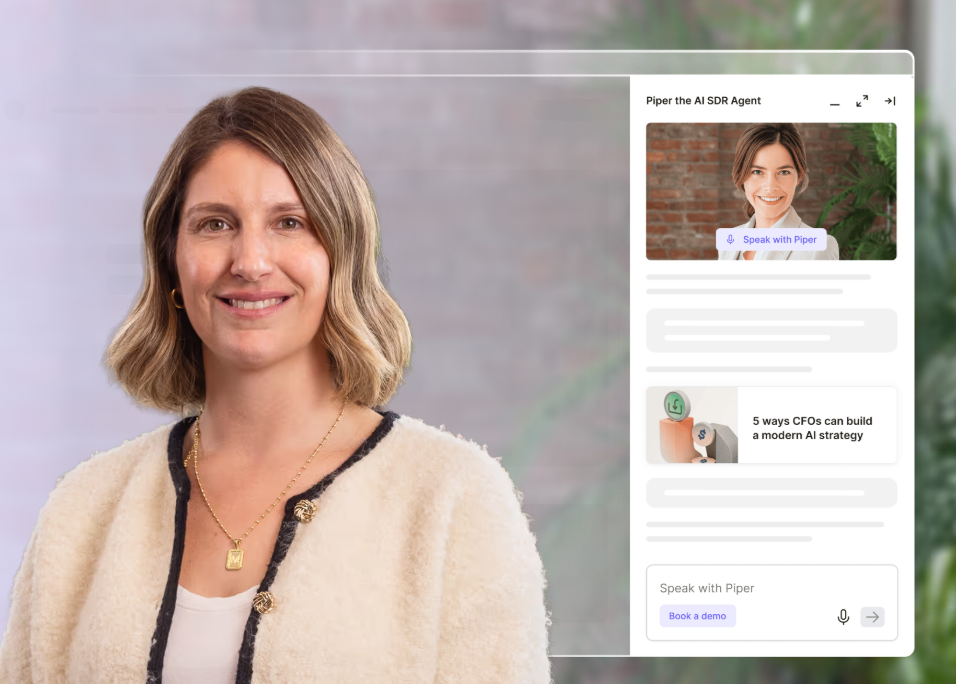
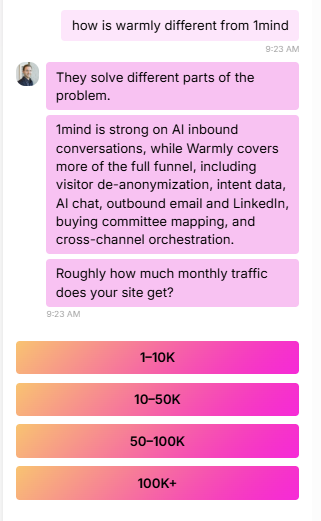
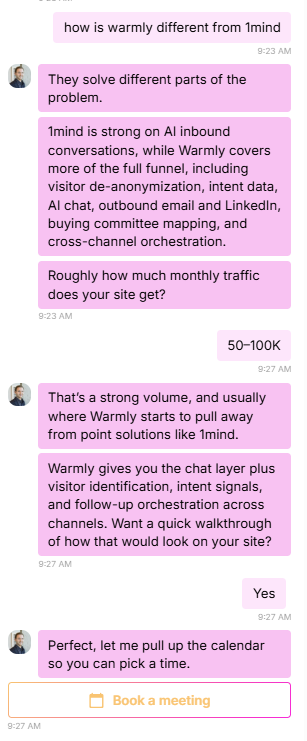
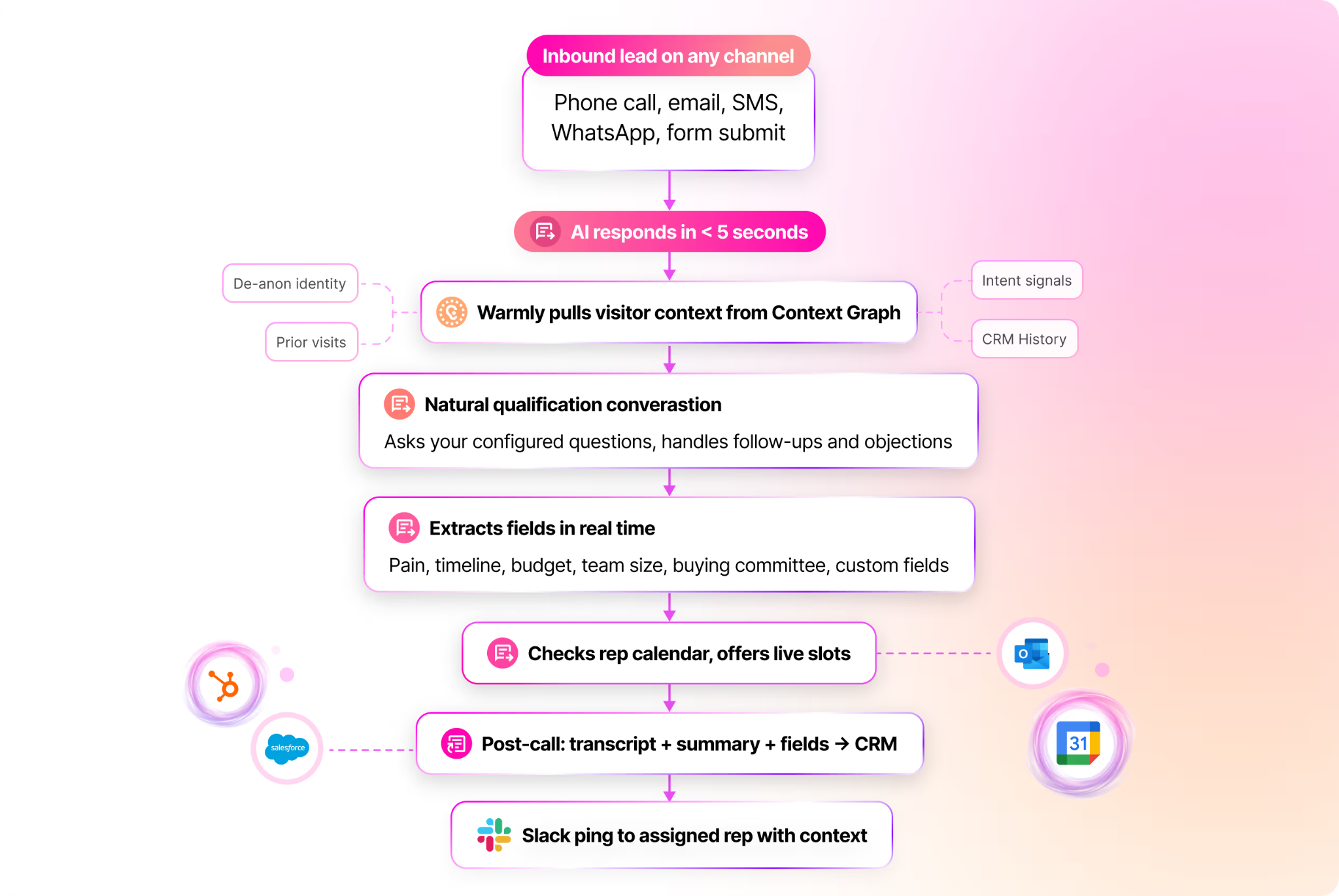
Three: If they hit a high-intent page (pricing, demo, product), route them in real time. Either to a live chat with a human SDR, or to an AI chat that can answer questions and book a meeting on the spot. The window of intent is tiny. Most B2B visitors are on your site for 8 to 30 seconds. If you can't engage them in that window, they're gone. Our AI inbound agent now books more demos after hours than human reps do during the workday, because executives do their research at night and on weekends and our agent doesn't sleep.
When I walked the head of marketing whose email program got killed through this part of the playbook, his whole posture changed. The thing that had been a battle ("can I send emails?") got reframed. He doesn't need to send cold emails to people who haven't asked for them. He needs to know who's already on his site and engage them where they are. Sales doesn't fight that. Sales loves that.
This is also where the political dynamic flips. When you say to sales "I want to send 5,000 cold emails this quarter," they push back. When you say to sales "I'm going to identify the 200 ICP companies hitting our site this month and route them to you in real time with full context on who they are and what they looked at," sales listens. You're not stepping on their territory. You're feeding it.
Step 6: Make your newsletter your actual brand (scripture in practice)
Most B2B newsletters are bad.
They're product updates dressed up as content. They're roundups of company news nobody cares about. They're announcements of webinars and ebooks. They're not actually written for the reader.
If you want to build an owned audience, your newsletter has to be the thing your audience genuinely looks forward to. Not "I should read this." But "I want to read this."
Here's the test: if you were your customer, and your inbox was already full of crap, and your newsletter showed up, would you open it? Would you read past the first sentence? Would you forward it to a colleague? If the answer to any of those is no, the newsletter is broken.
What good looks like: one useful idea per issue, specific enough that a reader can take it and use it the same week. Real numbers, real tools, real workflows, real people. The voice of one person, not a committee. A cadence you can actually sustain (a great monthly beats a half-effort weekly every time).
The tools side is straightforward. We use Customer.io for the send platform because it handles segmentation, automation, and deliverability well at scale. We write the HTML templates using Claude Code. Literally: I paste the latest blog post or playbook into Claude Code and say "make me a Customer.io HTML email template for this." It outputs the HTML. I paste it into Customer.io. Done. What used to take a designer a half-day takes 15 minutes.
The trickier part is content. Content is the work. AI helps with drafting and editing but it can't replace your point of view. You have to actually have something to say. The good news is if you're running the rest of the playbook, you have material constantly. Customer conversations, new playbooks, internal experiments, things that worked, things that didn't. Your job is to turn that exhaust into newsletter content.
For our team, the newsletter goes to about 14,000 people. The open rate is well above industry benchmark (we don't share exact numbers because Customer.io's tracking shifted with iOS, but it's strong). More importantly, the newsletter is what people quote back to us on sales calls. "I loved your piece on agentic GTM." "I forwarded your newsletter to my CMO." That's the actual leading indicator. Not opens. Not clicks. Forwards and references.
Step 7: Coordinate the social and launch motion (turn scripture into miracles)
This is the third leg. Social posts and product launches.
Social posts. LinkedIn is the only B2B social platform that consistently moves the needle. Twitter/X works for a narrow set of personas. Threads is still emerging. TikTok and Instagram are for a different audience. For B2B SaaS, LinkedIn is the platform.
The hard part is consistency. The compounding part is the team. If only the CEO posts, the audience tops out. If the whole go-to-market team posts (CEO, head of marketing, head of sales, top AEs, top CSMs), the surface area is enormous and self-reinforcing.
Our team posts on LinkedIn most workdays. Not all posts are bangers. Some get 50 likes. Some get 500. Some get 5,000. The distribution of outcomes is wildly uneven. The discipline is in posting consistently and analyzing what worked. We use Vetric to pull LinkedIn engagement data and look at high-performing posts (both ours and other people in the space, like Max Greenwald, Adam Robinson, the Common Room team) and reverse-engineer what made them work.
What I've learned about what makes a LinkedIn post work in 2026: the first seven words decide whether anyone reads the rest, lead with a concrete claim or a story instead of a "five tips for X" frame, put real numbers and real tools in the middle, and let the post itself be the call to action. Length follows substance, not the other way around: a 100-word post can crush, a 1,000-word post can crush, the one that fails is the one that pads.
Launches. The other half of the social motion is product launches. Most companies launch like it's a one-time event. Big blog post, single LinkedIn post from the CEO, maybe a press release. Done.
We treat launches like a release engineering exercise. Every launch has a checklist, a comms plan, a Notion doc that coordinates everyone involved, and a multi-channel rollout. The same launch hits LinkedIn (organic posts from 6 to 10 team members, staggered over a week), email (newsletter dedicated to the launch), in-product (banner or popup for existing customers), ads (paid campaigns targeting the relevant ICP slice), and partners (asks for cross-posts from integration partners).
We launched LinkedIn Ads integration last month. We launched Marketo this month. We launched Pipedrive. We launched Meta Ads. The cadence is roughly one feature launch a week, sometimes more. Each launch generates inbound for two to three weeks afterward, so by week four you're sitting on top of three or four overlapping inbound waves at once.
If your product team isn't shipping at this cadence, you have a different problem (which is fine, every company is at a different stage). But if they are shipping, and you're not coordinating launches that match the cadence, you're leaving most of the pipeline on the table.
Webinars. Last point on the social motion: webinars are still the most underused tactic in B2B. Done right, a webinar converts 10 to 20 percent of attendees to opportunities. Done wrong, it's a slog. The right way is to teach something genuinely useful. Co-host with a partner brand to share the audience. Promote it for 2 weeks. Run it for 45 minutes. Send the replay to every registrant for 4 weeks after.
We did one last week about how we 3x'd pipeline. 200 people registered. 80 showed up live. Many more watched the replay. A handful of opportunities have already come out of it. That's a higher conversion rate than almost any ad campaign we've ever run.
The multiplier: use the wand at full strength
The other seven steps are what you point it at. This is the part that turns one marketer into the equivalent of a team of eight, if you do it right.
Step 8: Run the whole thing through Claude Code
Here's the part that ties it all together and that almost no marketer outside of a handful of nerd-leaning operators is using yet.
Claude Code is Anthropic's terminal coding tool. It's nominally a developer tool. It's actually the single highest-leverage marketing tool that exists in 2026.
The way it works: you install Claude Code locally. You point it at a folder on your computer. You give it API access to all your marketing tools (Webflow, HubSpot, Customer.io, Google Ads, Meta Ads, LinkedIn Ads, Google Tag Manager, Google Analytics, your CRM, your database, your SEO tool). Now you have an AI assistant that has full read and write access to your entire marketing stack and can do work for you.
Three examples from how I actually use it day to day.
Pages. I tell Claude Code: "Create a landing page for our TAM Agent. AEO, SEO, GEO optimized. Compare against Apollo and ZoomInfo. Plan first, grade the plan, iterate until it's a 10, then build." It outputs the full page copy, structure, and metadata. My designer ships it in Webflow two days later instead of two weeks.
Ads. Claude Code talks to Meta, Google, and LinkedIn ad APIs directly. "Pull last 30 days. Analyze CAC by audience and creative. Recommend which campaigns to kill, which to scale, then execute after I approve." Done.
Reporting. I run a single skill that pulls live data from Google Analytics, all three ad platforms, Search Console, the SEO tool, HubSpot, and our pipeline database, and outputs a marked-up demand-gen report with week-over-week and month-over-month comparisons. Fifteen minutes. Used to take a marketing-ops person half a day.
This is not a hypothetical. This is what I actually do every day. The leverage is absurd. One marketer with Claude Code, an opinionated playbook, and a designer can do the work of a team of eight.
The setup is real work. You need to configure API access for every tool. You need to write a CLAUDE.md file that tells Claude Code your voice, your preferences, your folder structure, your common tasks. You need to build custom "skills" for the tasks you do repeatedly. We've documented the most common skills in our playbooks library. You can copy ours or build your own.
The cost is roughly 20 dollars a month per seat for the Claude Code subscription, plus token usage that's currently subsidized to almost nothing. For context, our entire ad budget some months is 50 to 80 thousand dollars. The tool that runs the whole machine costs less than a meal for two.
If you only do one thing on this list, do this one. Everything else compounds off the back of it.
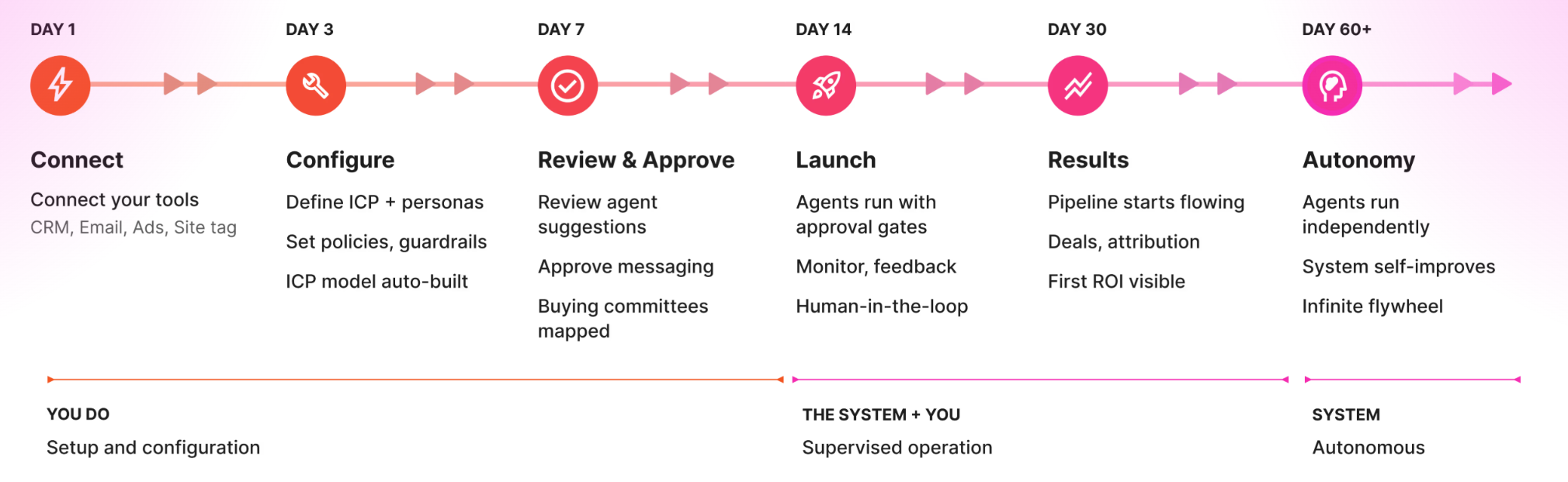
How we 3x'd pipeline in 30 days with a smaller team
I've described the parts. Let me describe what happened when we put them together.
In February, our pipeline was about one million. That was off a team of four SDRs, one demand gen lead, one content person, one designer, and me. Ad budget was around 35 thousand. Decent month. Not great.
In March, pipeline was three point two million. Same team. Slightly smaller ad budget. Higher SDR quota attainment (the team hit 180% of quota with a four-person team that used to need to be eight).
What changed, in order of impact:
- We rebuilt the website as a knowledge base. Sixty new pages across products, solutions, and comparisons. AEO inbound from ChatGPT, Claude, and Perplexity went from roughly zero to roughly one in nine of all inbound.
- We tightened the TAM and pushed the same list across every channel simultaneously. Email, LinkedIn, Meta, Google, YouTube, the AI SDR. This single change moved conversion more than anything else we did.
- We started identifying website visitors. About 60% of anonymous traffic now gets resolved. Those people go into retargeting, the newsletter, and the SDR queue if they're high-intent.
- We coordinated a launch every week. Each launch generated two to three weeks of inbound, so by week four we were sitting on three or four overlapping waves.
- We ran the whole machine through Claude Code. I now do roughly four to six hours of marketing work per hour because the overhead disappeared.
None of these are sacred individually. The thing that made it work was running them all at the same time, with a tight TAM, with the right infrastructure underneath.
One more thing I want to put in writing because I think a lot of these "we 3x'd pipeline" posts make it sound like a magic trick. It isn't. March was great. April was great. May is on track to be better. There are also months in our history where this machine produced less than half of what it produced in its best month. The compounding works in both directions. Skip a few weeks of launches, let the newsletter slip, pause the social cadence because someone got busy, and the numbers go the other way.
The job isn't to find the trick. The job is to run the system every week, forever, and let the math compound.
The job has changed
The head of marketing whose email program got killed is going to be fine.
Not because he is going to fight his CRO and get the emails turned back on. He is going to be fine because the job has changed and the new job does not require him to fight that battle.
The old job of marketing was to push messages out and hope the right person was on the other side. Email. Cold calls. Cold ads. Cold lists. Volume.
The new job of marketing is to build a religion that produces gravity, and to build the infrastructure that catches the matter the gravity pulls in. Be findable to the model layer. Choose the audience your religion is for. Push the right matter through your orbit. Capture it when it gets there. Keep it orbiting through scripture, miracles, and the consistent presence that turns strangers into followers.
Sales actually likes this version. They get warmer leads, more context, faster routing, and marketing is not sneaking emails out from under their nose. The CFO likes it because ad spend stops being the only way to grow pipeline. A field compounds. Rented attention does not. The CEO likes it because pipeline goes up while the team gets smaller.
The only people who really fight the new shape of this job are marketers who built their careers on the old playbook and do not want to learn a new one. Which I get. Change is annoying. The old playbook worked for a long time. But it stopped working for the reasons above, and pretending it did not is not a plan.
If you are reading this and you are a head of marketing or running demand gen, the punchlist:
Start with Step 1 and 2 (findable, list) because nothing else works without them. Get Step 3 (email infrastructure) right before you try to scale outbound. Treat Steps 4 and 5 (ads, de-anonymization) as one system, not two. Build Step 6 (newsletter) as your scripture engine. Coordinate Step 7 (social and launches) as a weekly cadence. And run all of it through Claude Code (Step 8) so one person can do the work of eight.
This is a lot. Nobody does all of it perfectly. You do not have to. You have to be doing more of it than your competitors. The compounding does the rest.
If you want to talk through how to apply this to your specific situation, book a demo. We will walk through your stack, your team, and your funnel, and tell you exactly which parts to start with based on where you are stuck.
Marketing is gravity now. Every founder is a prophet. Every company is a religion. The sales team killing your email program is not the worst thing that can happen to your marketing function. It might be the best thing, because it forces you to stop being a pipeline factory and start being someone people actually want to follow.
That is the whole job now.



![Demandbase Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a353caddcd5ecf848e46ea7_demandbase%20pricing.png)




![10 Best Snitcher Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a2c18de1740cf1b5ffe70f7_snitcher%20alternatives.png)





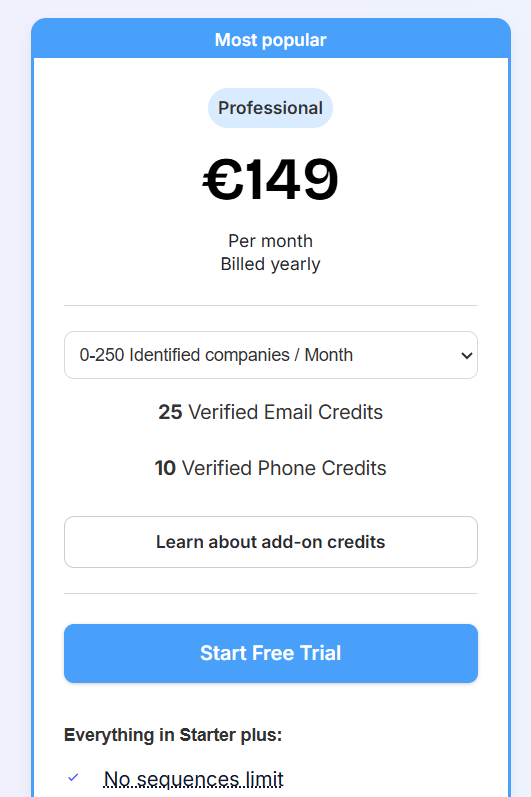
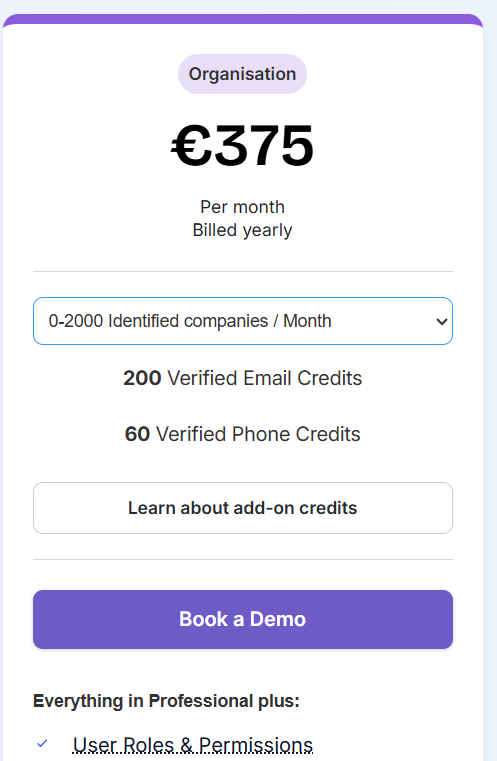
![Albacross Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a2c16faec9dd450aee359ac_albacross%20pricing.png)

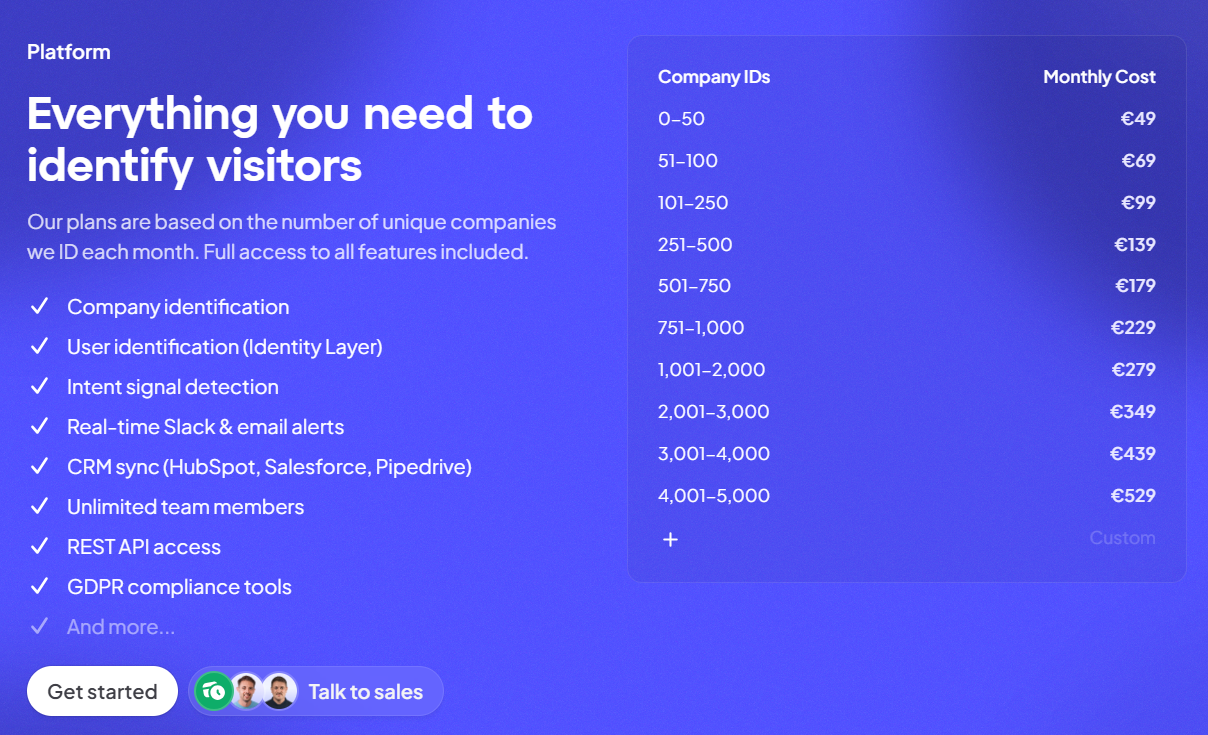
![Common Room Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a2299cb2e63bc69223ea63d_common%20room%20pricing.png)

![10 Best Albacross Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a2297519e7f1d1c19cfda93_albacross%20alternatives.png)
![10 Best Common Room Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a1a91bba75f99c148911b7f_common%20room%20alternatives.png)
![10 Best Agentic Inbound Agents In 2026 [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a185fc1a37dcea65149d3aa_agentic%20inbound%20agents.png)




















![1mind Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a078f452db57390c841608f_1mind%20pricing.png)



![10 Best 1mind Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a078ea59b3086cb402582d4_1mind%20alternatives.png)