The Infinite Execution Paradox
Something strange has happened in go-to-market.
We've built tools that send millions of emails. Products like Salesforce, Clay, Parallel, and Exa can index entire markets in hours. LLMs generate near-infinite personalized copy, scripts, and chat conversations. Generic orchestration tools wire events together in minutes.
Execution has become effectively infinite.
And yet, pipeline is harder than ever to build. Response rates are cratering. Buyers are drowning in noise. The best SDRs spend their days sifting through false positives while real opportunities slip through the cracks.
The paradox is this: we've solved the wrong problem.
We built infrastructure for doing more. We should have built infrastructure for knowing what to do.
The bottleneck to get pipeline is no longer execution. It's decision quality. Given virtually unlimited execution capacity, how do we allocate finite resources (e.g. human time, inbox space, ad dollars, brand capital) to the right accounts, at the right time, with the right plays?
This is the question Warmly was built to answer.
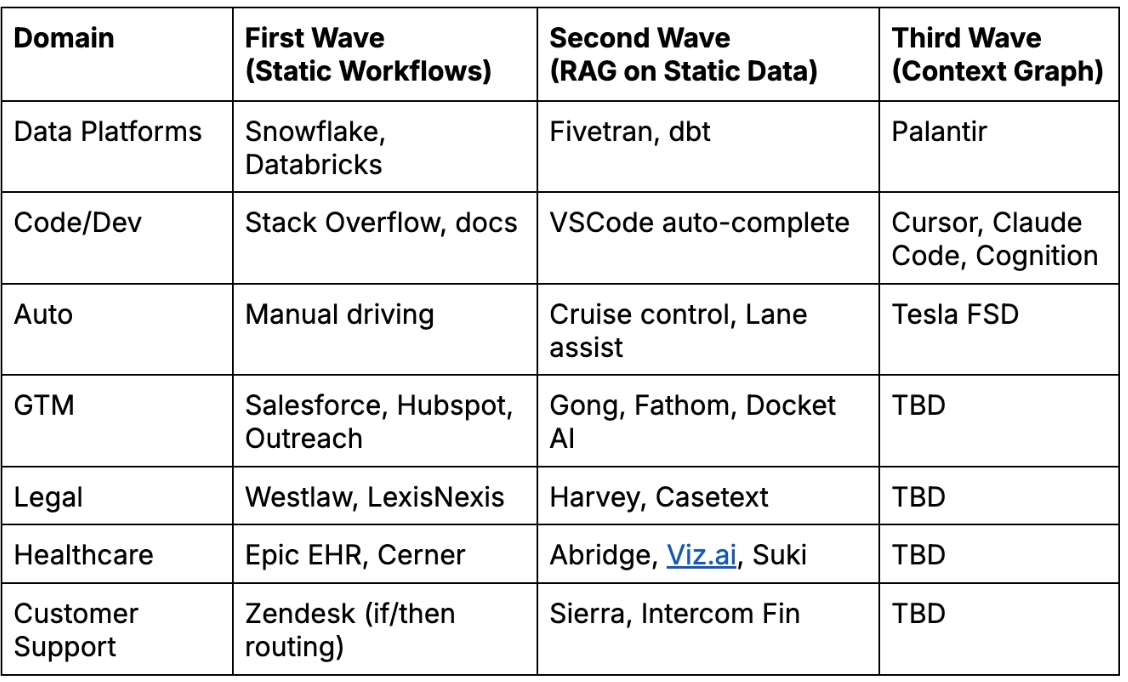
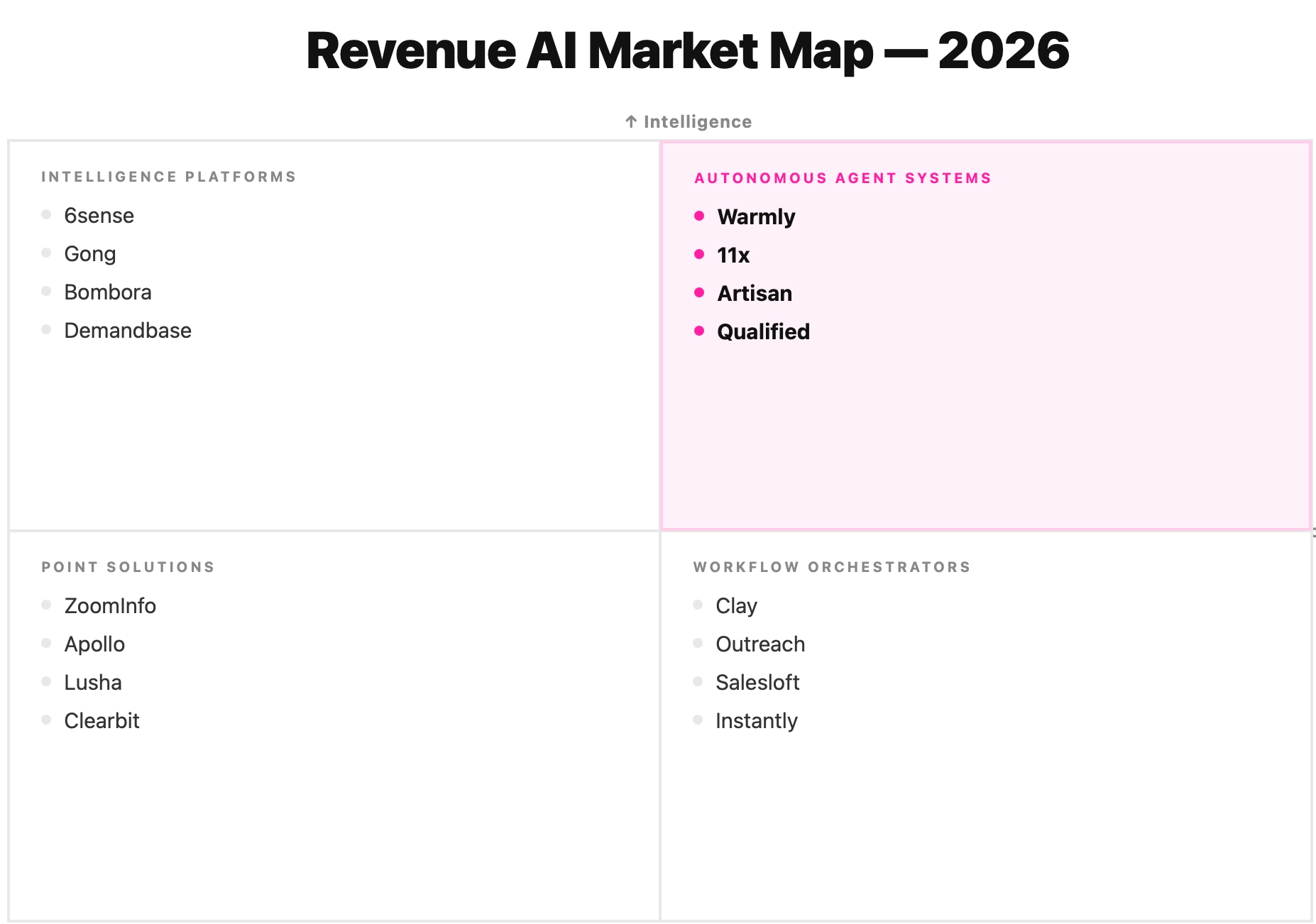
Part I: Meet the Third Wave of Enterprise AI
The First Wave: 2010-2024: Static Workflows, Human-Driven Decisions
The first wave digitized GTM but didn't automate judgment. Salesforce gave us a place to store customer records. HubSpot automated email sequences. Outreach systematized sales cadences. Gong recorded calls. Each tool solved a specific workflow problem. But the human remained the reasoning layer. Software stored data and executed predefined rules. Humans decided which accounts to prioritize, what to say, when to reach out, and how to respond. The tools were productivity multipliers, not decision-makers. This wave created enormous value. It also created enormous complexity. The average enterprise GTM stack now has 30+ tools, each with its own data silo, its own logic, its own view of the customer. Humans became the integration layer, manually stitching context across systems that were never designed to talk to each other. The First Wave asked: "How do we help humans do GTM faster?"The Second Wave would ask a different question.
The Second Wave (2024-2025): Static Data, Information Retrieval
The initial wave of enterprise AI applications targeted verticals with a critical characteristic: there is a right answer and it doesn't change much.
Take these AI vertical applications as examples:
- Legal AI: Harvey raised $300M and is valued at over $1B. Why? Legal precedent is static. Case law from 1954 still applies today. The corpus is fixed. The task is retrieval and synthesis over documents that were written decades ago.
- Code AI: Cursor has become the fastest-growing developer tool in history. Why? Programming languages have formal grammars. Code either compiles or it doesn't. Tests either pass or fail. There's a verifiable ground truth.
- Medical AI: Perhaps the most developed category, with tens of billions flowing into companies tackling physician burnout, operational inefficiencies, and diagnostic accuracy. Abridge alone is worth more than most public SaaS companies. Anatomy doesn't change, drug interactions are catalogued, clinical guidelines are documented.
- Customer Support AI: Sierra is winning this category by building AI agents that handle inquiries, resolve issues, and escalate appropriately. The problem space is bounded: product documentation is fixed, common issues follow patterns, resolution paths are well-defined.
- Recruiting AI: Mercor is winning here through AI that screens candidates, conducts assessments, and matches talent to roles. Job requirements are structured, skills are enumerable, candidate evaluation follows established frameworks.
These companies are creating enormous value. But notice what they all have in common: The answer key exists. The corpus is stable. The task is pattern matching.
The AI doesn't need to learn how medicine, law, coding, support, or recruiting works in real-time. It needs to retrieve and reason over information that was true yesterday and will be true tomorrow.
This is why RAG (Retrieval-Augmented Generation) became the dominant architecture. It works beautifully when:
- The answer exists somewhere in your corpus
- The corpus doesn't change much
- Retrieval quality is the binding constraint
But what happens when none of these conditions hold?
The Third Wave (2026-2027): Dynamic Environments, Continuous Learning
The next frontier of AI isn't information retrieval. It's dynamic reasoning in environments where the answer key is always changing.
Consider GTM (Warmly’s space):
- Your ICP shifts as your product evolves
- Competitive positioning changes quarterly
- Buyer personas vary by segment and market condition
- What worked last quarter may not work this quarter
- Every deal is different, and every company's GTM motion is unique
Bluntly put: the world changes.
The "right" answer depends on context that didn't exist six months ago. The model needs to learn continuously from outcomes, not just retrieve from documents.
The companies that win this wave will build something fundamentally different: not AI that retrieves answers, but AI that develops judgment through continuous interaction with dynamic environments.
What Palantir Understood First
Before LLMs, Palantir competed with Snowflake and Databricks on data infrastructure. The market saw them as enterprise data platforms, expensive, complex, government-focused.
Post-LLMs, Palantir no longer believes they have any competitors.
Why? Because they made a different architectural bet.
Snowflake and Databricks optimized for SQL and query throughput: get raw data into tables, run fast analytical reads, ship dashboards and models on top. They built infrastructure for answering questions about data.
Palantir built an ontology, a world model where data is represented as objects, relationships, and properties. Nouns, verbs, adjectives. Named entities, typed relationships, constraints. Not tables and joins, but the way humans actually think about their domain.
When LLMs arrived, this ontology became the perfect interface. Models don't want a trillion rows. They want a structured, language-shaped substrate: something you can linearize into a coherent prompt, traverse, and act on.
The results speak for themselves with Palantir: 30%+ year-over-year growth accelerating, 50%+ growth in U.S. Commercial, one of the fastest-growing enterprise software stocks.
The market is recognizing something important: ontology beats query optimization when AI is the consumer of your data. It allows AI to reason over your business the way humans actually think about it—not as tables and joins, but as entities, relationships, and meaning.
Palantir proved the thesis. Now the question is: who builds the ontology for each vertical?
The Two Clocks Problem
To understand why existing GTM tools can't fill this gap, you need to understand a fundamental architectural limitation. As Kirk Maple points out, every system has two clocks:
- The State Clock: what's true right now
- The Event Clock: what happened, in what order, with what reasoning
We've already built trillion-dollar infrastructure for the State Clock:
- Salesforce knows the deal is "Closed Lost"
- Snowflake knows your ARR
- HubSpot knows the contact's email.
The Event Clock barely exists.
Consider what your CRM actually knows about a lost deal:
- The state: Acme Corp, Closed Lost, $150K, Q3 2025
- What's missing: You were the second choice. The winner had one feature you're shipping next quarter. The champion who loved you got reorganized two weeks before the deal died. The CFO had a bad experience with a similar vendor five years ago, information that came up in the third call but never made it into any system.
This pattern is everywhere in GTM:
- The CRM says "closed lost." It doesn't say you were one executive meeting away from winning until their CRO got fired.
- The opportunity shows a 20% discount. It doesn't say who approved the deviation, why it was granted, or what precedent it set.
- The sequence shows 47% reply rate. It doesn't say that every reply came from companies with a specific tech stack you've never documented.
- The account is marked "churned." It doesn't say the champion left, the new VP has a competing vendor relationship, and the budget got reallocated to a different initiative.
The reasoning connecting observations to actions was never treated as a recordable table in a spreadsheet. It lived in heads, Slack threads, deal reviews that weren't recorded, and the intuitions of reps who've since left.
The Fragmentation Tax
Every organization pays a hidden cost for this missing layer. We call it the fragmentation tax: the expense of manually stitching together context that was never captured in the first place.
Different functions use different tools, each with its own partial view of the same underlying reality:
- Sales lives in Salesforce
- Marketing lives in HubSpot or Marketo
- Support lives in Zendesk or Intercom
- Product lives in Amplitude or Mixpanel
- Leadership lives in spreadsheets and dashboards
When a rep needs the full picture of an account, they open six tabs, cross-reference timestamps, ping three colleagues on Slack, and piece together a narrative that will be forgotten by next week.
The fragmentation tax compounds. As organizations scale, the tax grows faster than headcount. As AI automation scales, the tax becomes the binding constraint, because agents inherit the fragmentation of the systems they query.
Why This Matters for AI Agents
This gap didn't matter when humans were the reasoning layer. The organizational brain was distributed across human heads, reconstructed on demand through conversation.
Now we want AI systems to make decisions, and we've given them nothing to reason from.
We're asking models to exercise judgment without access to precedent. It's like training a lawyer on verdicts without case law. The model can process information, but it can't learn from how the organization actually makes decisions.
Data warehouses were built to answer "what happened?" They receive data via ETL after decisions are made. By the time data lands in a warehouse, the decision context is gone.
Systems of record were built to store current state. The CRM is optimized for what the opportunity looks like now, not what it looked like when the decision was made. When a discount gets approved, the context that justified it isn't preserved.
AI agents need something different. They need the event clock, the temporal, contextual, causal record of how decisions actually get made.
The Memory Problem: Why LLMs & RAG Can't Do This Alone
Even the most powerful AI models have a fundamental limitation: they can't remember.
LLMs process text in units called tokens. Every model has a maximum context window—the total number of tokens it can “see” at once. GPT-5.2 supports ~400K tokens, Claude 3.5 Sonnet supports ~200K tokens, and Google’s Gemini 2.0 supports up to 1 million tokens.
This sounds like a lot. It isn't.
A single week of GTM activity for a mid-market company might include:
- 50,000 website visits with behavioral data
- 10,000 email sends and responses
- 500 call transcripts (averaging 5,000 words each)
- 2,000 CRM activity records
- 1,000 Slack threads about deals
- Thousands of enrichment data points
That's easily 10-50 million tokens, 100x more than even the largest context windows.
When context overflows, models either drop it (truncation) or compress it (summarization). Both approaches degrade the model's ability to learn from precedent, recognize patterns, make consistent decisions, and build institutional memory.
RAG (Retrieval-Augmented Generation) is the standard workaround: store documents externally, retrieve relevant chunks, stuff them into context. RAG works for static domains like legal research.
RAG fails for GTM because:
- The "relevant" context isn't obvious in advance. When deciding whether to prioritize Account A vs Account B, the retrieval problem is as hard as the decision problem itself.
- Temporal relationships matter. RAG retrieves documents, not timelines. It can't answer "did her engagement increase or decrease over the past month?"
- Identity resolution isn't automatic. RAG finds documents mentioning "S. Chen" and "Sarah" and "@sarah" and "schen@acme.com" but doesn't know they're the same person.
- Synthesis requires structure. Reasoning requires knowledge graphs, not document chunks.
- Features must be computed, not retrieved. "This account has 3+ buying committee members who visited the pricing page in the last 7 days" isn't a document to retrieve. It's a computation over structured data.
This is why the GTM Brain exists.
We're not replacing LLMs, we're giving them persistent, structured memory they can't build themselves.
The LLM brings reasoning. We bring memory.
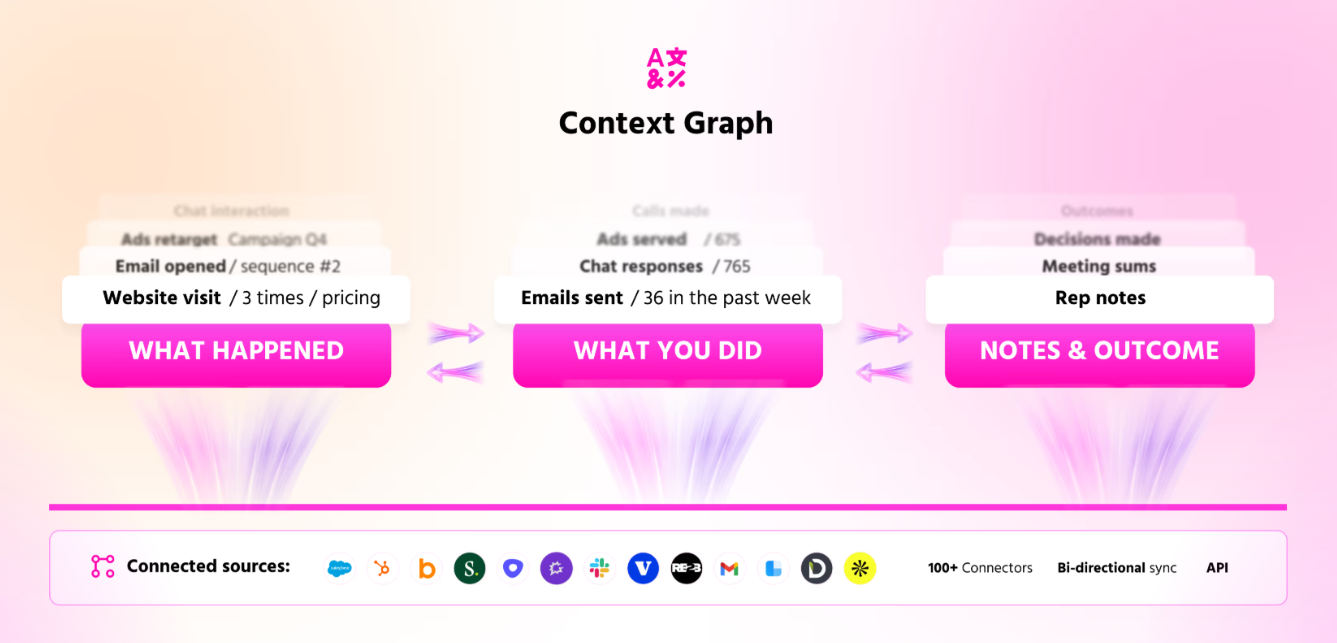
GTM Needs A Context Graph, not RAG
Foundation Capital recently argued that the next trillion-dollar platforms won't be built by adding AI to existing systems of record, they'll be built by capturing decision traces, the reasoning that connects data to action.
They call this the context graph: a living record of decision traces stitched across entities and time, so precedent becomes searchable.
This insight is exactly right. But it's incomplete.
You can't capture decision traces without first solving the operational context problem inherent to GTM: identity resolution, entity relationships and temporal state (the substrate that makes decision graphs possible).
And you can't build a general-purpose context graph that works for every domain. The companies that win will build domain-specific world models that encode how their particular category actually works.
For GTM, that means building a system that understands not just what happened, but why buyers buy, why deals die, what signals predict action, and how to allocate scarce resources against infinite opportunities.
That's what Warmly is building: the GTM Brain made up of a Context Graph.
Part II: Background - The Need For a New Kind of Learning in GTM
There's a reason Tesla's Full Self-Driving is the most instructive analogy for what we're building.
Like GTM, driving is a domain where:
- The environment is dynamic and unpredictable
- There's no static answer key, every situation is unique
- Decisions must be made in real-time under uncertainty
- The "right" action depends on context that changes constantly
- Human judgment is the baseline to beat
Tesla's approach to this problem offers a blueprint for building AI systems in dynamic domains.
Imitation Learning: Watching Humans Do the Work
Tesla's breakthrough wasn't building better sensors or more powerful computers. It was imitation learning at scale.
Here's how it works:
- Observe: Millions of Tesla vehicles capture how humans actually drive, like steering inputs, braking patterns, lane changes, reactions to unexpected events.
- Model: Neural networks learn to predict what a human driver would do in any given situation. Not what a rule-based system says they should do, but what they actually do.
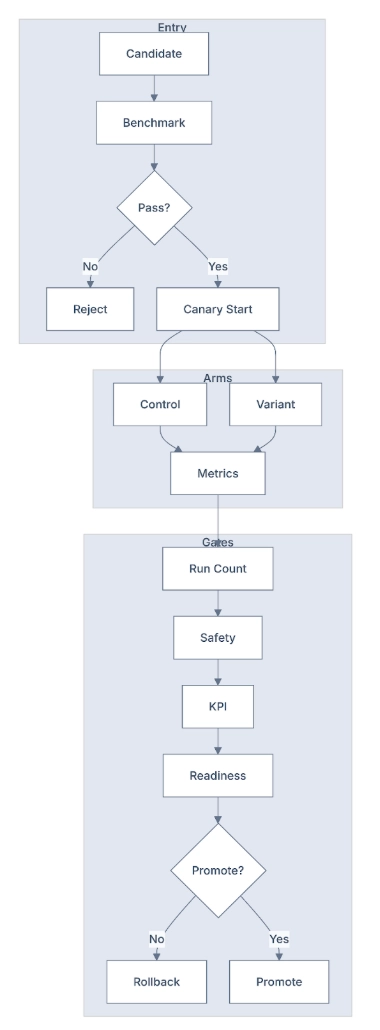
- Simulate: Tesla built a massive simulation environment where AI can practice billions of driving scenarios without risk.
- Refine: When the AI makes a mistake in the real world, that edge case gets added to the training data. The system continuously improves.
- Verify: Before deploying updates, Tesla runs shadow mode, the AI makes decisions in parallel with human drivers, and the system compares outcomes.
The key insight: you don't program driving rules. You learn them from the accumulated experience of millions of human drivers.
World Models: The Simulation Advantage
Tesla calls this learned representation a "world model." In GTM, we call ours the Context Graph: a living record of entities, relationships, decision traces, and temporal facts that enables AI to reason about your market the way experienced sellers actually think about it.
The world model enables simulation, prediction, and crucially, counterfactual reasoning. What would have happened if I had braked earlier? If I had changed lanes? This is how the system learns from near-misses, not just crashes.
The GTM Parallel
A GTM Brain using a context graph would apply the same architecture:
- Observe: Ingest every signal from the GTM environment like website visits, email engagement, CRM activities, call transcripts, product usage. Watch what human sellers do in response to these signals.
- Model: Learn the patterns that predict success. Which signals indicate buying intent? Which messaging resonates with which personas? Which accounts look like your best customers?
- Simulate: Before committing resources to an account, simulate the likely outcomes. What's the probability of conversion? What's the expected deal size? What's the optimal engagement strategy?
- Refine: When deals close or die, capture the outcome and feed it back into the models. Learn from every success and failure.
- Verify: Run the AI's recommendations in shadow mode against human judgment. Measure accuracy. Improve.
Just as Tesla doesn't hand-code driving rules, we don't hand-code GTM rules. We learn them from the accumulated experience of thousands of deals.
Why This Approach Wins
The imitation learning approach has three structural advantages over rule-based systems:
- It handles complexity that can't be specified. Driving has millions of edge cases. You can't write rules for all of them. But you can learn from how humans handle them. GTM is the same. Every company has unique dynamics. Every buyer is different. Every deal is shaped by context that's impossible to anticipate. The only way to handle this complexity is to learn from experience.
- It improves continuously. Rule-based systems are static. Learning systems improve with use. Every mile driven makes Tesla's AI better. Every deal processed makes the GTM Brain smarter. The system compounds.
- It captures tacit knowledge. The best human sellers have intuition that they can't articulate. They "just know" which deals are real and which are tire-kickers. They "just know" when a champion is losing internal support.
This tacit knowledge is embedded in their behavior, even if they can't explain it. Imitation learning captures it by observing what experts do, not what they say.
Part III: Enter the GTM Brain (from LLM + RAG to Context Graph) - what Warmly.ai is building
Beyond RAG: A GTM-Native Context Graph
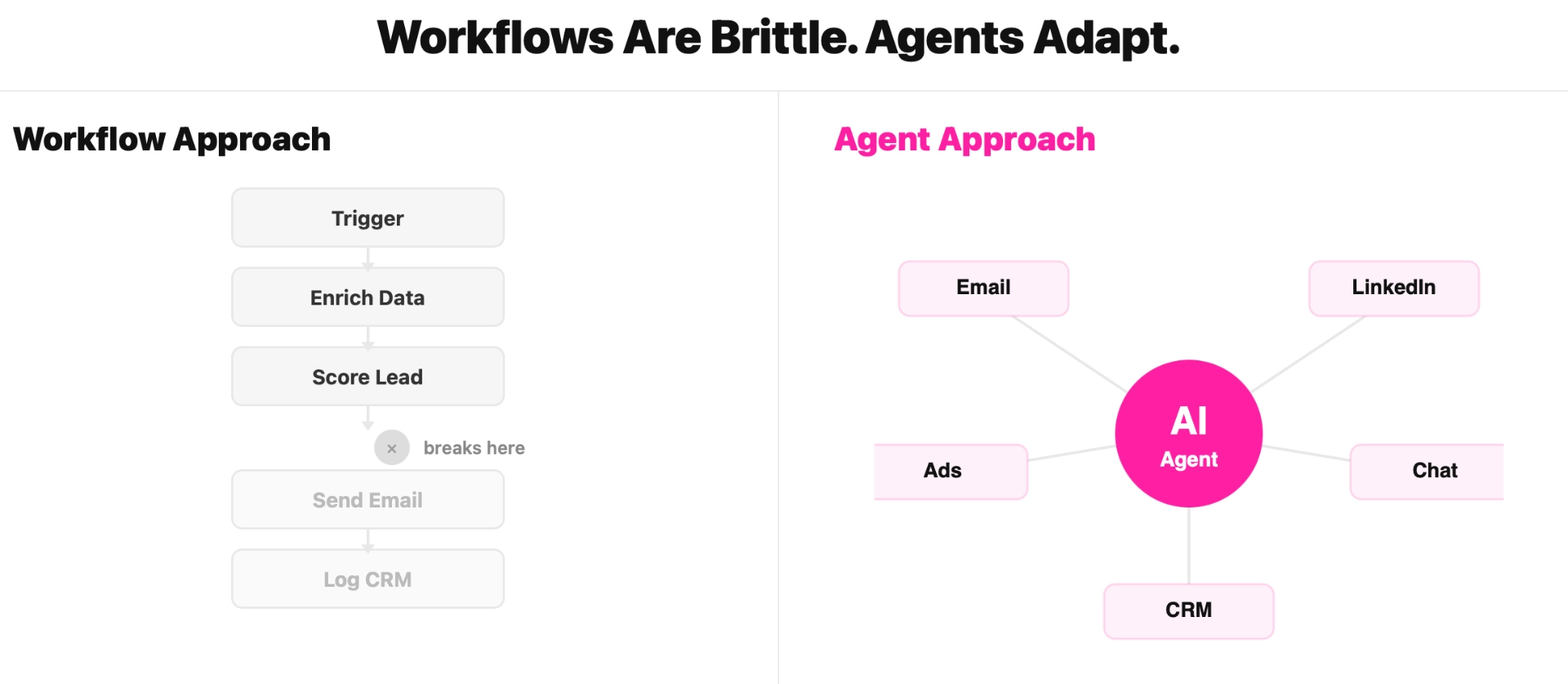
What the market needs is not an AI wrapper. Not another chatbot or "AI for your CRM." It needs a stateful GTM decision system that:
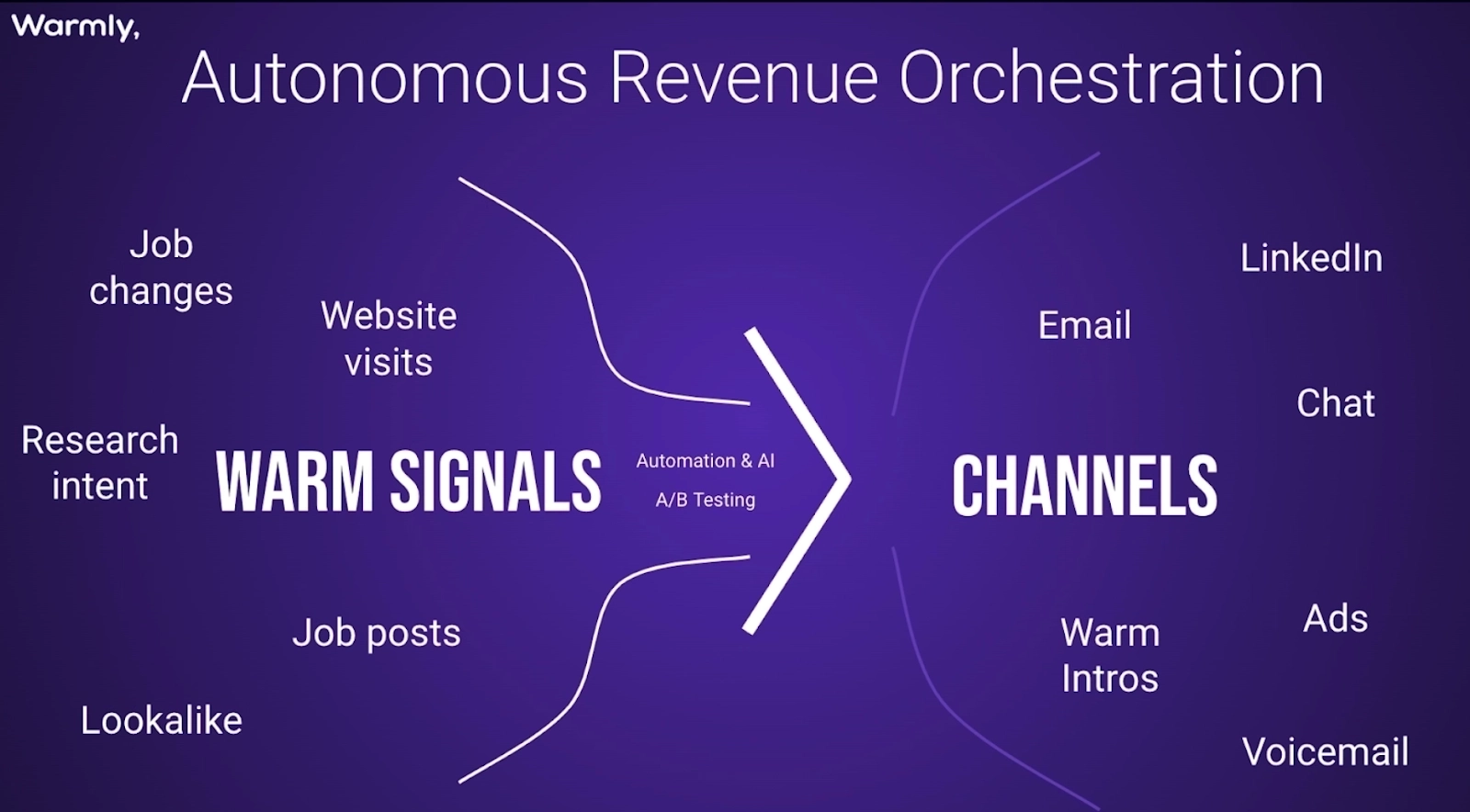
- Ingests millions of buyer signals (website, CRM, product, intent, social)
- Resolves people and companies across tools using a proprietary identity graph
- Builds a temporal context graph of your market, an ontology of entities, relationships, and facts custom-tailored to each company
- Computes mathematically grounded probabilities and expected values for every account and contact
- Exposes a Human Strategy Layer so leaders can steer the system
- Decides what to do next (or not do) under real constraints
- Orchestrates agents across web research, enrichment, buying committee mapping, inbound, outbound, and response
- Continuously improves itself via backtesting and simulation
It replaces both the GTM software stack and a large portion of the GTM people stack (e.g. SDRs, RevOps, Marketing Ops, researchers, analysts) with a single, self-learning engine.
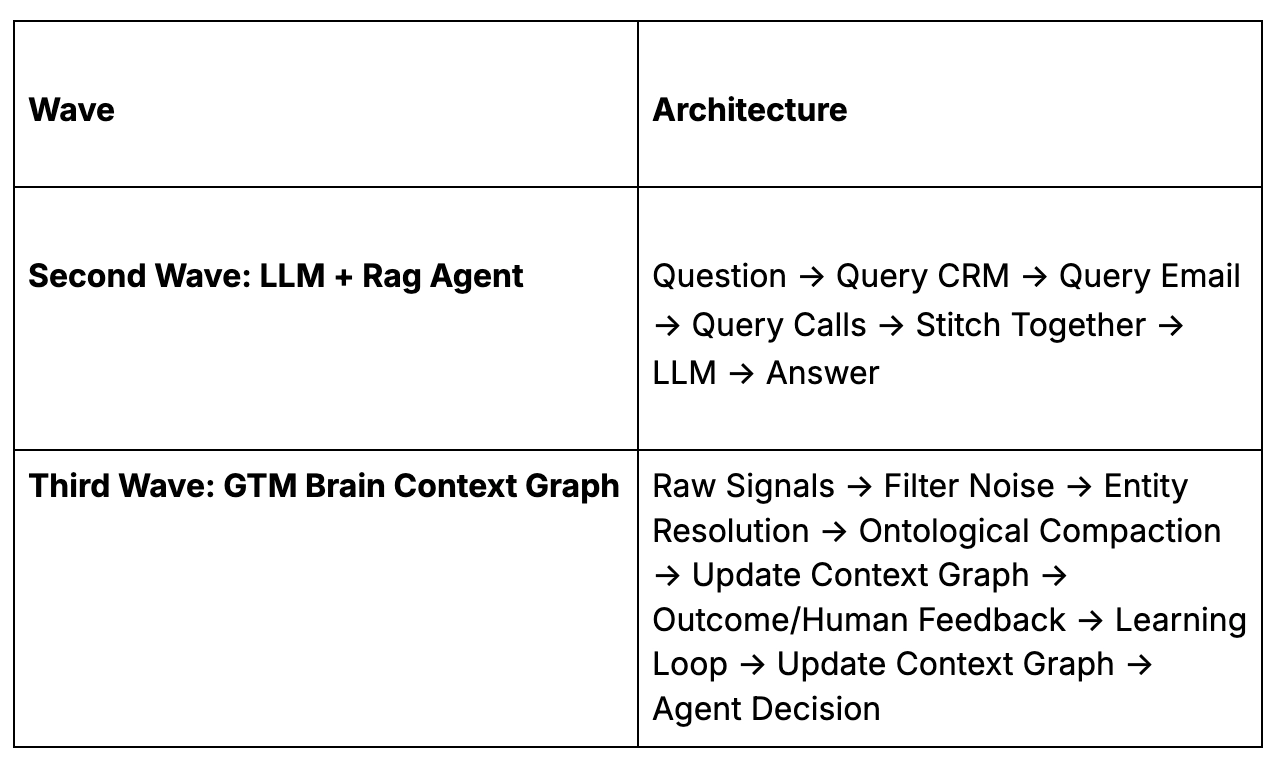
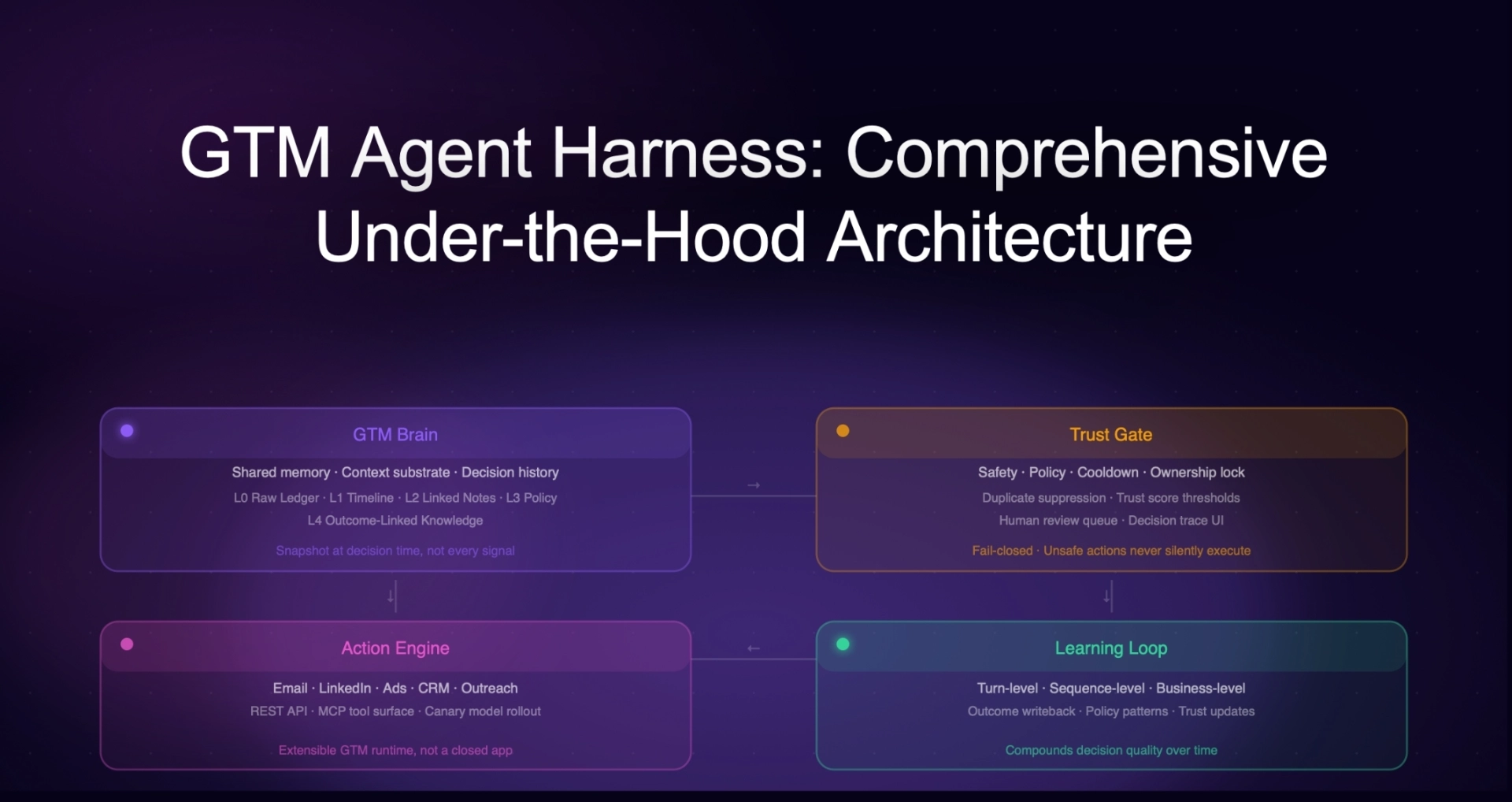
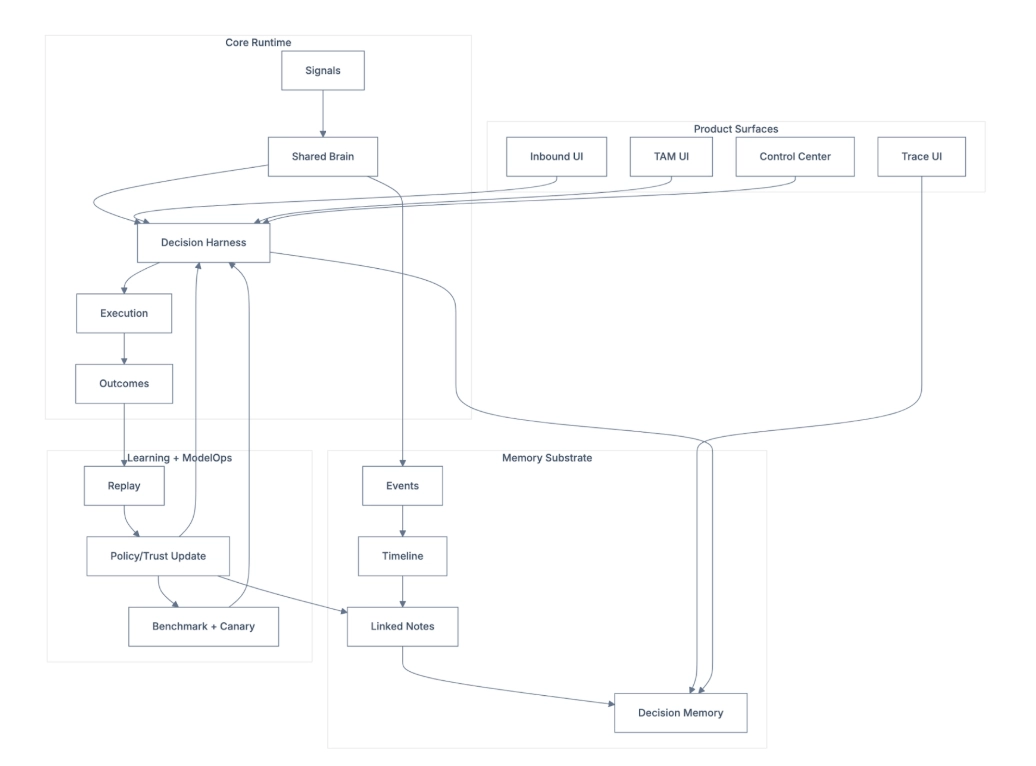
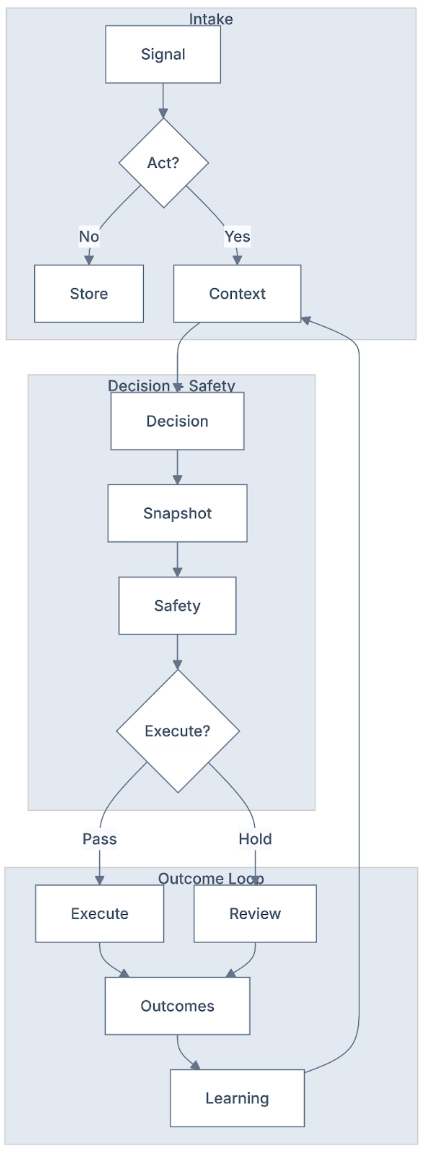
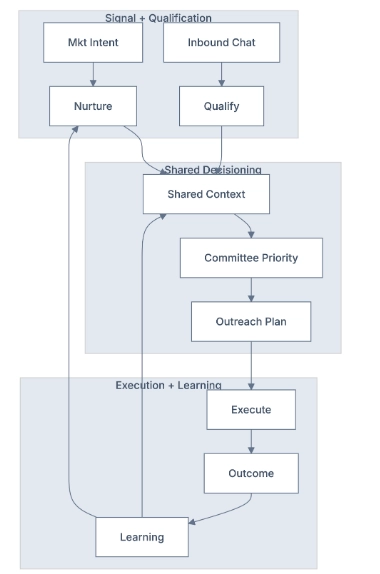
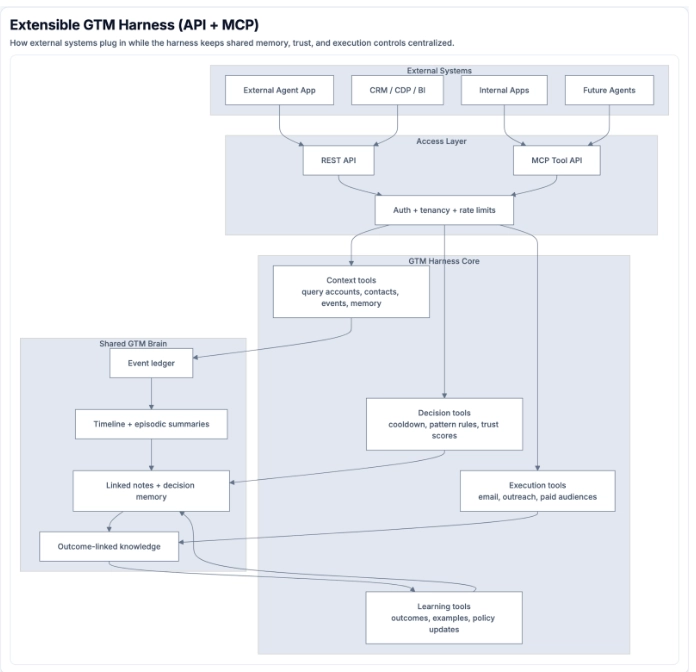
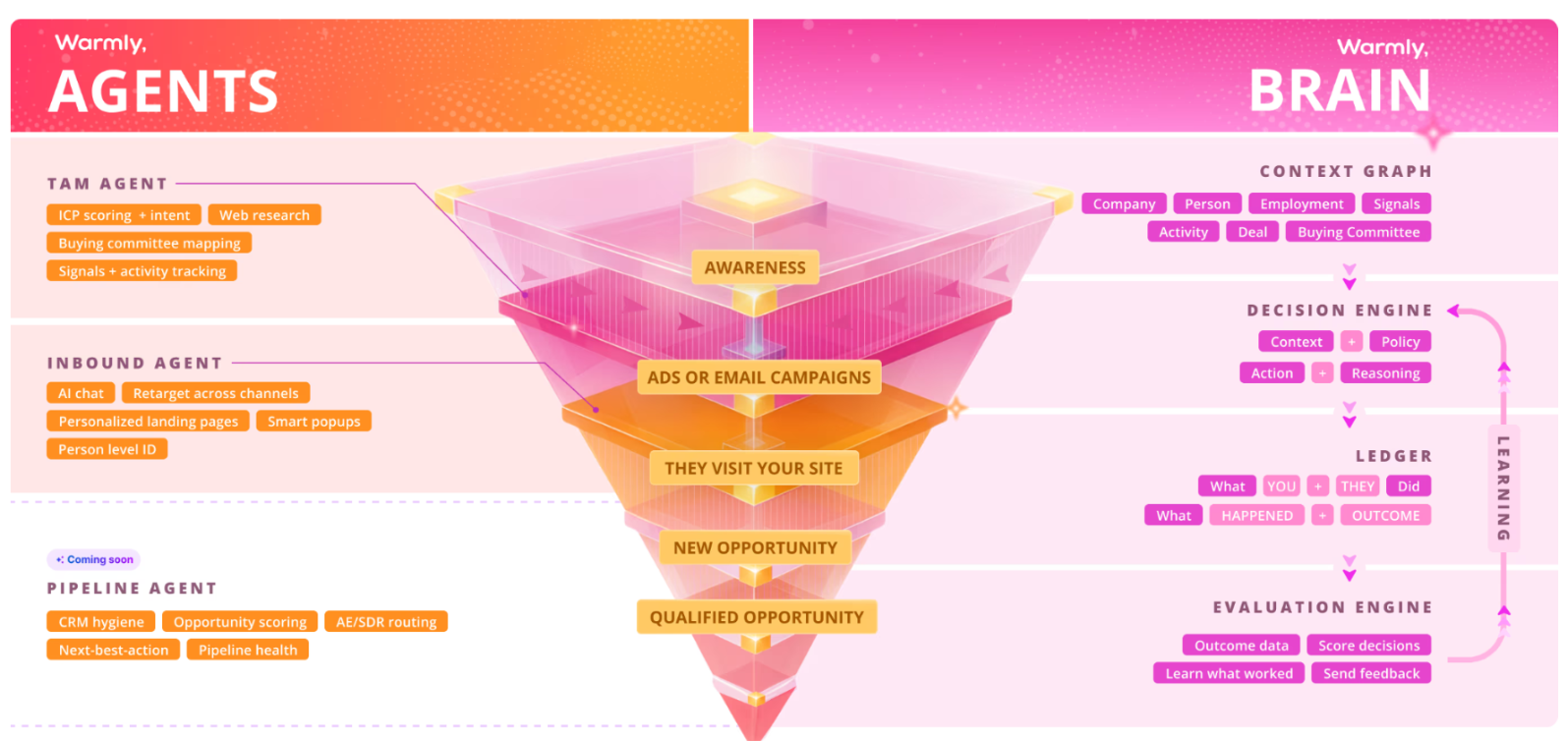
The OODA+L Architecture
The GTM Brain operates as a closed-loop system:
- Observe: Raw GTM events and data flow in continuously, like website visits, CRM activities, email engagement, product usage, intent signals, people moves, firmographics.
- Orient: The system maintains a world model, an ontology of companies, contacts, signals, segments, and plays. Features are computed. Models generate predictions.
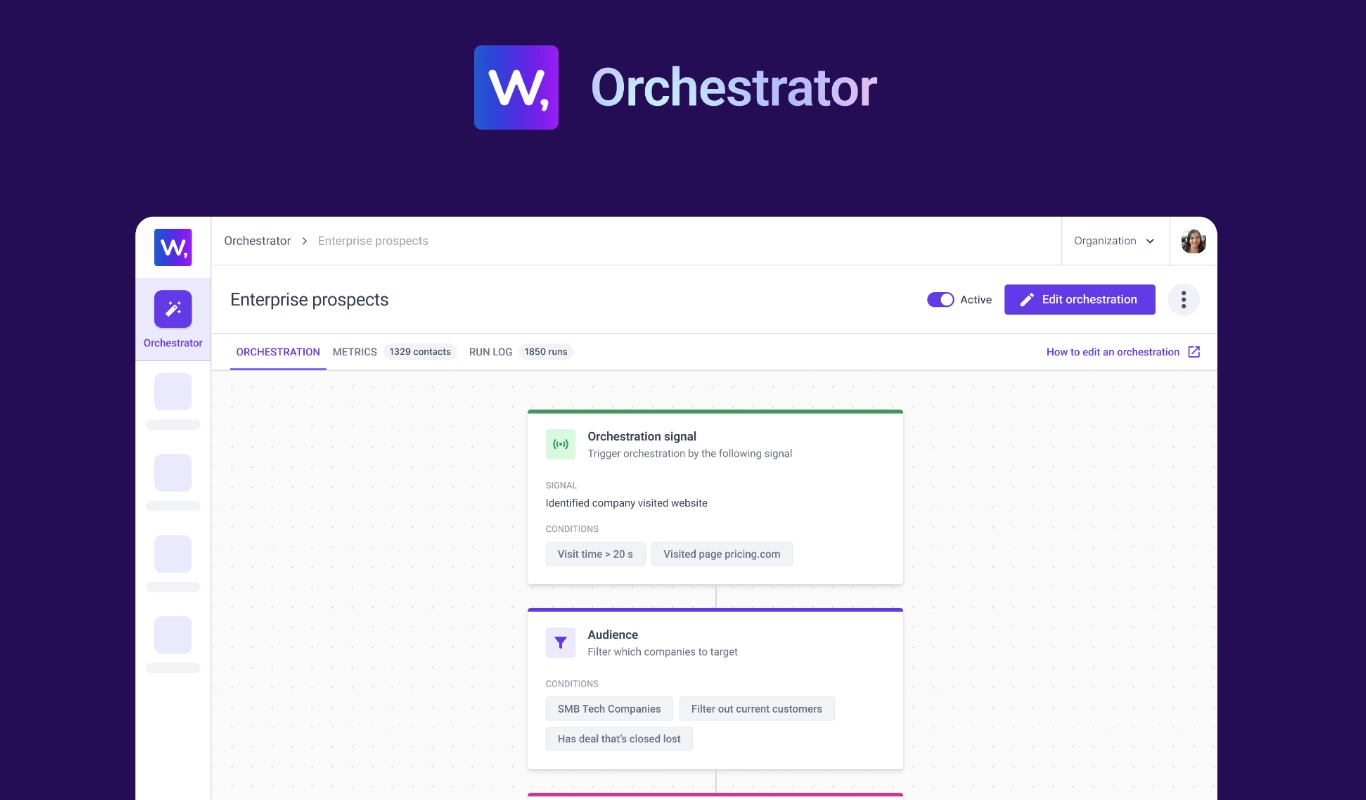
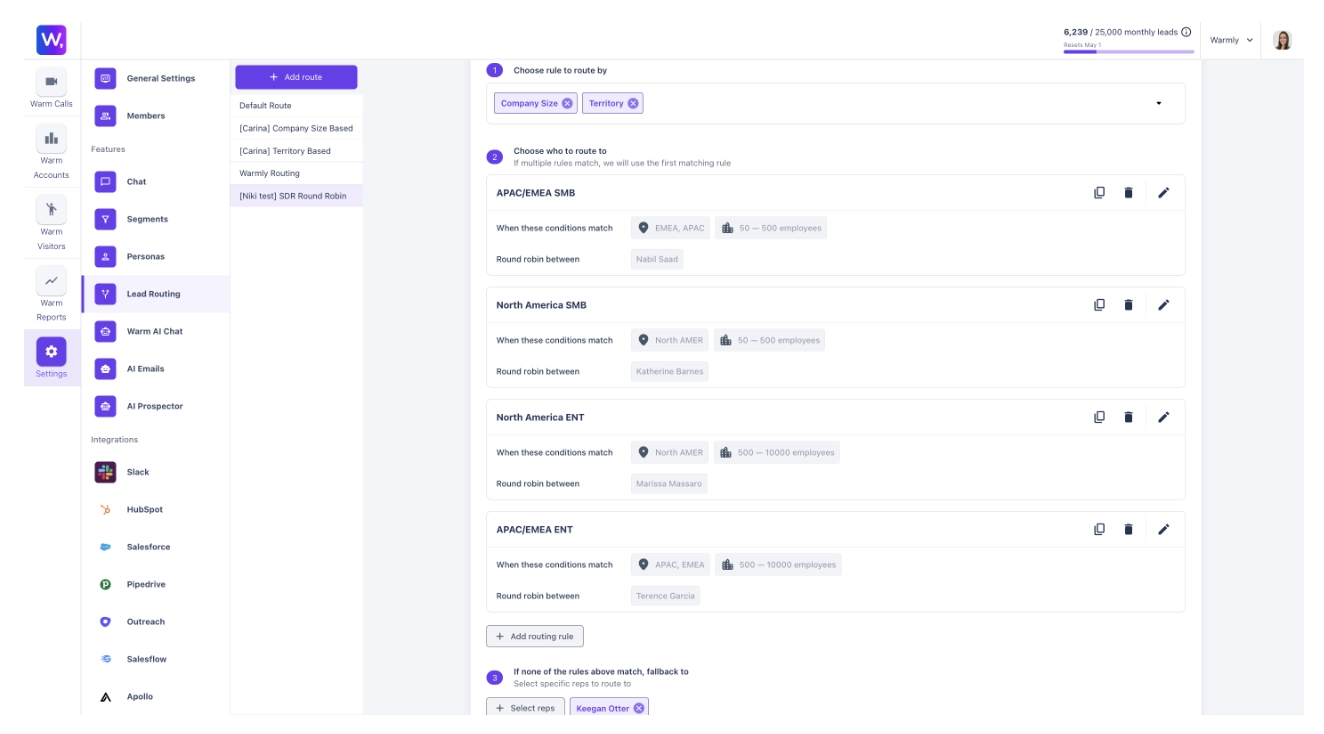
- Decide: The Policy Layer maps state to actions (including the decision to do nothing) under real constraints (e.g. inbox limits, ad budgets, AE capacity, brand fatigue)
- Act: Agents execute work such as research, enrichment, buying committee mapping, inbound chat, outbound sequences, response handling.
- Learn: Every outcome feeds back into the system. Models improve. Policies adapt. The world model expands.
The Architecture Split
This system has a clear separation of concerns that makes it structurally different from pure LLM approaches:
- Models compute: State, weights, relationships, readiness, priority (deterministic)
- LLMs narrate: Recommendations, messaging angles, next best action (probabilistic)
- Summary stores remember: "Account XYZ looks like ABC; historically, do this" (persistent)
This matters because LLMs are expensive and weak at real-time sifting across huge context windows. They can't build and condense a world model in real-time. But they're brilliant at reasoning over a world model that's already built.
The GTM Brain stores exactly the right context, primitives that model to the GTM world, rather than asking an LLM to reconstruct context from scratch every time.
Why "GPT Wrappers" Can't Do This
It’s a bit in the weeds but here is the architectural problem that separates production systems from demos using base LLMs:
GPT wrappers try to build context at inference time leading to what we call the “inference time trap”. The agent queries multiple systems, stitches together data, reasons over it, and generates a response, all in one request. This approach has fatal flaws:
- Token consumption: Every request rebuilds context from scratch. Costs explode.
- Latency: Minutes to assemble context before reasoning can start. Real-time use cases become impossible.
- Hallucination: Model fills gaps when data is missing. 80% accuracy isn't acceptable for GTM decisions.
- Inconsistency: Different context windows produce different answers. Same question, different day = different prioritization.
- No learning: Context is discarded after each request. Can't improve from outcomes.
Our approach: pre-compute, store, serve
The context is computed, stored, and summarized ahead of time. When an agent needs to act, whether responding to a chat message or deciding which account to prioritize, it queries pre-computed state, not raw data. The reasoning happens at the edge, fast, with the right context already in memory.
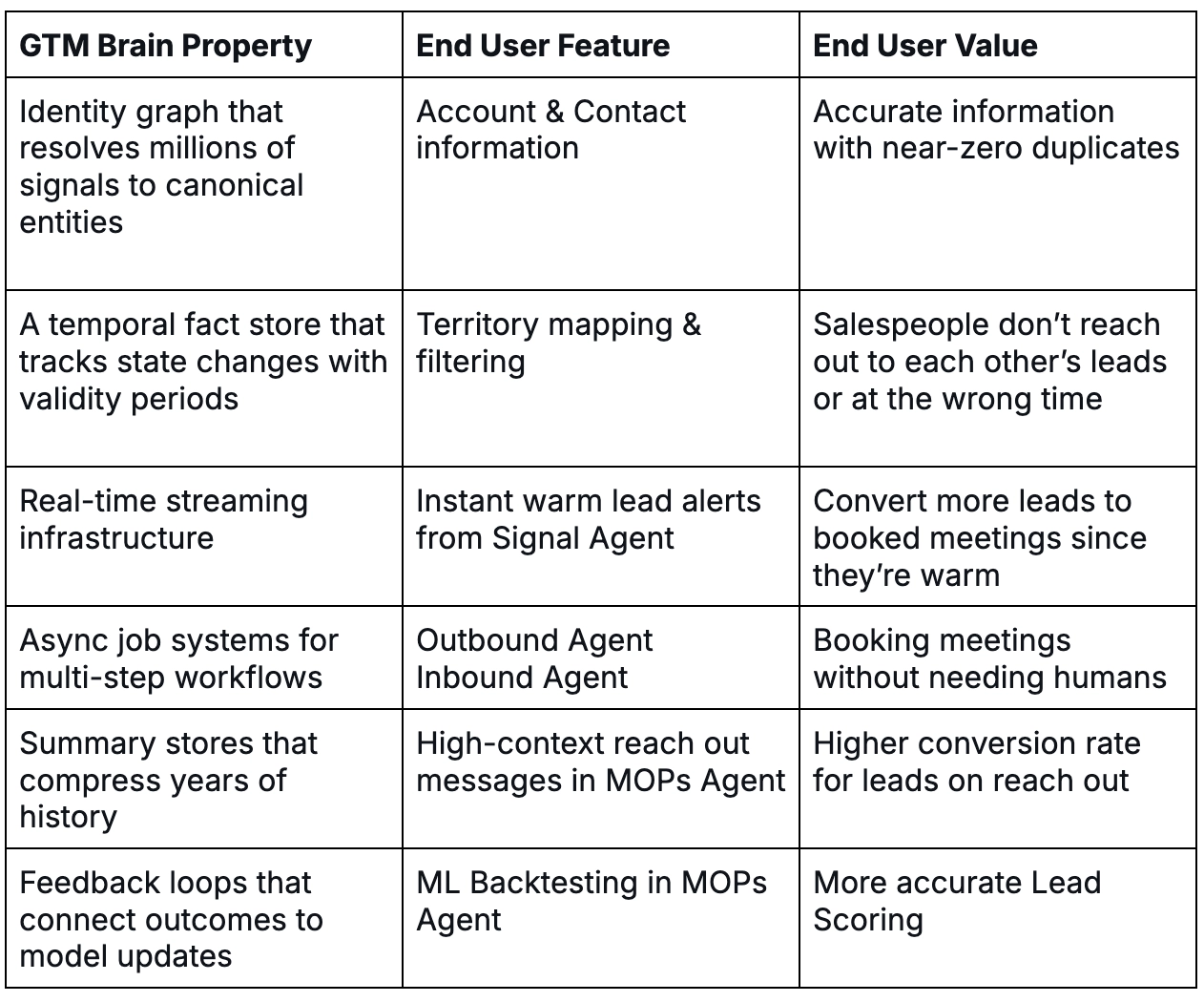
You can't vibe-code this. A weekend hackathon can build a demo that queries your CRM and generates a personalized email. It cannot build an identity graph that resolves millions of signals to canonical entities, a temporal fact store that tracks state changes with validity periods, real-time streaming infrastructure, async job systems for multi-step workflows, summary stores that compress years of history, and feedback loops that connect outcomes to model updates.
This is production infrastructure. It takes years to build and battle-test. But the result is the difference between a prototype that breaks and hallucinates and a production system that closes deals.
The Architecture Difference
How does this compare in practice?
1. Decision Quality
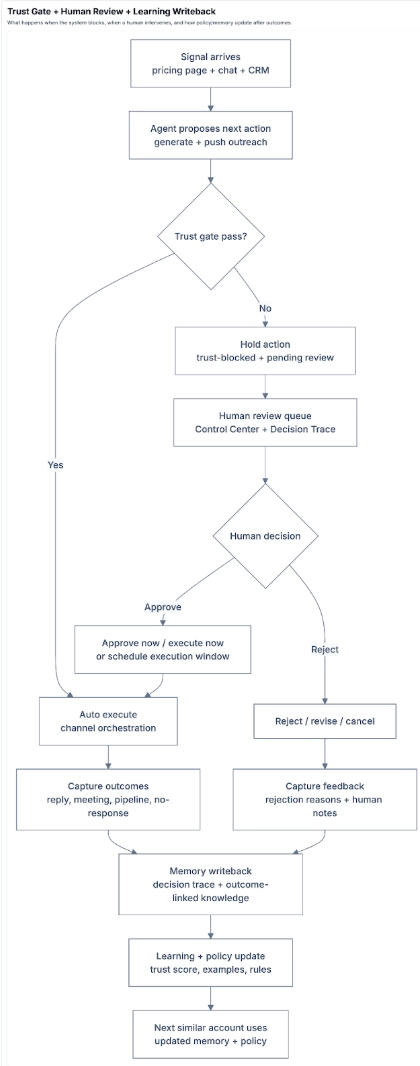
Scenario: Rep asks "Who should I focus on today?"
Normal LLM: "Here are your 47 open opportunities sorted by close date."
GTM Brain: "Focus on Acme Corp. Why: 3 buying committee members visited pricing this week. They look like Omega Inc right before they closed. Beta Inc can wait—their champion is OOO until Thursday."
Impact: Reps spend 80% less time researching, 3x more time in conversations that convert.
2. Learning
Scenario: Deal with TechStart Inc just went "Closed Lost"
Normal LLM: Status updated to "Closed Lost." Nothing else changes. Next similar deal makes the same mistakes.
GTM Brain: System captures: "Lost because champion left 2 weeks before close." Six months later, flags a new deal: "Warning: Champion at CloudCo just updated LinkedIn to 'Open to Work'—same pattern as TechStart loss. Expand to other stakeholders now."
Impact: Deal-killing patterns surface 6 months faster than manual analysis. Mistakes made once are never repeated.
3. Cross-System Temporal Context
Scenario: Rep switching between Gong, CRM, email, and LinkedIn
Normal LLM: Each tool shows siloed data. "Wait, is the Sarah from that Gong call the same Sarah who emailed me?" Rep opens 6 tabs, spends 15 minutes piecing it together.
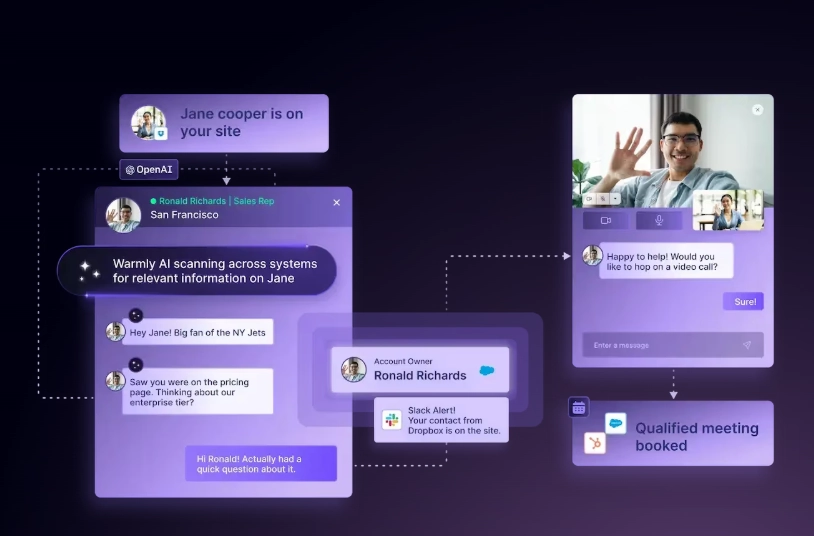
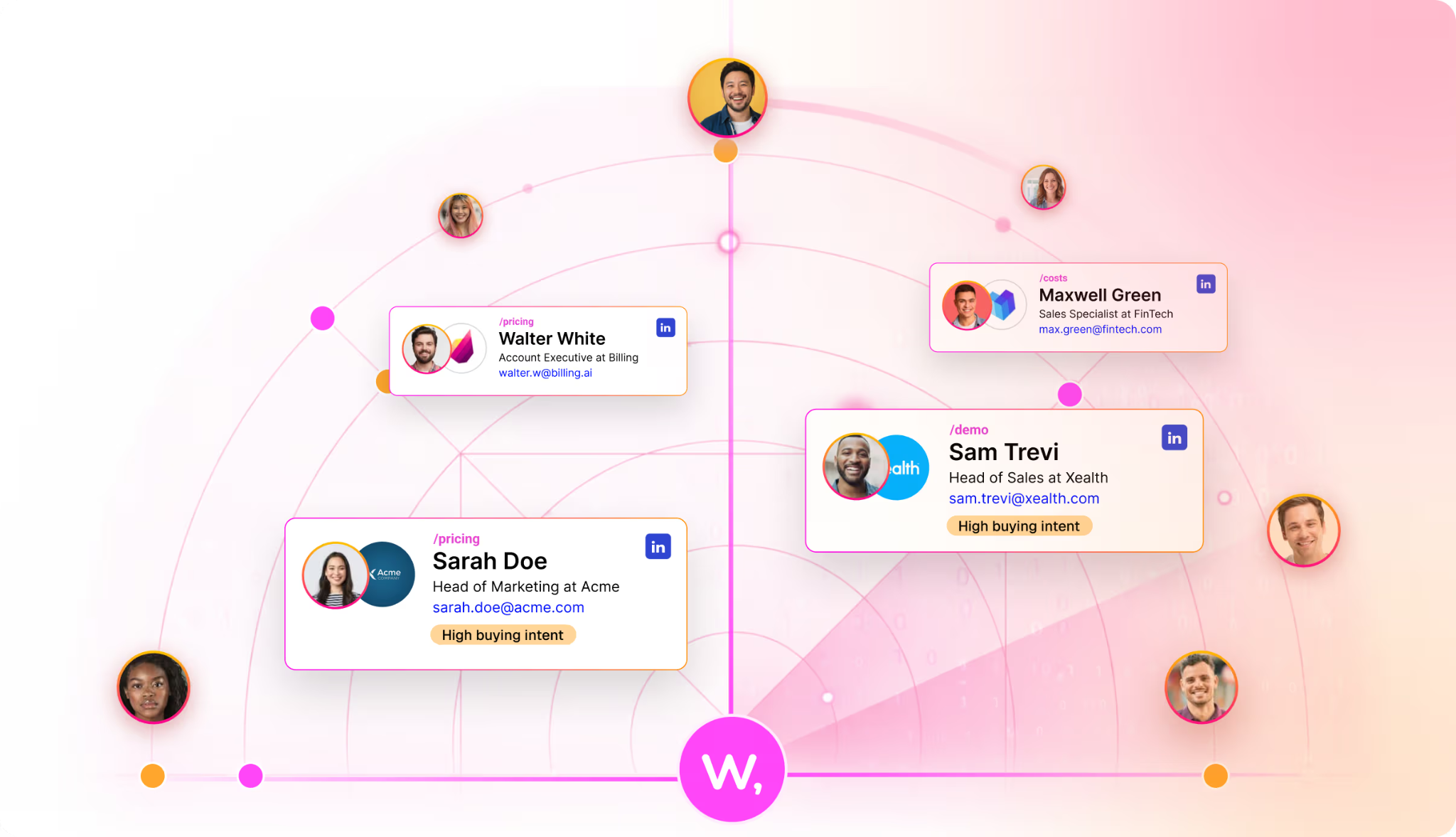
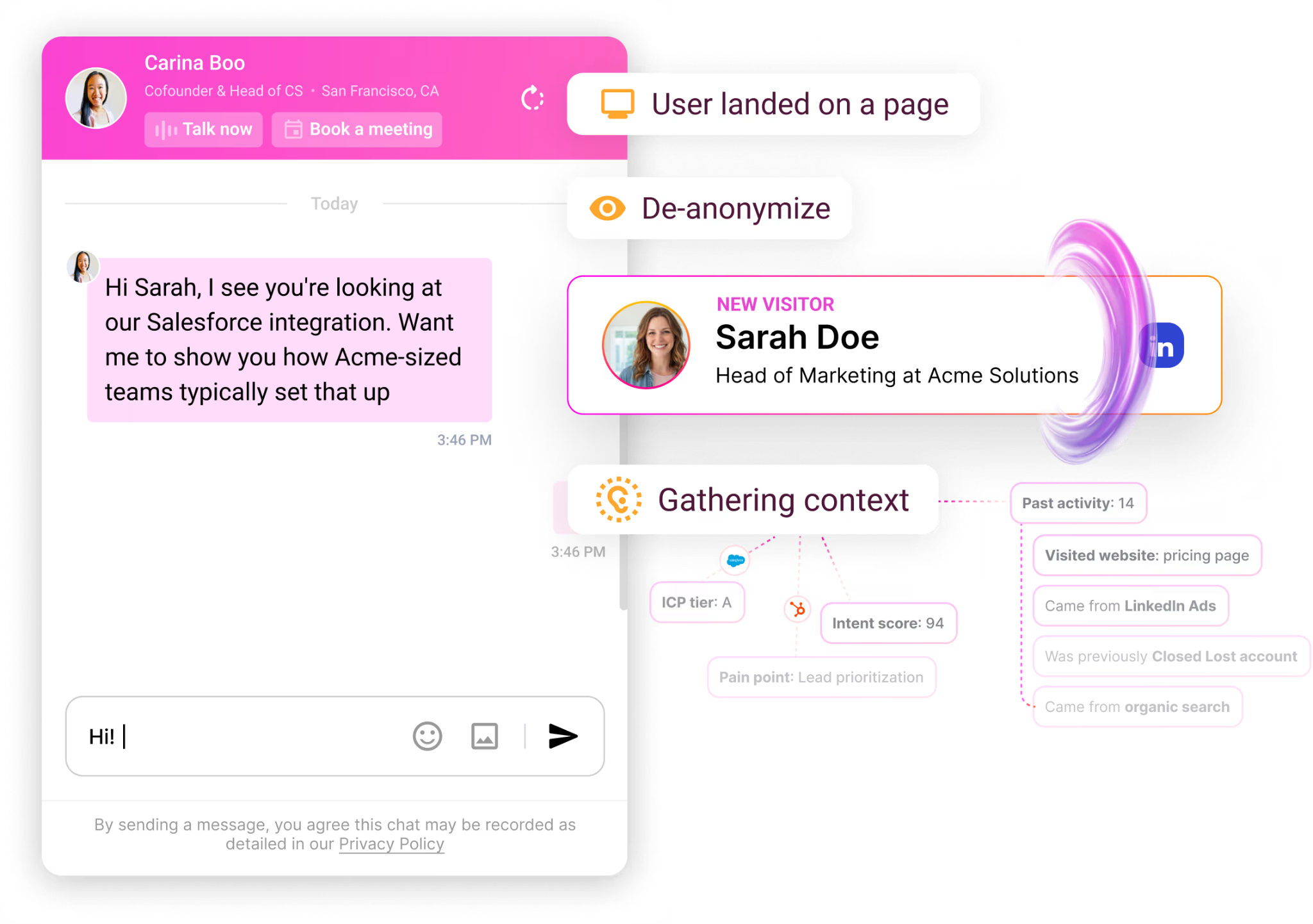
GTM Brain: "Sarah Chen: CFO at Acme. Timeline: Attended webinar (March 3) → Visited pricing (March 10) → Scheduled demo (March 12) → Joined call (March 15) → Asked about SOC2. She's your champion."
Impact: 15 minutes of tab-switching → 0 seconds. Complete context, instantly.
4. Ontological Compaction
Scenario: Account has 100,000 website visits, 5,000 emails, 200 calls over 2 years
Normal LLM: Tries to retrieve raw data. 100,000 visits = millions of tokens. Context window explodes. Falls back to: "Acme has shown interest in your product."
GTM Brain: Compacts into ontological format (~500 tokens) that preserves everything an agent needs to execute flawlessly.
What GTM Brain stores instead of raw data:
Account: Acme Corp: Series B Fintech, 180 employees, SF-based
Buying Committee: Sarah Chen (CFO, Champion), Mike Torres (CTO, Evaluator), Lisa Park (VP Sales, End User)
Intent Signals: Sarah: Pricing 12x, ROI calc 3x. Mike: API docs 8x, Security 5x, asked about SOC2
Intent Score: 87/100 (↑34% this month)
Stage: Evaluation. Similar accounts: 73% convert in 45 days
Key Concerns: Security, Salesforce integration, Pricing
Risks: Single-threaded on Sarah—expand to Mike
Recommended Play: ROI-focused close, address SOC2, send integration doc
Impact: 100,000 raw events → 500 tokens. Fits in context.
5. Temporal Reasoning
Scenario: Rep asks "Should we re-engage TechCorp?"
Normal LLM: "TechCorp is a closed-lost opportunity from 6 months ago."
GTM Brain: "Yes, re-engage. When you lost them in Q2, they had 50 employees and couldn't afford enterprise pricing. They now have 180 employees and just raised Series C. The blocker (budget) is resolved. Your champion Alex is still there."
Impact: Lost deals automatically resurface when conditions change. Pipeline you thought was dead comes back to life.
6. Event Clock
Scenario: Deal marked "Closed Lost" — what actually happened?
Normal LLM (State Clock only): "Acme Corp: Closed Lost. Amount: $150K. Close Date: Q3 2025."
GTM Brain (State + Event Clock): "Lost to Competitor X. You were second choice—they had API webhooks (you're shipping next quarter). Champion Mike got reorged 2 weeks before close. New VP had prior relationship with Competitor X's CEO. Lesson: Identify single-threaded deals earlier."
Impact: Every loss becomes a lesson. Every win becomes a playbook. Institutional knowledge compounds instead of walking out the door.
7. Feedback Loop
Scenario: Your team runs 10,000 sequences this quarter
Normal LLM: Data goes to OpenAI/Anthropic. Their models get smarter. Yours stays the same.
GTM Brain: Every reply, open, click, and conversion feeds back into YOUR model. "Sequences mentioning competitor X convert 30% better in enterprise." Your system improves. Theirs doesn't see your data.
Impact: Your GTM intelligence is proprietary. Competitors can copy features. They can't copy the accumulated decision intelligence inside your context graph.
The 100% Precision Primitive
Here's the insight that separates Warmly from everything else in the market:
When you want to automate GTM for B2B, it can't be 80% right. It needs to be 100% right, or at least better than a human, for full automation to be possible.
For example, GTM workflows are pipelines. Each step depends on the previous step being correct. If you have five steps in your automation, identity resolution, company enrichment, ICP matching, intent scoring, message personalization, and each is 80% accurate, your end-to-end accuracy isn't 80%. It's:
0.8 × 0.8 × 0.8 × 0.8 × 0.8 = 32.8%
And 32.8% sucks!
Two-thirds of your fully automated outreach is wrong in some meaningful way.
Now consider what "wrong" means at each step:
- Wrong Email: Email bounces or reaches wrong person
- Wrong enrichment: They changed jobs and work at a different company now
- Wrong ICP match: They work at a government company when you don’t sell to government
- Wrong Intent: You de-anonymized the wrong person
- Wrong personalization: You sent generic outreach messages that get instantly dropped in the spam folder
This is why every primitive must work at production quality before composition is possible.
Production demands 99% or more, and that last stretch can take 100x more work.
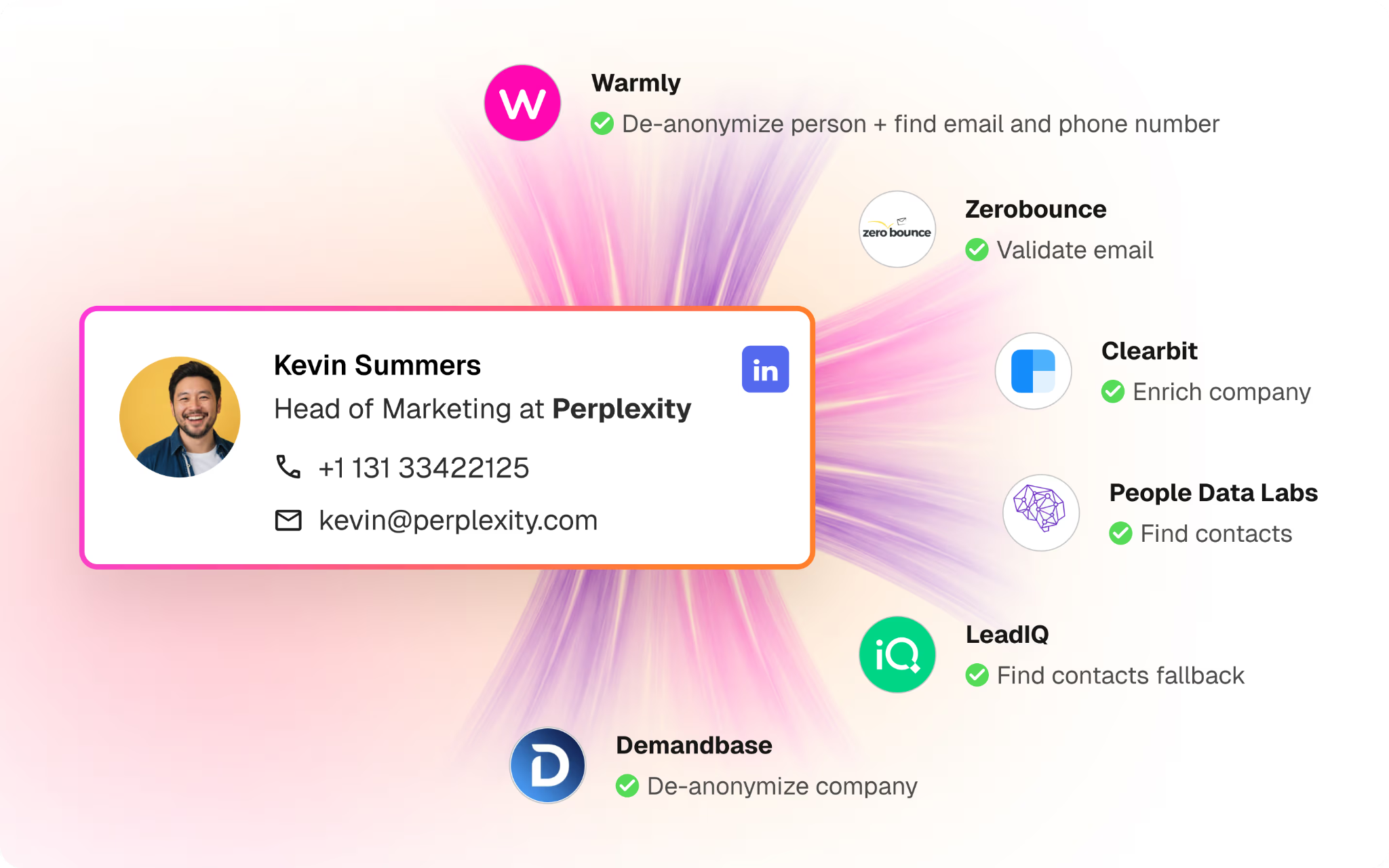
So we build primitives, identity resolution, buying committee mapping, signal scoring, account prioritization, entity extraction, temporal reasoning, each designed to accomplish specific tasks with near-perfect precision.
These primitives are then composed into end-to-end workflows. When each component works at production quality, the whole system can run autonomously.
Part IV: The GTM Brain Advantage - The 3 Layers
The ultimate vision for the GTM Brain is to become what Palantir built for government intelligence: a context graph where data is represented the way humans actually reason about it, as entities, relationships, and temporal facts, not tables and joins.
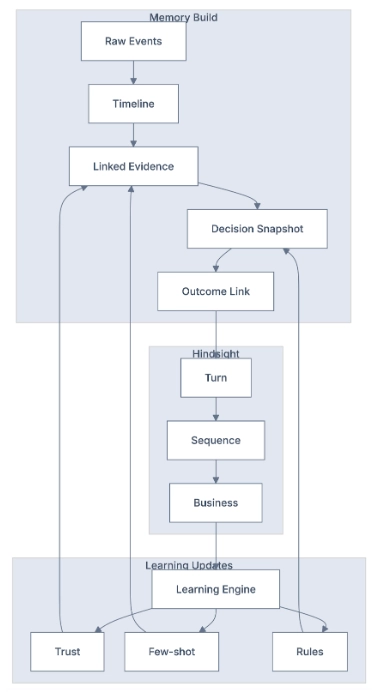
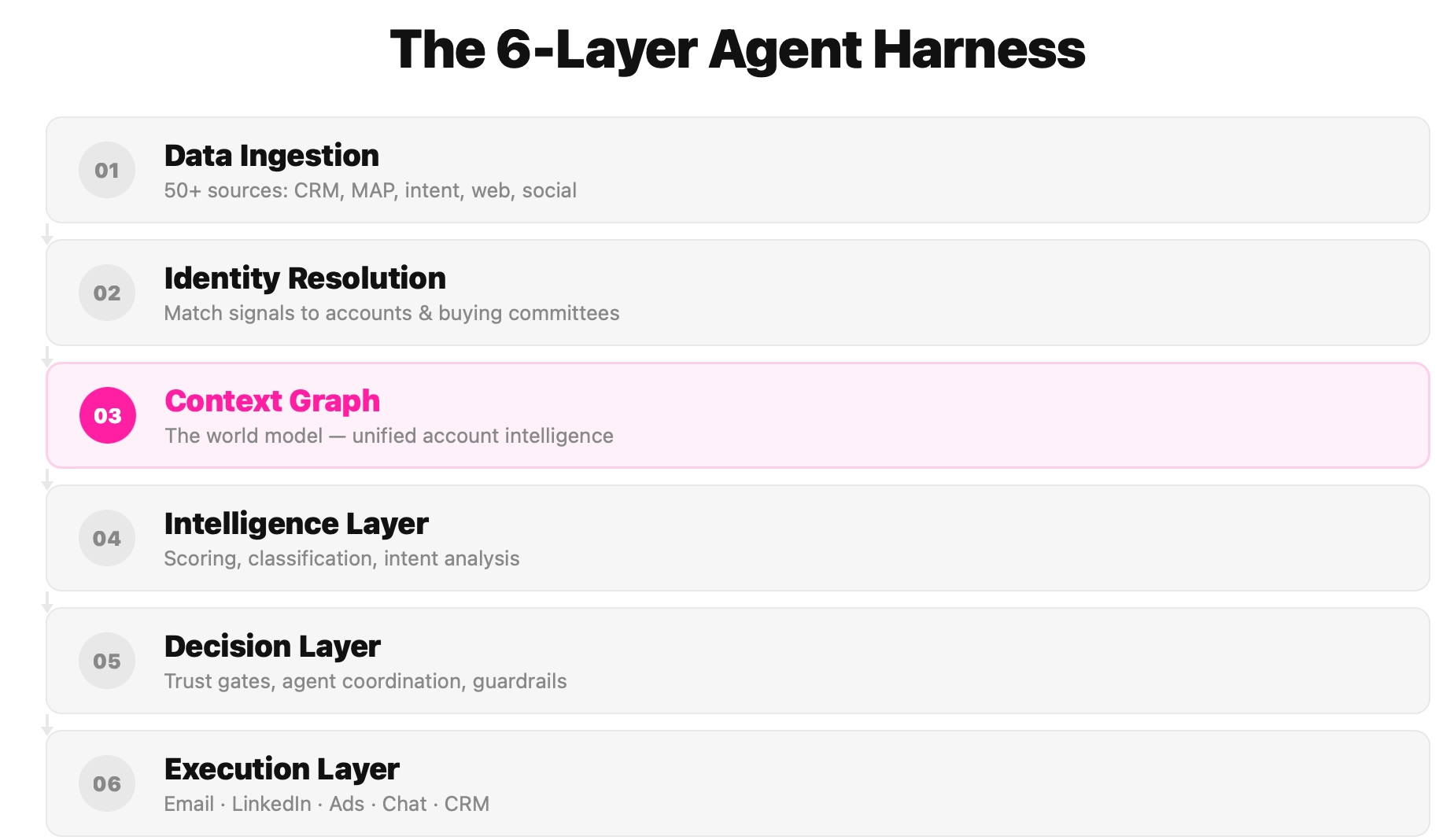
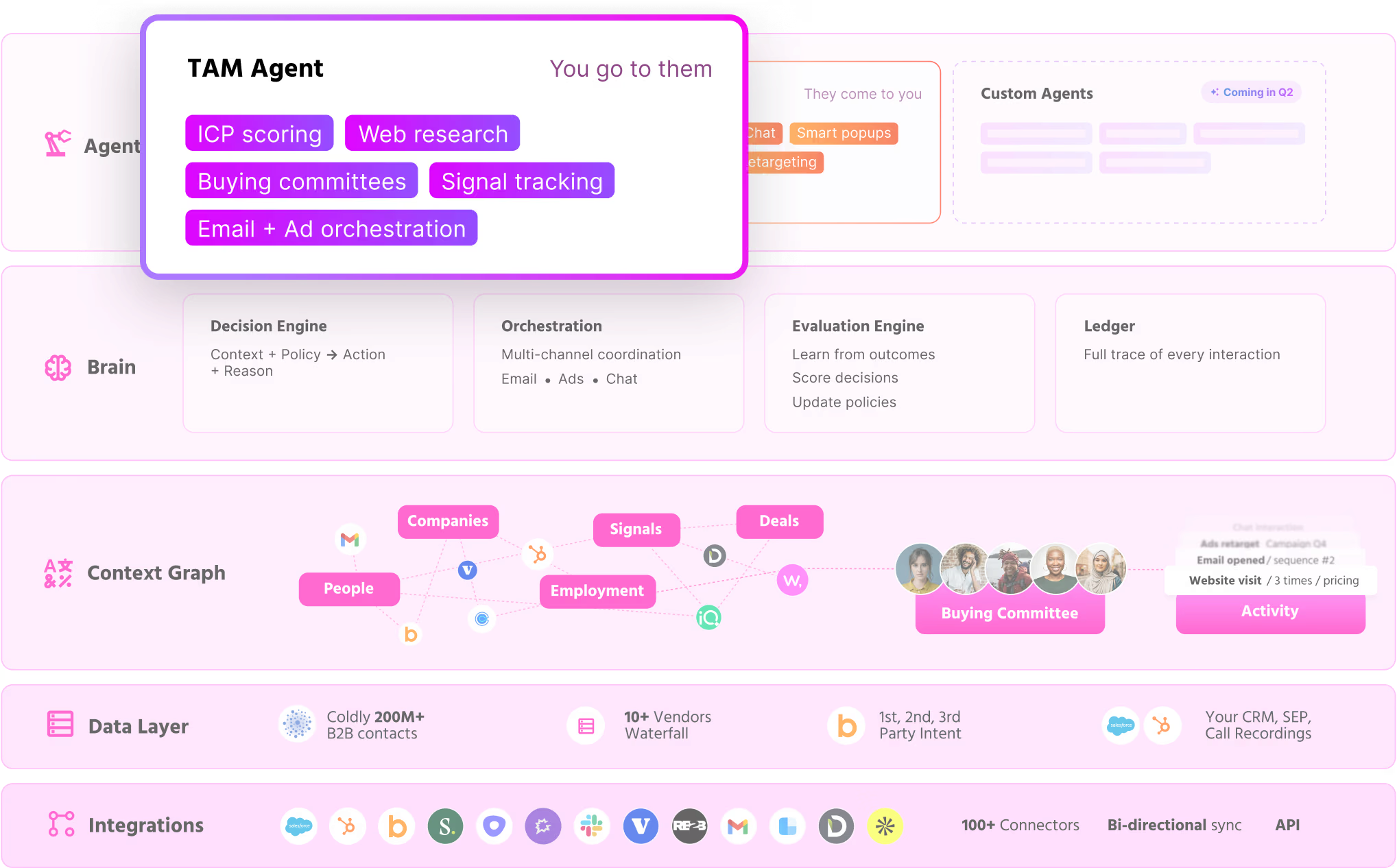
The GTM Brain follows a three-layer architecture:
- Content Layer (Evidence): Immutable source documents, the evidence trail. Emails, call transcripts, website sessions, CRM activities. Content is never edited, merged, or deleted. It's the canonical record of what was captured.
- Entity Layer (Identity): What content mentions, such as people, organizations, places, products, events. This is where identity resolution happens. "Mike Torres" in an email, "M. Torres" in a meeting transcript, and "@miket" in Slack become the same person.
- Fact Layer (Assertions): What content asserts, such as temporal claims about the world. Not just "the account is in-market" but "the account started showing intent on March 15" and "the intent signal weakened on August 3 when their budget got frozen." Each fact has a validity period, a status, and links to the entities and content it references.
This three-layer architecture enables something traditional GTM tools can't do: simulation.
- Want to know what would happen if you changed your ICP? Run a simulation over the ontology.
- Want to understand why a certain segment isn't converting? Query the fact layer for patterns.
- Want to predict which accounts will close this quarter? The model already has the features, it's been tracking them continuously.
The GTM Brain becomes a simulator for organizational physics: how decisions unfold, how buyer journeys progress, how signals predict outcomes.
This is what experienced sellers have that new hires don't, a mental model of how deals actually work. The GTM Brain makes that model explicit, queryable, and continuously improving.
How does this look in practice?
The GTM Brain is the system you use every day to answer the fundamental question: "Who do I target right now, and what do I say?"
- Every morning, it tells each rep: "Here are the five accounts you should focus on today, ranked by expected value. Account A has three people on the buying committee actively researching solutions. Here's who they are, what they've looked at, and what message will resonate."
- Every week, it tells leadership: "Here's how the strategy is performing. Outbound to Series B fintechs is converting 40% better than Series A. The 'ROI calculator' play is underperforming, here's why. Three accounts are at risk of churning, here's what's happening and what to do about it."
- Every quarter, it answers: "What would happen if we shifted focus to enterprise? If we doubled outbound volume to healthcare? If we changed the ICP to include companies with 200+ employees?"
Current GTM tools create work. They require reps to manually log activities, update stages, write notes, and maintain data hygiene. The "user experience" is actually a data entry job disguised as software.
Warmly collapses this complexity.
Part V: Why Now? The Confluence of Forces
The "Services as Software" Shift
AI will rewrite software economics by delivering outcomes rather than selling seats.
The old model: Pay $X per user per month for access to a tool. Hire people to use the tool. Hope they use it well.
The new model: Pay $X per outcome delivered. The software does the work. Humans supervise and handle exceptions.
The Infrastructure is Finally Ready
Building the GTM Brain required infrastructure that didn't exist three years ago:
- LLMs capable of reasoning: GPT-4, Claude 3, and Gemini 2 can understand context, make judgments, and generate quality output.
- Efficient inference: Test-time compute and model optimization have made it economically viable to run complex reasoning at scale.
- Identity resolution at scale: Graph databases, entity resolution algorithms, and data infrastructure can now handle the matching problem.
The Buyer Has Changed
B2B buyers don't want to talk to sales reps anymore. They want to self-serve. They want to research independently. They want to engage on their own timeline.
But they also want personalization. They want to feel understood. They want to interact with vendors who know their business, their challenges, their context.
These demands are contradictory, unless you have a system that can deliver personalization at scale without human intervention.
The Incumbents Can't Adapt
Traditional GTM systems were built for a world where humans did the work and software stored the records. Their architectures optimize for:
- Current state storage (not temporal reasoning)
- Human-driven workflows (not autonomous agents)
- Feature expansion (not outcome delivery)
- Per-seat pricing (not value capture)
Rebuilding these systems for an AI-native world would require gutting their core architecture. They can add AI features at the edges, but they can't become AI-native without breaking everything that makes them work.
This is the classic innovator's dilemma. The incumbents are too successful to change.
The Coexistence Reality
To be clear: CRMs survive. They remain the system of record for state, the canonical customer record, the opportunity pipeline, the contact database.
What we're building is different: the system of record for events.
We're not asking companies to rip out their CRM. We're adding the layer that makes the CRM, and every other tool in the stack, actually intelligent.
Part VI: The Compounding Intelligence Moat
1. Hard-to-Copy: The Context Graph Moat
The GTM Brain's defensibility comes from how the context graph is built and what accumulates inside it: decision traces.
Every time the system decides to prioritize an account, reach out to a contact, or hold back on an action, it generates a context trace: what inputs were gathered, what features were computed, what policy was applied, what outcome resulted.
This enables the question that makes learning possible: "Given what we knew at that time, was this the right decision?"
Do this thousands of times. The weights get updated. Historical and in-production performance converge. Eventually the model achieves 90%+ accuracy. Unlike a CRM which can be copied over and ripped out, this model is proprietary to Warmly and thus can’t be ripped out unless you want to start over. At that point, why would you rip it out?
These traces form a context graph, a structured, replayable history of how context turned into action. Over time, this graph becomes:
- A world model of your market: Which signals predict buying intent? Which messaging resonates with which personas? Which accounts look like your best customers?
- A source of precedent: When a similar situation arises, the system can query how it was handled before. What worked? What didn't?
- A simulation engine: Before taking action, the system can run counterfactuals.
Competitors can copy features. They can't copy the accumulated decision intelligence that lives inside the system.
2. Real-time identity graph (hard, expensive, and operational)
People visit a website for 8 seconds and move on.
If they can't get their questions answered, if the chatbot is slow, if no one reaches out, if the experience feels generic, they have another P1 priority to fulfill. They're gone. Speed to lead isn't a nice-to-have. It's the entire game.
Why most systems fail
Most GTM infrastructure is batch-processed. Data lands in a warehouse overnight. Reports run in the morning. By the time you know someone was on your pricing page, they've signed with a competitor.
LLMs make this worse, not better. They have natural latency: seconds to process, reason, and respond. Asking an LLM to compute context at inference time (pulling history, resolving identity, evaluating signals, checking policy) adds more seconds before reasoning even starts.
In a world where attention spans are measured in single digits, inference-time context assembly is a losing architecture.
The real-time architecture
Warmly pre-computes and stores buyer state so agents can access it instantly.
When someone lands on your site, the context is already there: who they are, what company, their engagement history, their intent signals, what play to run. The work happened before they arrived.
Real-time chat. Immediate rep routing. Instant email trigger. Phone call with full context. All of these require data and primitives to be structured ahead of time, not assembled on demand.
The data network effect
But real-time infrastructure is just the foundation. The real moat is what improves with scale.
Website de-anonymization is a probabilistic game. You're triangulating sparse signals (IP ranges, cookie data, firmographic patterns, behavioral fingerprints) to resolve an anonymous visitor to a real person at a real company.
Accuracy improves with data volume. The more visitors you see across more customer sites in more industries, the better your resolution models become. False positives drop. Confidence scores improve. Edge cases get handled.
Every new Warmly customer contributes to this flywheel:
- Their website visitors add signals to our identity graph
- Our improved accuracy helps them convert more visitors
- Better outcomes attract more customers
- The product gets better for everyone as the network grows
Competitors starting from scratch don't just lack our infrastructure. They lack our data. You can't buy your way to data volume. You earn it customer by customer, visitor by visitor, over years.
The ontology discovery effect
There's a second network effect hiding in how we structure data.
There are infinite ways to model a GTM context graph. What primitives matter? How do you represent a buying committee? Which signals predict readiness? How do you compress 100,000 website visits into queryable state?
This is the art.
Each company we onboard teaches us something new about how to structure the ontology. The primitives that matter for a Series B fintech differ from an enterprise healthcare company. A product-led growth motion requires different signals than an outbound-heavy sales team.
The more companies we serve, the better we understand how to model GTM for everyone. We've mapped the territory. Competitors starting from scratch have to rediscover these primitives one by one.
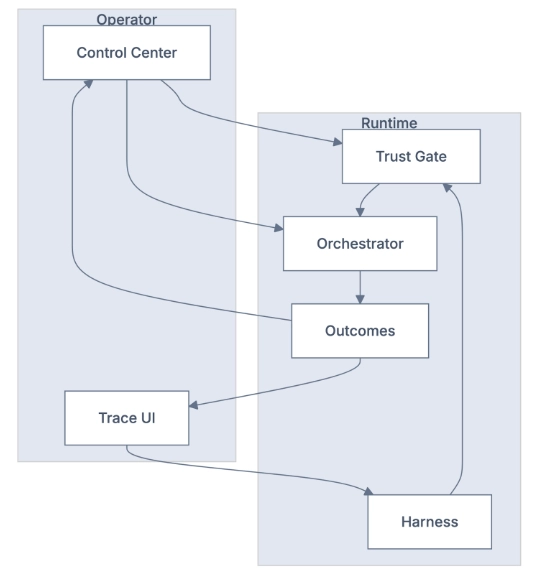
The primitive stores
The result is a set of pre-computed stores that our agents query in real-time:
Buying Committee Store: Who's involved, their roles, their engagement
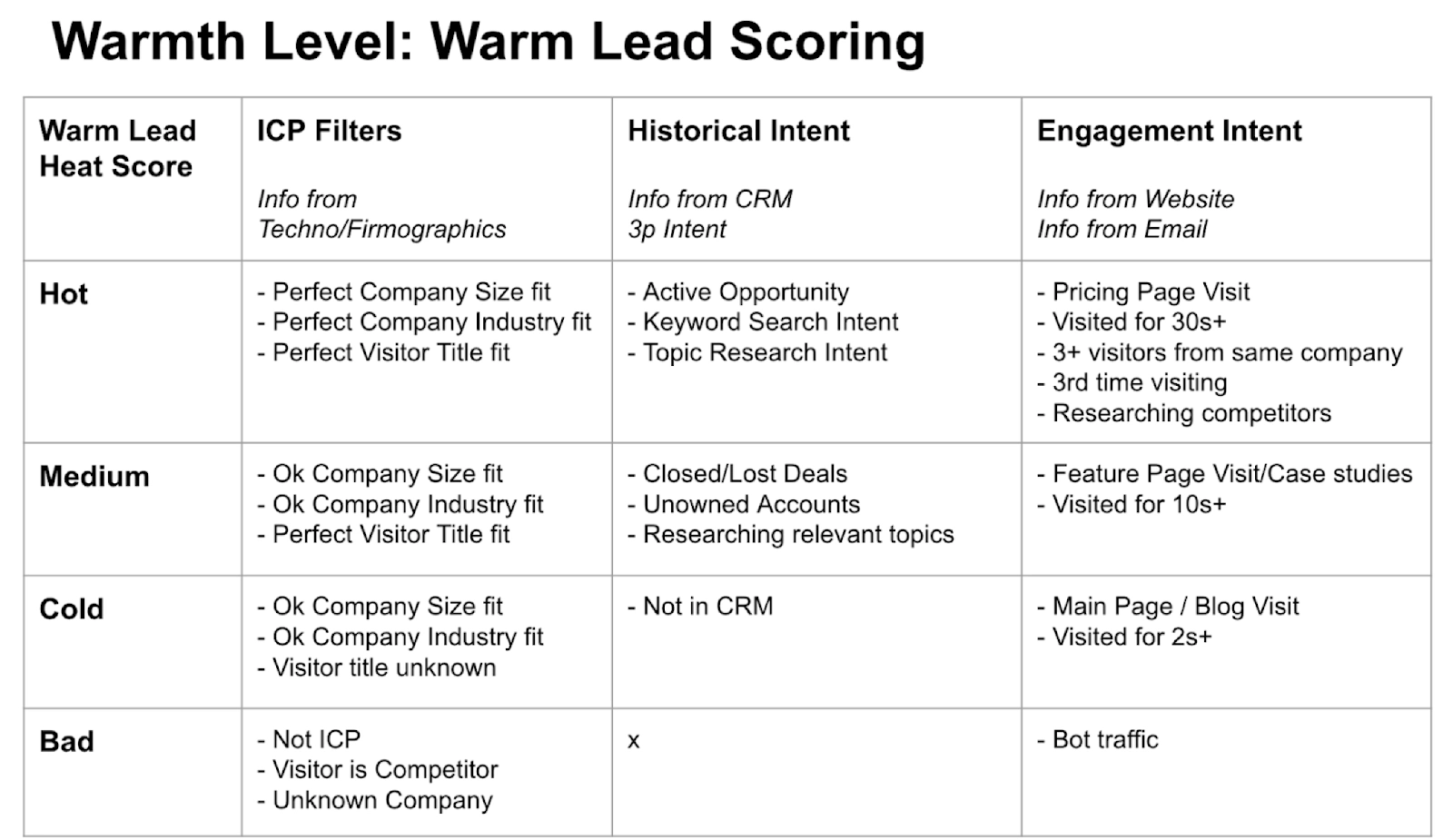
Intent Store: Temporal signal patterns, page-level behavior, engagement velocity
Lookalike Store: Which accounts match your best customers
Enrichment Store: Company and contact data, refreshed and validated
Outcome Store: What happened and what we learned
These stores feed the agents that execute:
- AI Chat Agent
- Buying Committee Agent
- Scoring Agent
- Enrichment Agent
- Lookalike Agent
- Web Research Agent
- Email/LinkedIn Copy Agent
Each agent operates on pre-computed context. They don't rebuild the world at runtime. They query it instantly.
Why this compounds
Moat #1 (the Context Graph) captures what your organization learns. This moat captures what Warmly learns across every organization.
Decision traces are proprietary to each customer. But de-anonymization accuracy, entity resolution quality, and ontology design improve for everyone as the network grows.
3. The Ground-Truth Data Moat
This is the unsexy moat that nobody in AI wants to talk about.
Moat #2 is about data getting better with scale. This moat is about data staying correct over time. They're different problems.
The core tension
LLMs are probabilistic: confident when wrong, hard to debug. But the data that feeds them must be deterministic, auditable, and correct.
Send an email to the wrong person? Brand damage. Route a lead to the wrong rep? Territory conflict. Show the wrong company data in chat? Lost credibility.
AI systems are only as good as the data they reason over. Garbage in, garbage out, except now the garbage gets delivered at scale, instantly, with confidence.
Why data rots
All data degrades. People change jobs. Companies get acquired. Email addresses go stale. Third-party providers have their own quality issues.
The half-life of B2B contact data is roughly 2 years. Half your database is wrong within 24 months, even if it was perfect when you collected it.
The moat isn't having clean data. The moat is keeping data clean as reality shifts underneath you.
The validation loop
The hardest part: you often don't know if data is wrong until months later.
You resolve an anonymous visitor to "Sarah Chen at Acme Corp." Was that correct? You might not know until she fills out a form, sales gets a response (or bounce), or the deal closes and you see who was actually involved.
The feedback loop is long. You have to build systems that learn from delayed ground truth: updating confidence scores, retraining models, surfacing systematic errors.
We've built these loops. Every conversion, every bounce, every "wrong person" response feeds back into our data quality systems.
Why this is a moat
Competitors can build AI features quickly. They can't quickly build:
- Years of learning which data sources lie and when
- Production-hardened systems for managing degradation
- Validation loops that connect outcomes to data quality
- Institutional knowledge of where things break
Data quality isn't a feature you ship. It's a discipline you practice every day. The companies that skip this step build impressive demos that fall apart in production.
We've done the unglamorous work. That's the moat.
Conclusion: The Decision Layer
The Story So Far
- The problem: AI made GTM execution infinite, but pipeline is harder than ever to build. We solved the wrong problem, we built infrastructure for doing more, not for knowing what to do.
- The opportunity: The next trillion-dollar platforms will create a context graph that makes precedent searchable. But you need domain-specific world models.
- The solution: The GTM Brain, a stateful decision system that ingests signals, resolves identities, builds a world model, computes expected values, decides what to do, executes through agents, and learns from outcomes.
- The vision: Every morning, it tells each rep what to do. Every week, it tells leadership what's working. Every quarter, it simulates strategic alternatives. The operating system for revenue. And it can plug seamlessly into any agentic framework.
The Bet Warmly is Making
- The debate right now is whether AI will transform enterprise software or just add features to existing categories.
- Our answer: the next trillion-dollar platforms will be systems of record for decisions, not just data.
- Traditional systems of record store current state. The GTM Brain stores decision intelligence: the reasoning that connects data to action, the traces that capture how choices were made, the world model that enables simulation and prediction.
- CRMs don't go away. Warehouses don't go away. But neither of them can do what we do: capture the event clock, build the world model, and make AI agents actually intelligent about your business.
What We're Building
This is what Warmly is building. Not another tool in the GTM stack. Not a chatbot for your CRM. Not "AI features" bolted onto existing workflows.
The GTM Brain, a single, self-learning engine that:
- Sees every signal across your entire GTM surface area
- Resolves identities and builds the entity graph
- Captures decision traces and accumulates precedent
- Reasons over context that no other system can see
- Decides what to do (including when to do nothing)
- Executes through specialized agents
- Learns from every outcome
- Gets smarter every day
The companies that build this infrastructure will have something qualitatively different. Not agents that complete tasks, organizational intelligence that compounds. That simulates futures, not just retrieves pasts. That reasons from learned world models rather than starting from scratch every time.
The Path Forward
We're building the GTM Brain to help B2B teams automate their GTM motion at scale and achieve their potential as a business. And like Tesla learned with driving, like Palantir learned with intelligence analysis, the key is not to program the rules. It's to learn them from the accumulated experience of thousands of practitioners.
Last Updated: January 2026







![6sense Review: Is It Worth It in 2026? [In-Depth]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/67b613de9d586b53d1dec646_6sense_review.webp)
















































![10 Best IPFingerprint Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a69baada44932cddf63ae4b_10%20Best%20IPFingerprint%20Alternatives%20%26%20Competitors.png)



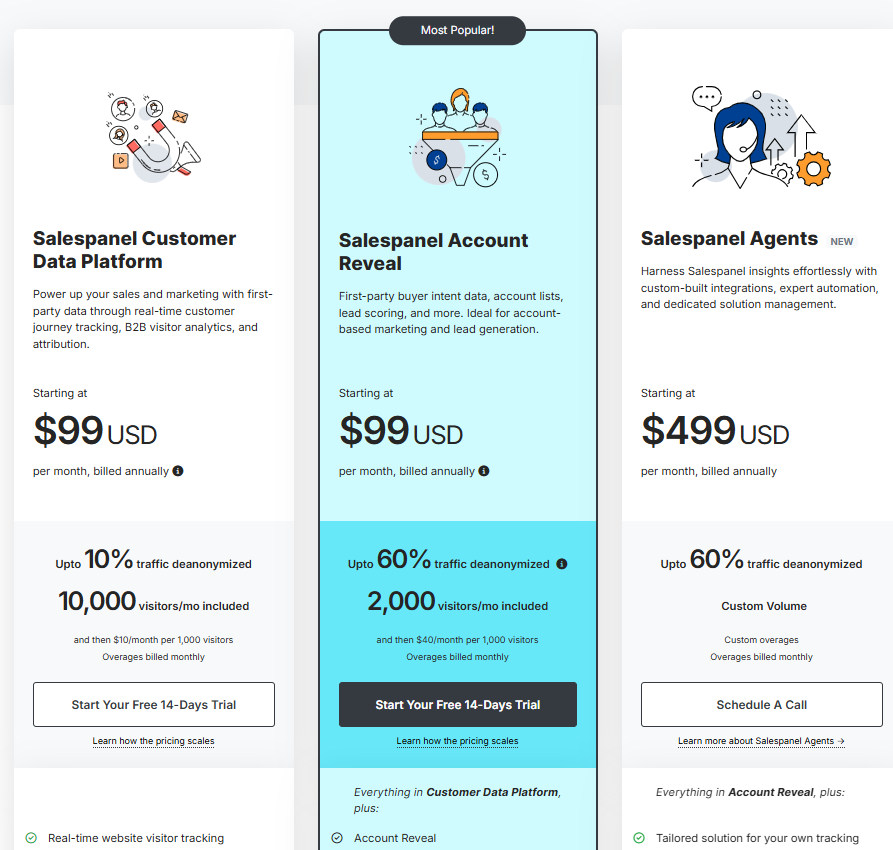
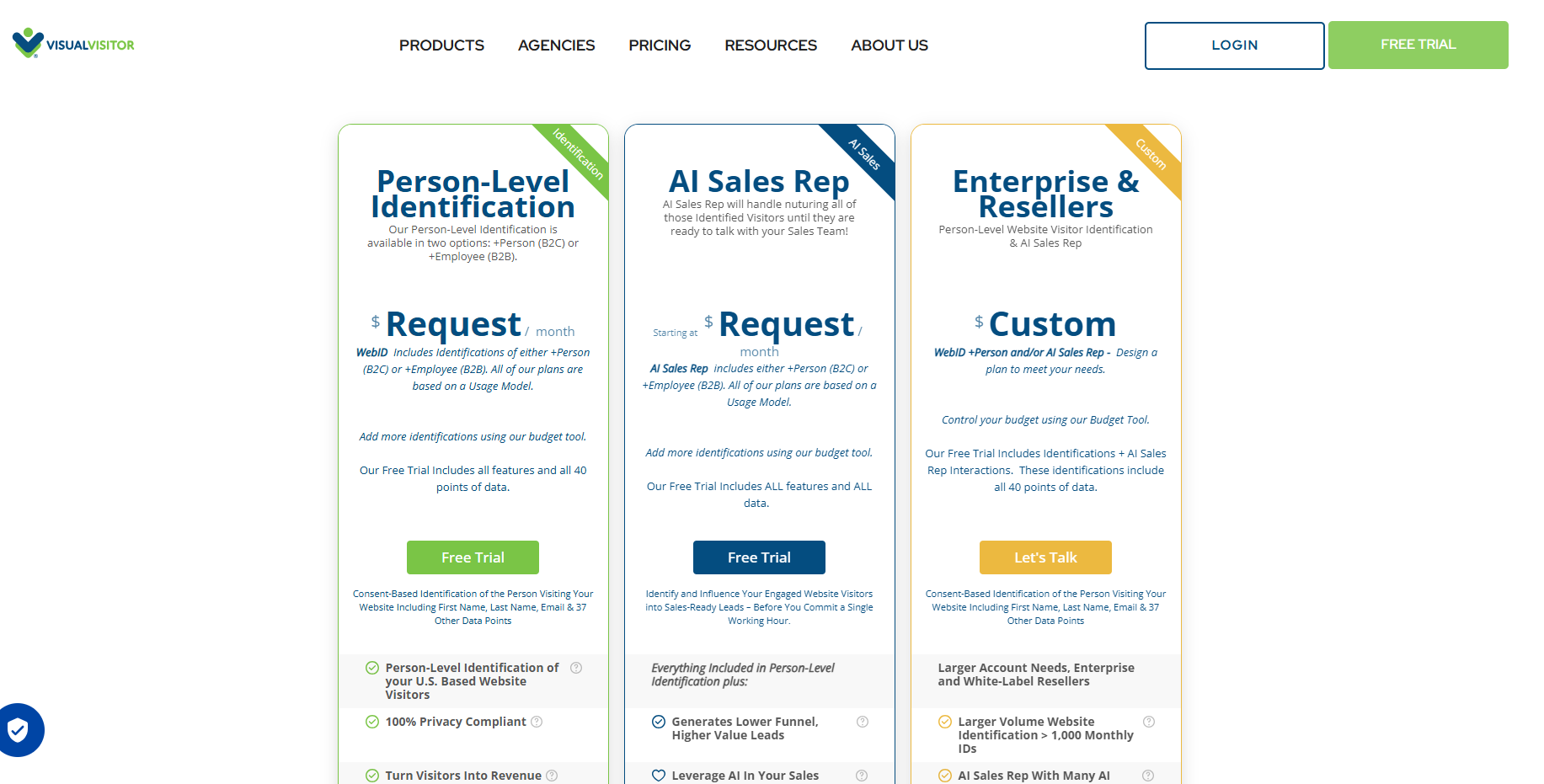
![Visual Visitor Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a69b9fa762af138b5cb0c9a_Visual%20Visitor%20Pricing%20Is%20It%20Worth%20It.png)

![10 Best Visual Visitor Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a61c37a83ca9b05b07e1476_visual%20visitor%20alternatives.png)





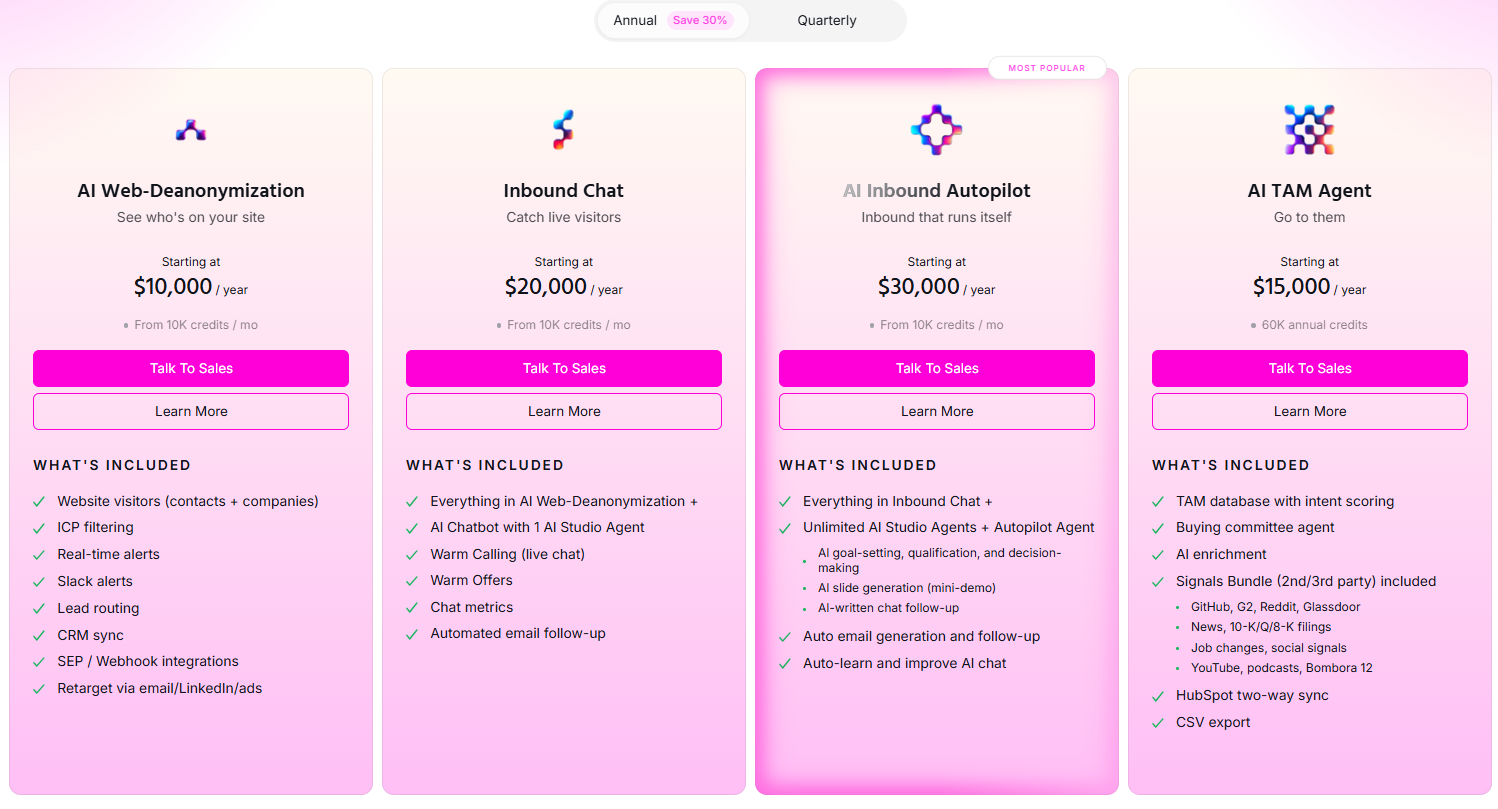
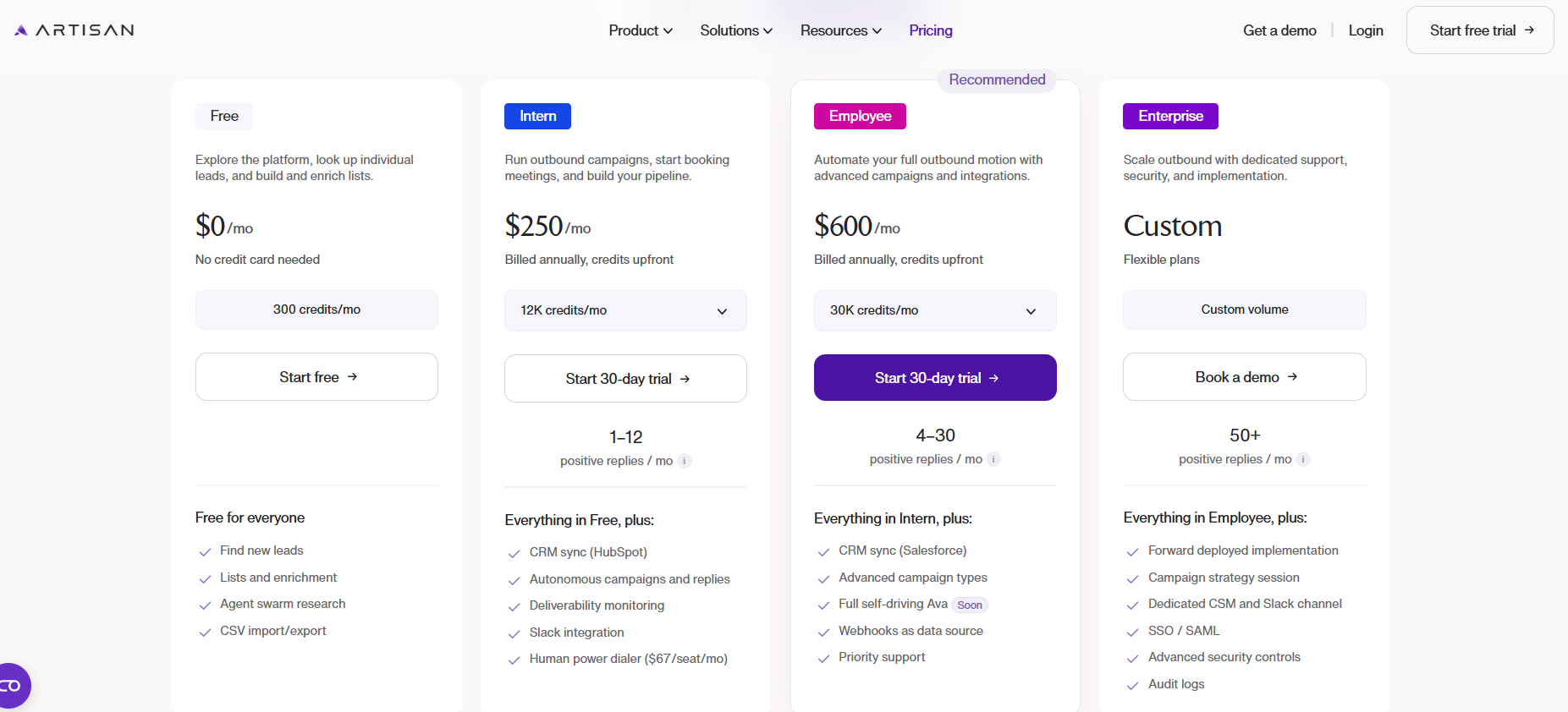
![Artisan AI Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a50d9d6673a4a522a93bce2_artisan%20ai%20pricing.png)

![10 Best Salesloft Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a50d85693a51868bfa50f01_salesloft%20alternatives.png)


![Swan AI Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a4613cc82de0944cc3f889d_swan%20ai%20pricing.png)

![10 Best Artisan AI Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a461258d8b098ce533f8b5f_artisan%20ai%20alternatives.png)

![10 Best Swan AI Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a418038ba577e5a48992a46_swan%20ai%20alternatives.png)
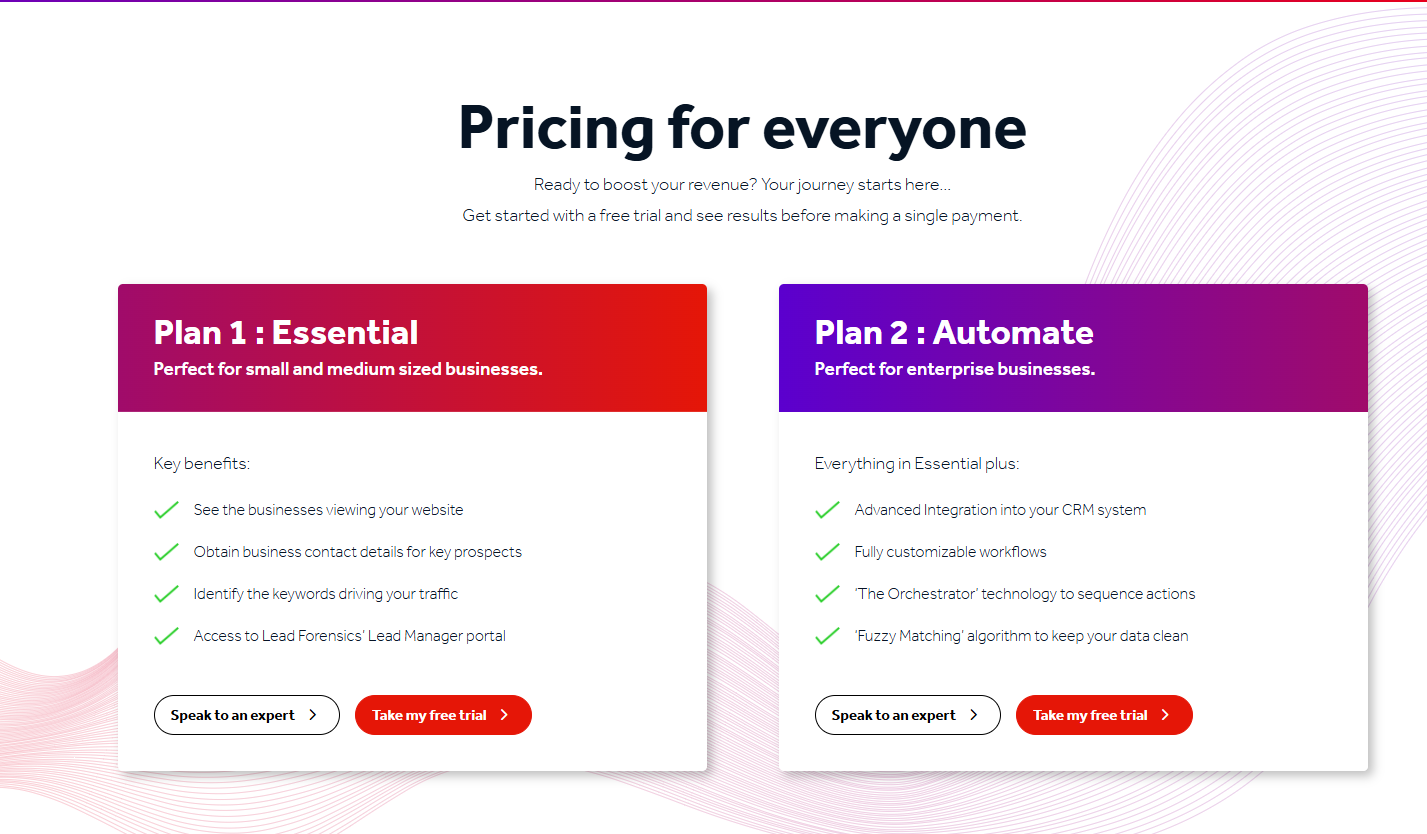
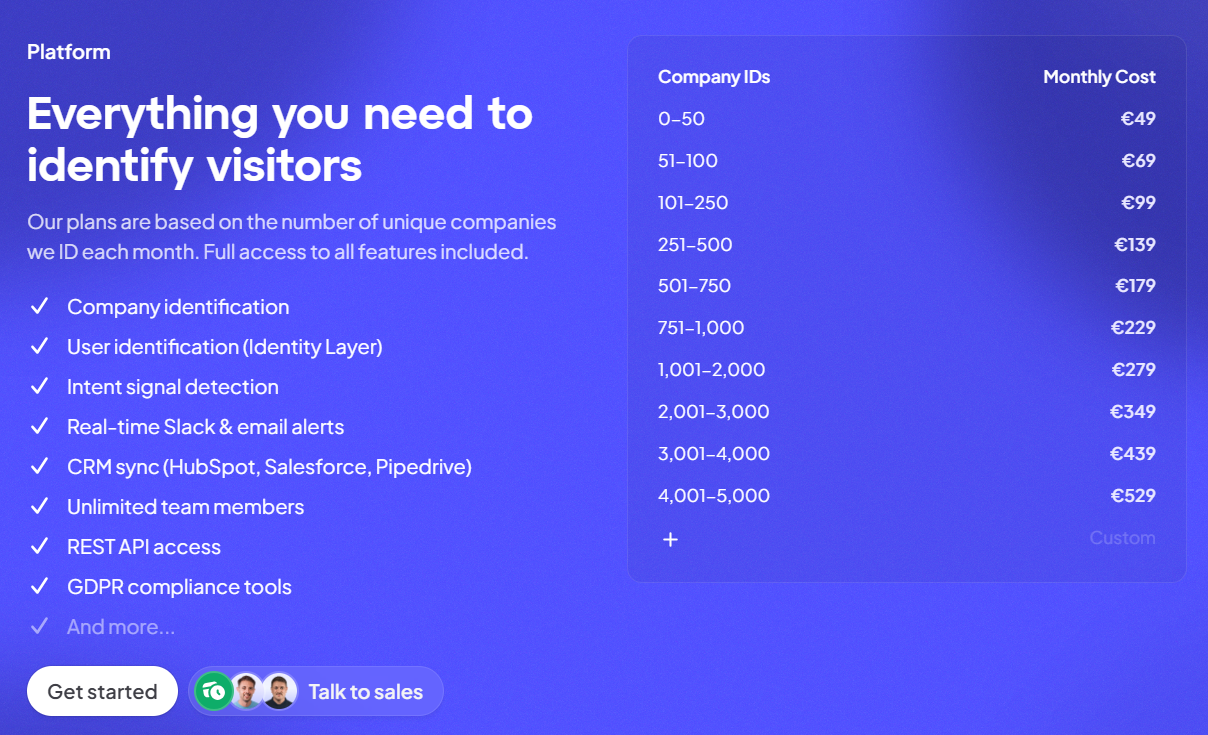
![Snitcher Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a416c8fdb39053fc92efbe9_snitcher%20pricing.png)



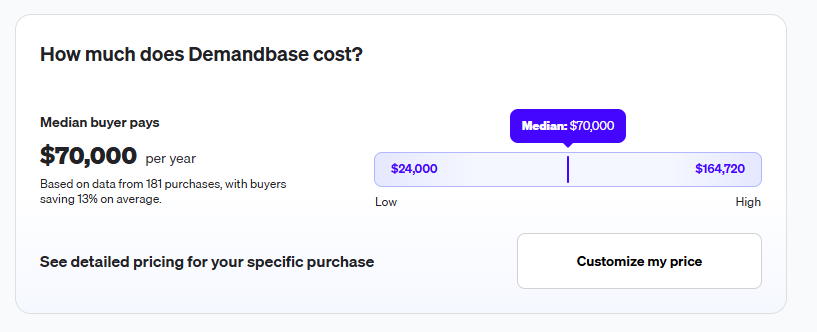
![Demandbase Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a353caddcd5ecf848e46ea7_demandbase%20pricing.png)