![Swan AI Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a4613cc82de0944cc3f889d_swan%20ai%20pricing.png)
Swan AI Pricing: Is It Worth It In 2026? [Reviewed]

Everything runs on credits, and a credit only leaves your balance when Swan does something for you, such as researching an account, enriching a contact, writing a message, or updating your CRM.
Below, I break each tier down, then push a few realistic team sizes through the credit math so you can see where the bill lands.
➡️ At the end, I'll introduce you to an alternative to Swan AI, Warmly (that’s us!), that lets you own the identification outright and ship the chat and outbound as agents that work from day one, with nothing to build first.
TL;DR
- Swan's price is built from two things: credits and seats. A credit is spent each time an agent does a piece of GTM work. A seat is anyone who talks to Swan or approves its actions, while alerts and view-only access stay free.
- There's no free-forever plan, though there is a free trial you can reach from every plan card.
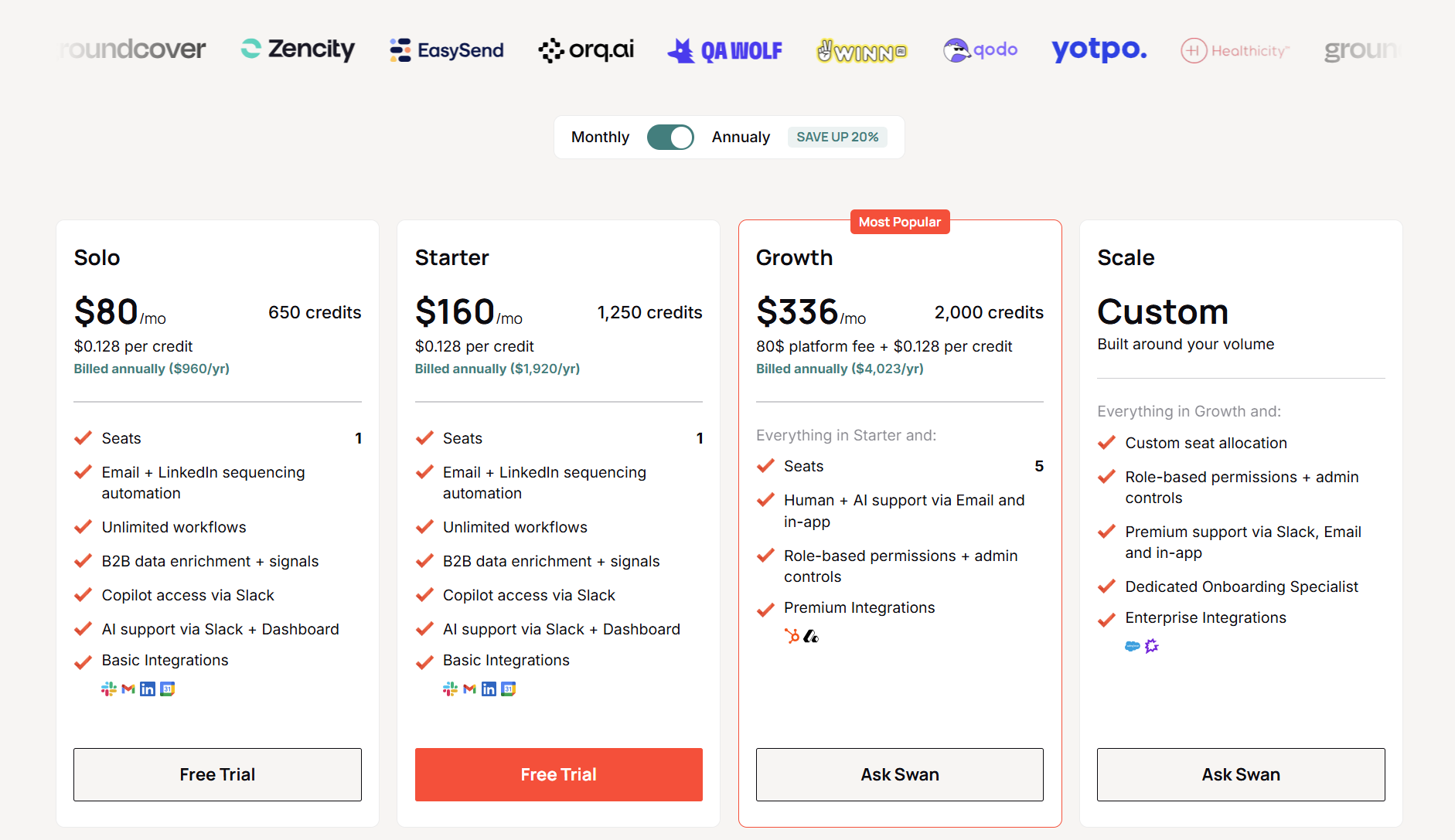
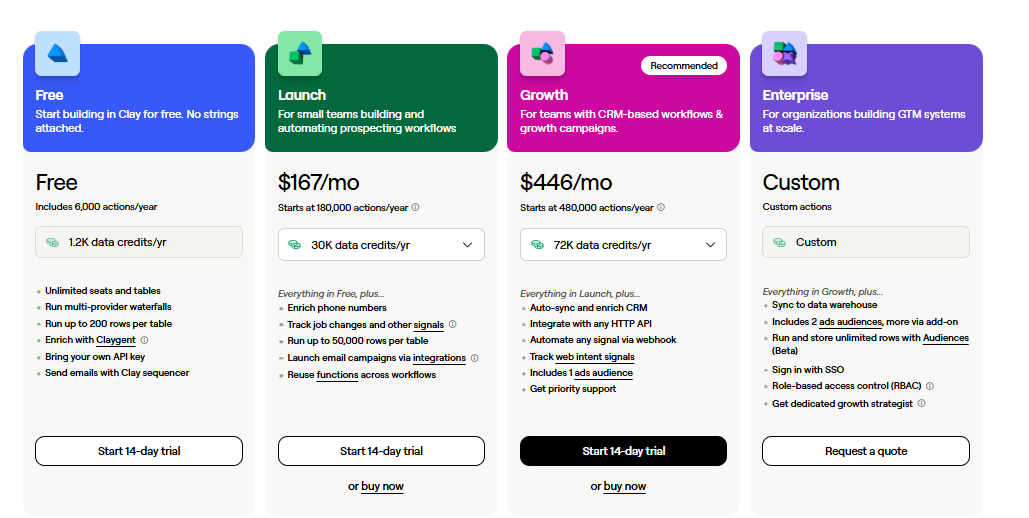
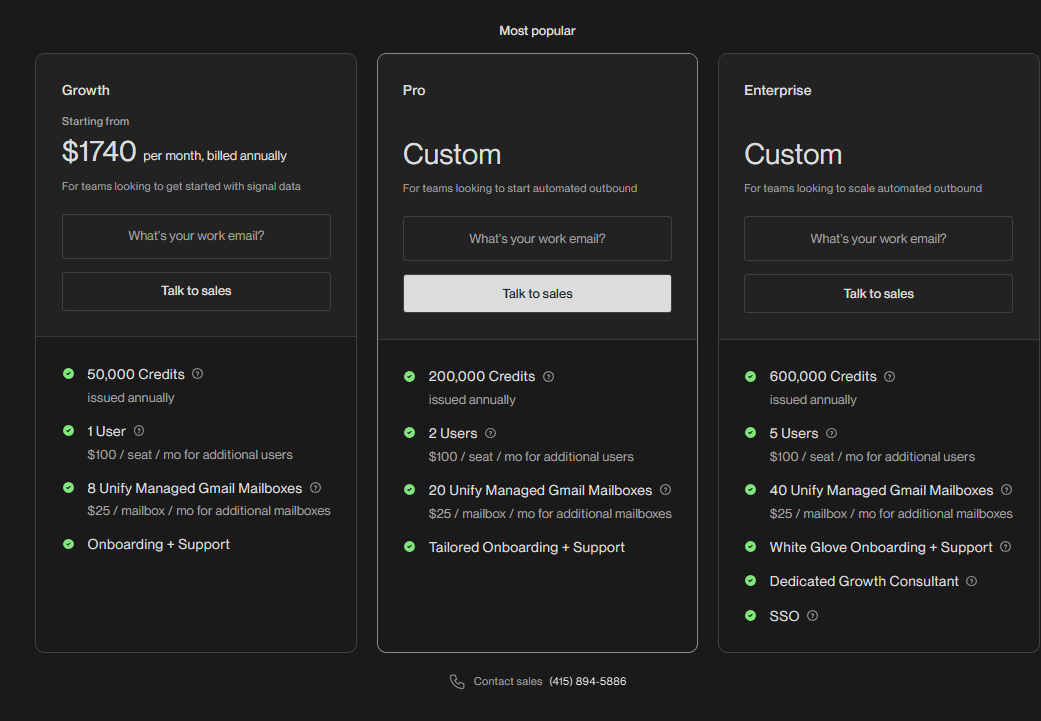
- The three published tiers all bill annually: Solo at $80/mo (650 credits), Starter at $160/mo (1,250 credits), and Growth at $336/mo (2,000 credits with an $80 platform fee on top).
- Beyond those, a custom Scale tier covers higher volumes. Credits cost $0.128 each, roll over, and overflow top-ups run at 150% of your plan rate.
- Warmly offers the best alternative to Swan AI for mid-market B2B SaaS teams that want native person-level identification, on-page chat, and outbound as ready-built agents, plus a free plan to run on live traffic first.
How does Swan calculate its pricing?
Swan's invoice has a few moving parts, and once they click, the tiers make sense fast:
- Credits: Action credits cover the tasks a rep would normally handle, and Swan charges one credit per task, no matter how involved it gets.
Data credits are separate, spent when Swan pulls third-party data to enrich a lead, so they scale with how much enrichment you ask for.
Every plan prices a credit at $0.128.
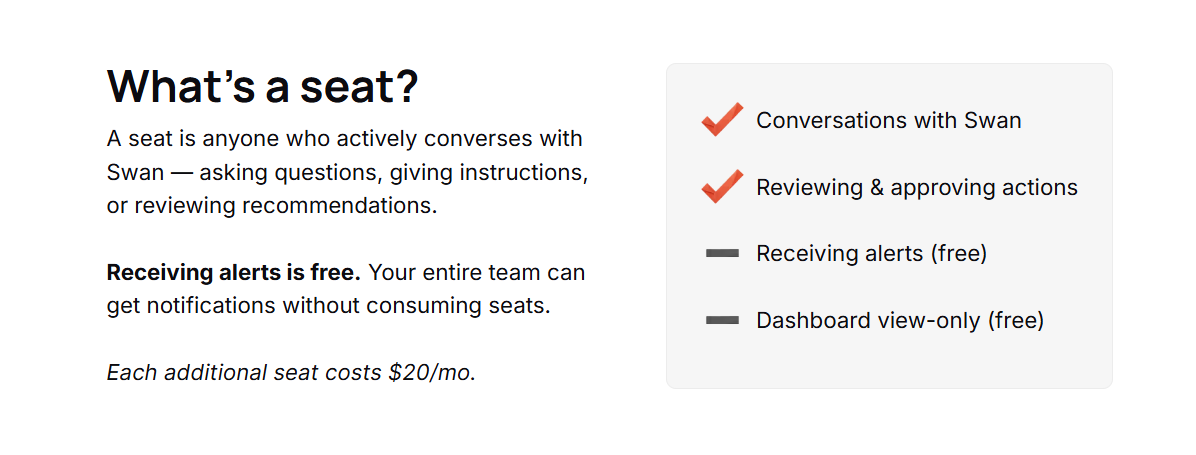
- Seats: A seat is anyone who converses with Swan or reviews and approves what it wants to do.
Receiving alerts costs nothing, and dashboard view-only access is free too, so the wider team can stay looped in without spending a seat.
Solo and Starter include one, Growth includes five, and Scale is custom. Each extra seat is $20/mo.
- Platform fee: Growth carries an $80/mo platform fee on top of its credits. Solo and Starter fold everything into one flat rate, with no separate fee.
- Billing cycle: The published prices assume annual billing, which Swan says trims up to 20% off both the platform fee and the credit tiers. Pay monthly, and you'll pay more.
- Rollover and top-ups: Unused credits don't vanish. On a monthly commitment, they roll up to twice your monthly allocation; on an annual commitment, they roll without a cap inside the 12-month term.

Run dry mid-cycle, and top-ups cost 150% of your plan rate, which works out to about $0.192 a credit.
Does Swan have a free plan or free trial?
Swan doesn't run a free-forever tier. What it gives you is a trial, with a button on every plan card and no commitment to begin.
⚠️ Note: The pricing page doesn’t mention the trial's length and credit allowance.
Swan AI’s plan breakdowns
Swan publishes three paid tiers and one custom tier. I'll take them in turn, with the price and what each includes:
Swan AI’s Solo plan
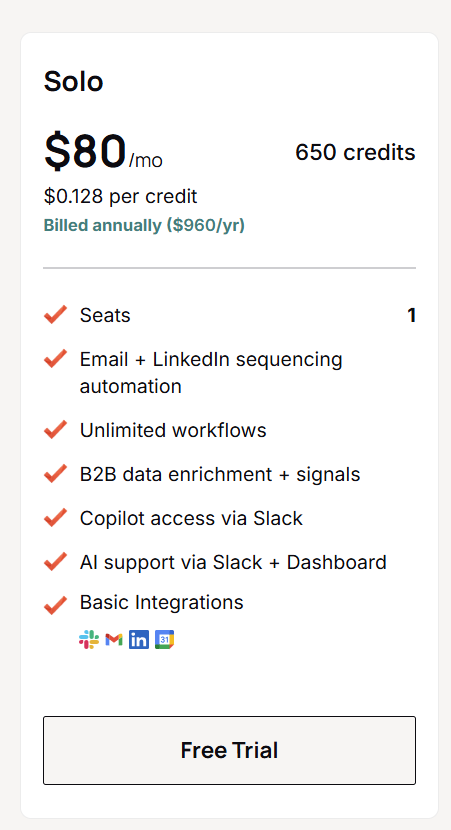
Solo opens at $80/mo on annual billing, which is $960 a year, for 650 credits a month at $0.128 each.
Here’s what’s included:
- One seat.
- Email and LinkedIn sequencing automation.
- Unlimited workflows.
- B2B data enrichment and signals.
- Copilot access through Slack.
- AI support via Slack and the dashboard.
- Basic integrations: Slack, Gmail, LinkedIn, and Calendar.
This is the single-operator tier, sized for one person testing whether the agent model pays for itself.
Swan AI’s Starter plan
Starter is $160/mo on annual billing, so $1,920 a year, for 1,250 credits a month.
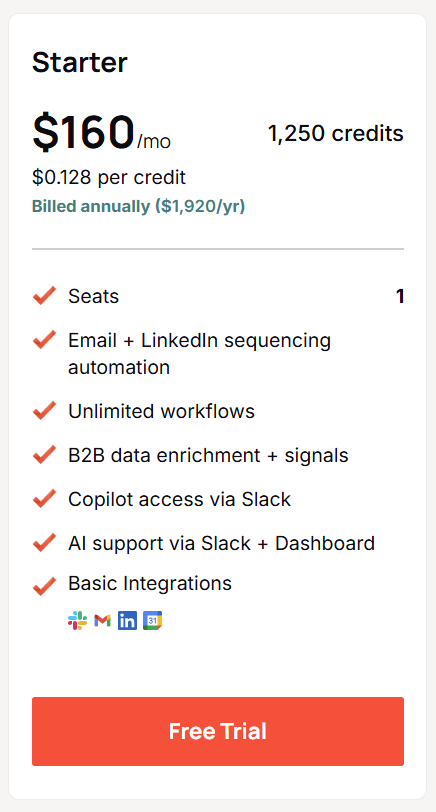
The feature set and the single seat match Solo exactly.
What you're buying is close to double the monthly credit pool, for the operator running heavier enrichment or more sequences than 650 credits can cover.
Swan AI’s Growth plan
Growth lands at $336/mo on annual billing. The page lists that as $4,023 a year. You get 2,000 credits a month, and the $80 platform fee is what sets this tier's math apart from the two below it.
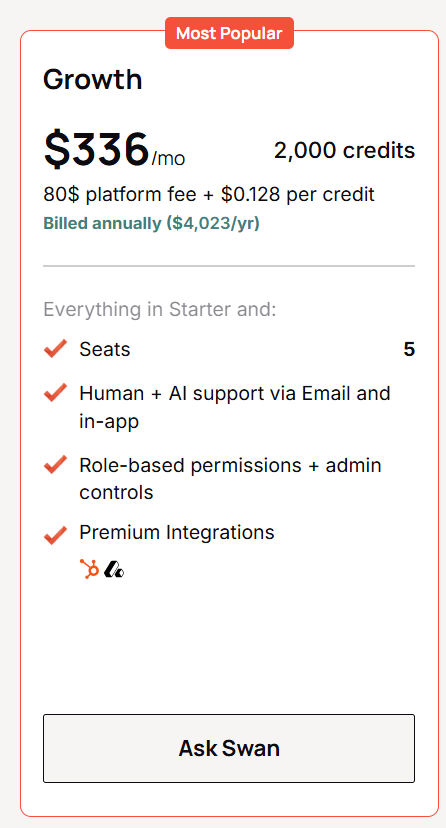
It builds on Starter with:
- Five seats.
- Human and AI support over email and in-app.
- Role-based permissions and admin controls.
- Premium integrations: HubSpot and Attio.
Swan AI’s Scale plan
Scale is custom, priced around your volume.
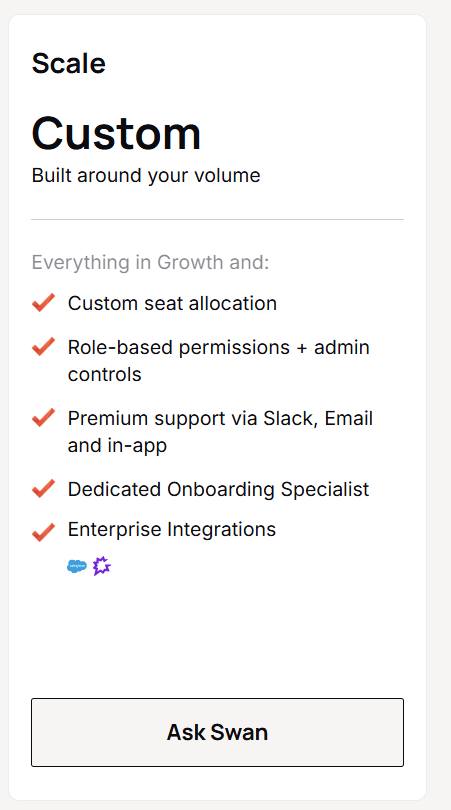
On top of Growth, it brings:
- Custom seat allocation.
- Premium support across Slack, email, and in-app.
- A dedicated onboarding specialist.
- Enterprise integrations: Salesforce and Gong.
When your usage outgrows the published credit pools, this is the conversation you'd have with their team.
What would Swan cost your team to run?
Here are a few realistic shapes, with the yearly figure attached:
- One founder doing their own outbound, light on enrichment: Solo, $960 a year, 650 credits a month.
- A single RevOps person running steady sequencing and heavier enrichment: Starter, $1,920 a year, 1,250 credits a month.
- A five-person GTM team on HubSpot that wants permissions and faster support: Growth, $4,023 a year for the platform and all five seats, 2,000 credits a month. A sixth person who talks to Swan adds $20/mo, so budget about $240 a year for each seat past the five.
- That same team burning through its pool before month-end: top-ups at 150% of the plan rate, so the overflow lands near $0.192 a credit, up from the $0.128 baked into the plan.
The number that's hard to forecast going in is credit consumption.
Action credits are predictable enough at one per task.
Data credits aren't, because how many you spend rides on how much third-party data each lead pulls, so two months on the same plan can bill differently depending on how hard your agents work.
⚠️ Swan doesn't publish a full credit-cost-per-action table, so the precise burn rate is the line I'd pin down before committing.
Are you looking for a Swan AI alternative?
Warmly is where I'd send a mid-market B2B SaaS team that likes Swan's agent idea but doesn't fancy spending its first month as a workflow architect, or renting out the part that matters most: knowing who showed up.
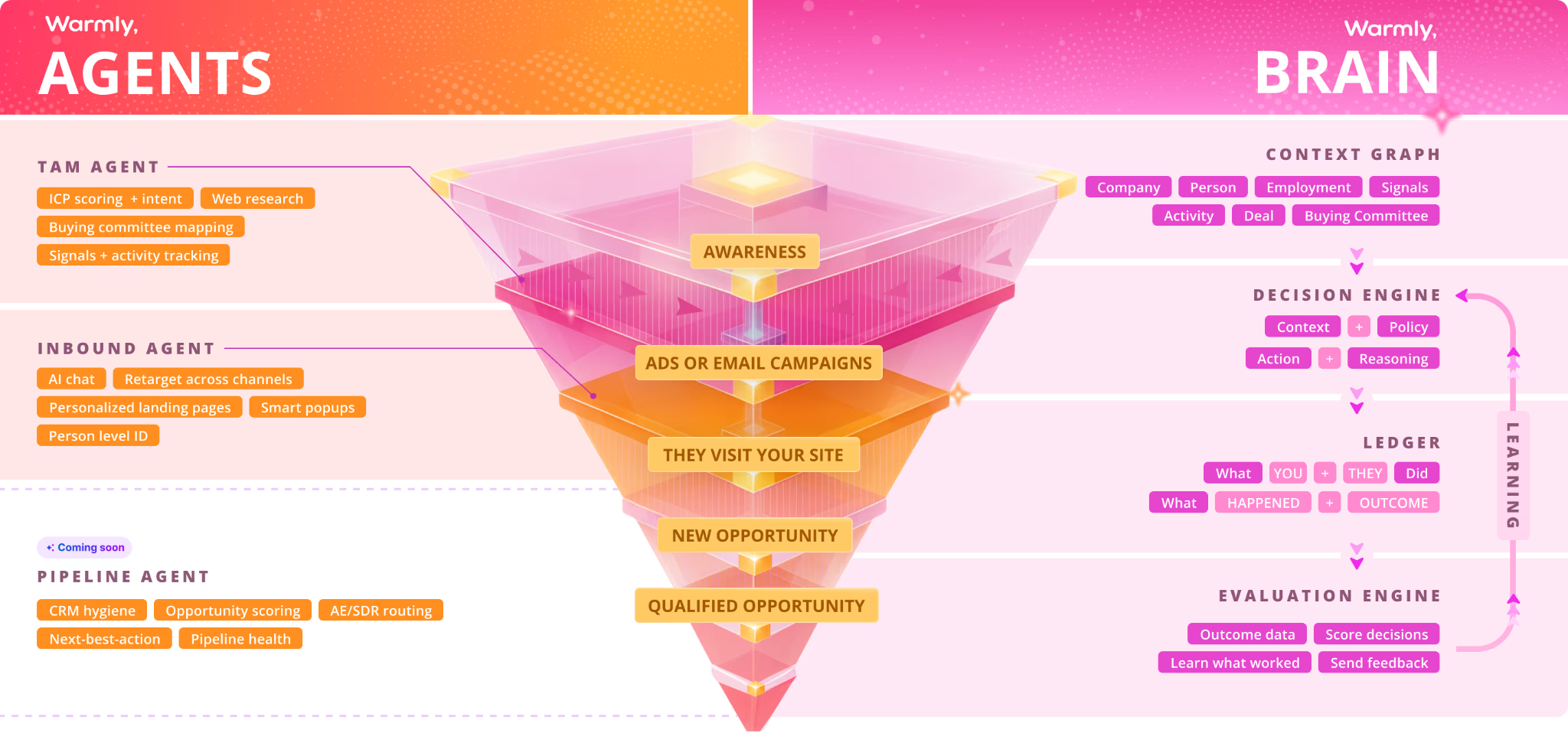
Two agents do the work, and a shared layer keeps them in sync:
- The Inbound Agent owns the website: it identifies people, chats, fires popups, and retargets the ones who bounce.
- The TAM Agent owns everything past the website: ICP scoring, intent, committee mapping, and sequencing.
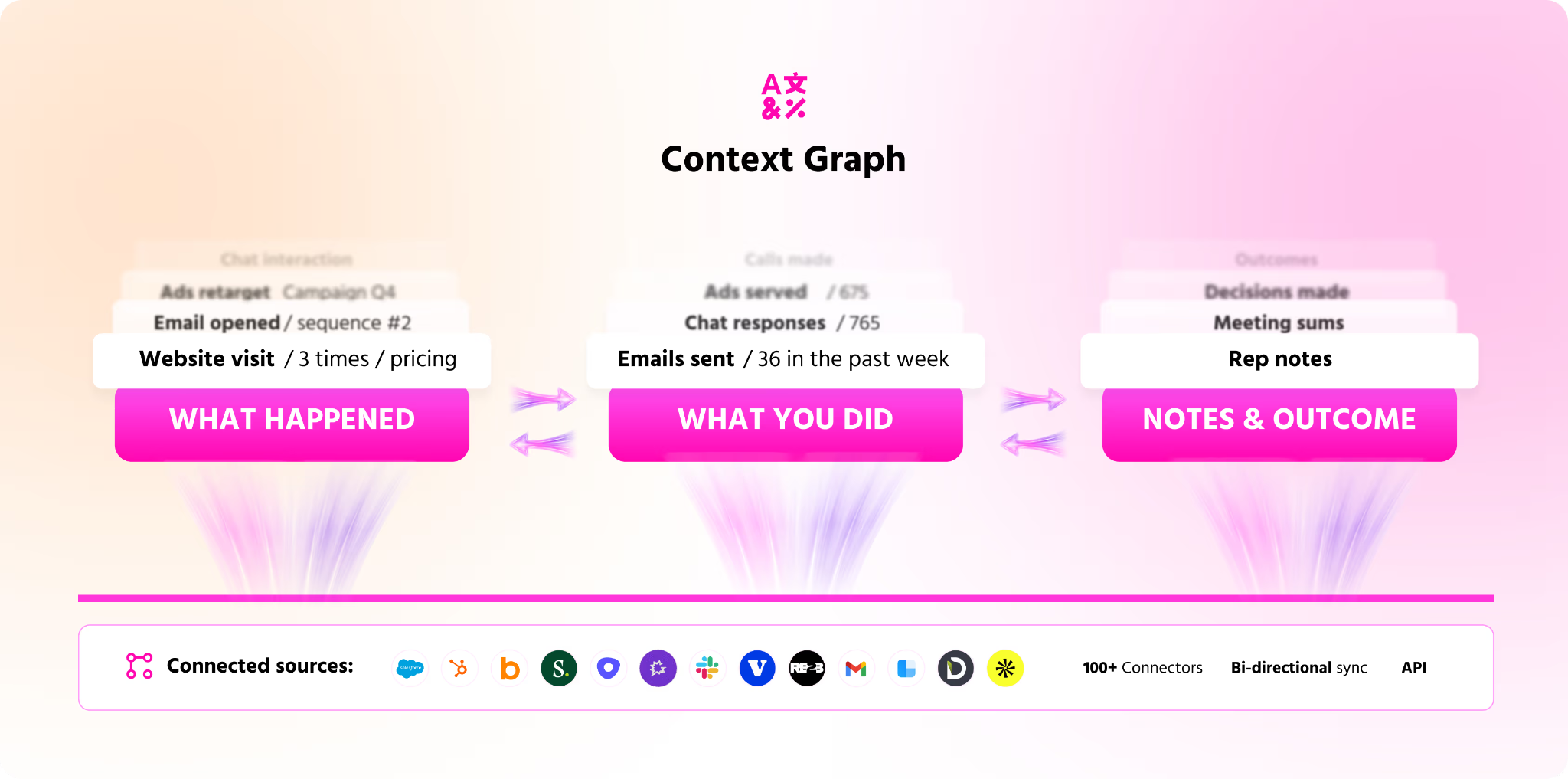
- The Context Graph stitches the two together and sharpens with every interaction.
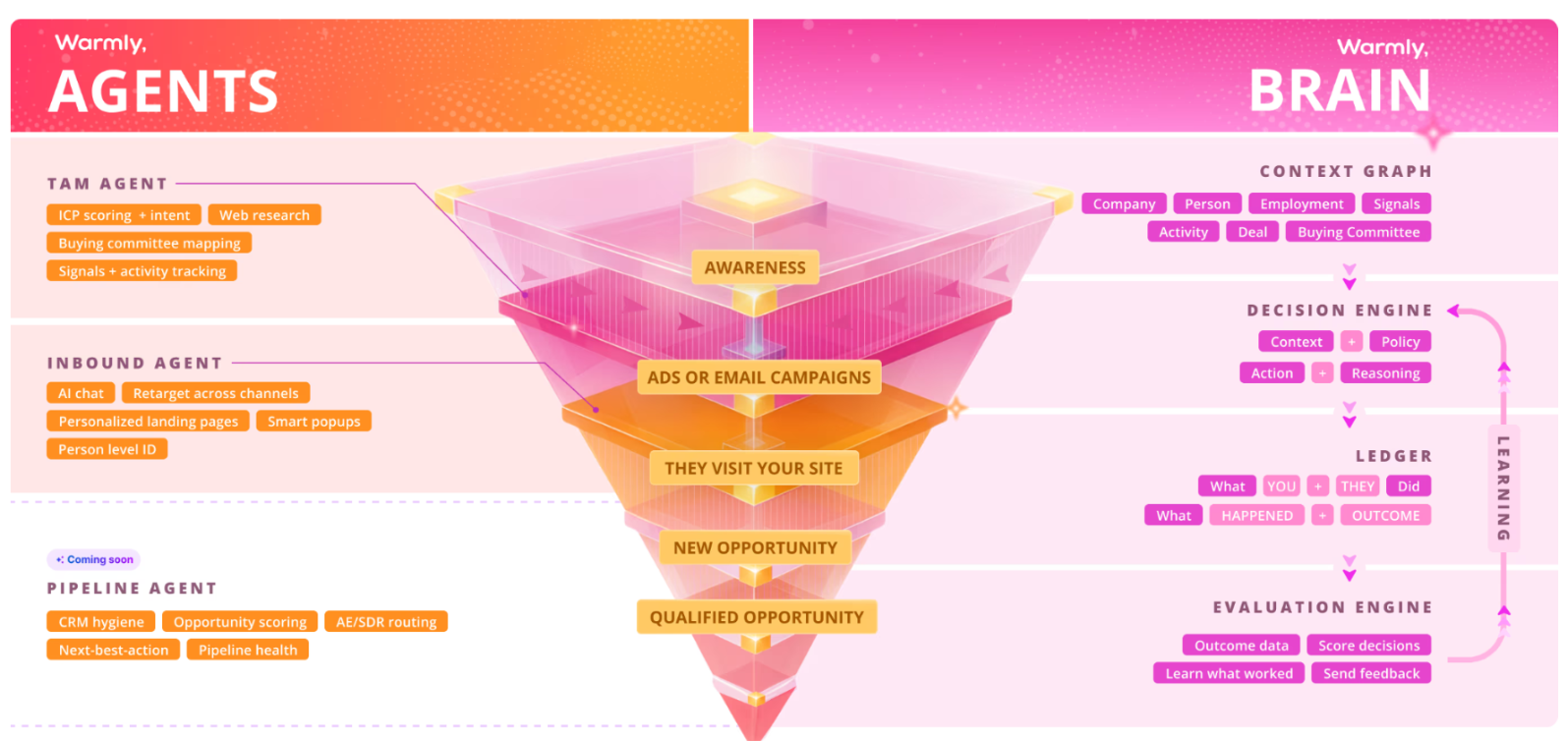
Full disclosure: Warmly is our product, but the aim isn't to oversell it. It's to be straight about where Warmly fits a team leaving Swan.
Swan is a prompt-to-pipeline engine, where you describe a GTM workflow and it spins up agents that research, enrich, qualify, and reach out across your stack.
Its Gatto agent handles website visitors by plugging into providers like RB2B and Vector.
Warmly owns the identification and the engagement layer itself, then runs both motions off one data model.
If you're not sure about Swan, the differences below are the ones that count. 👇
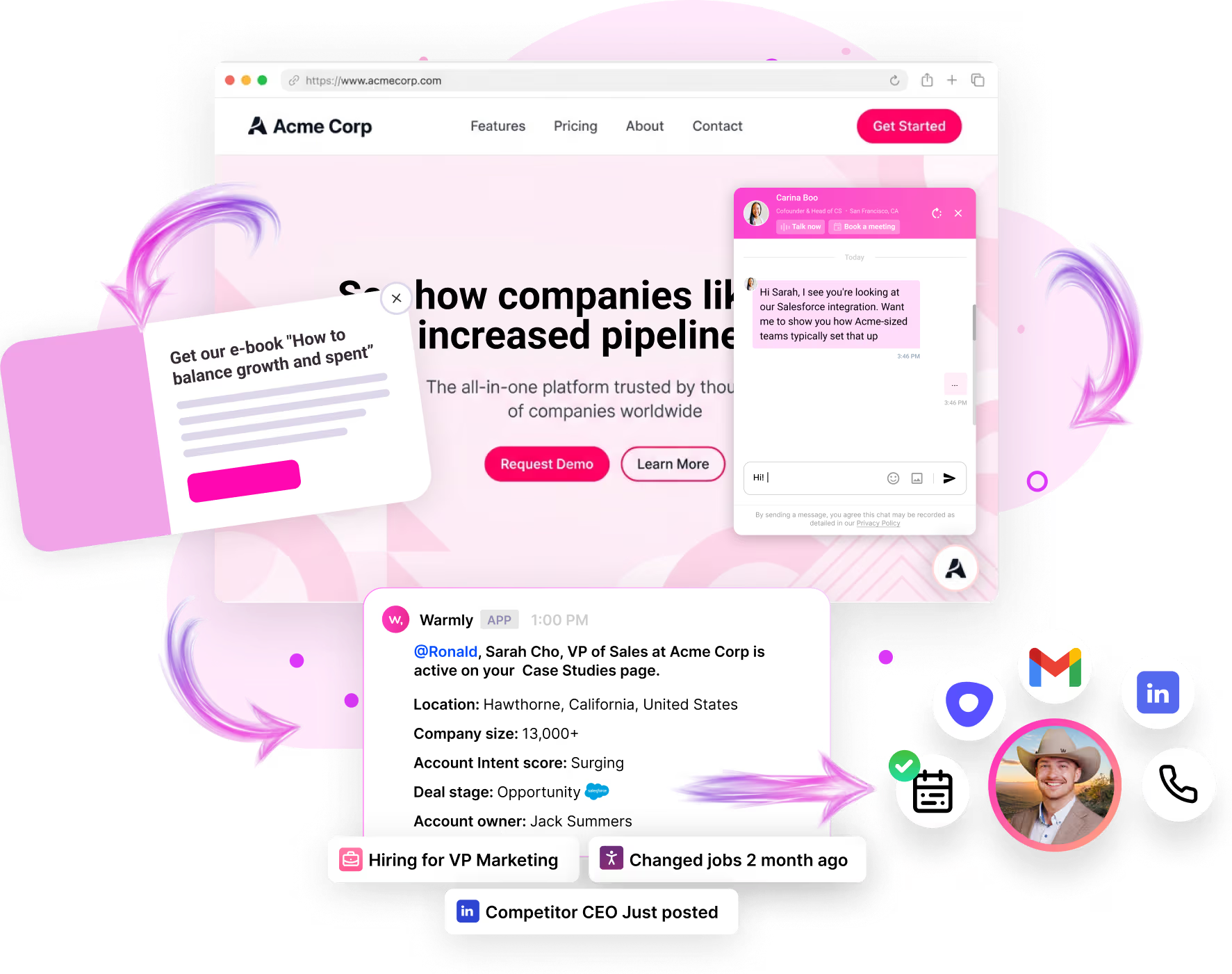
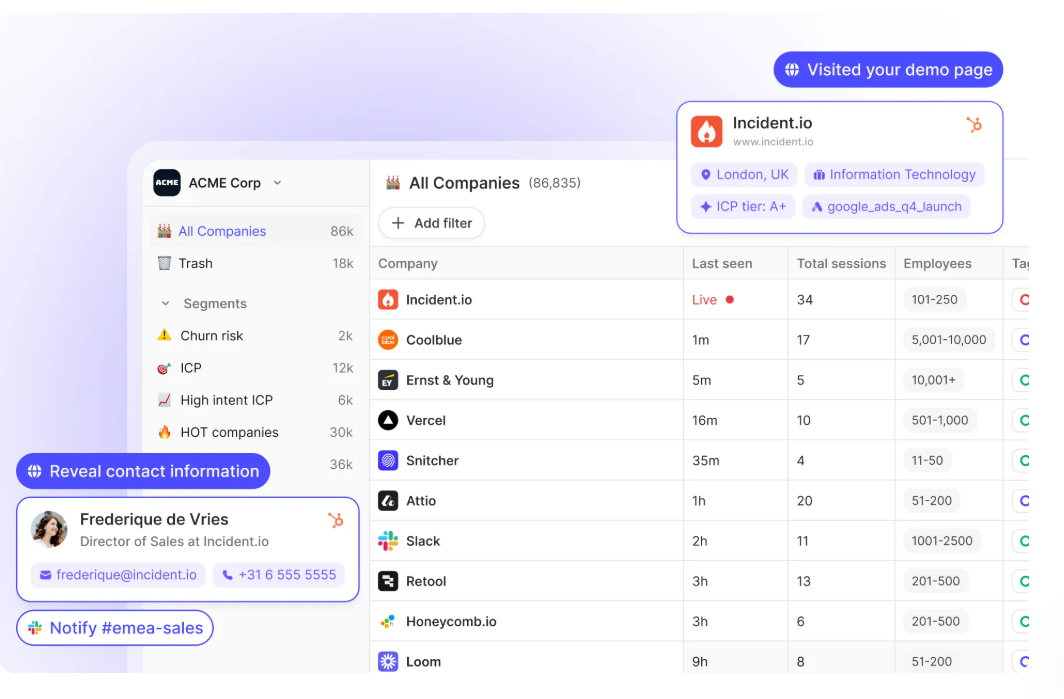
Warmly names the person, not just the company
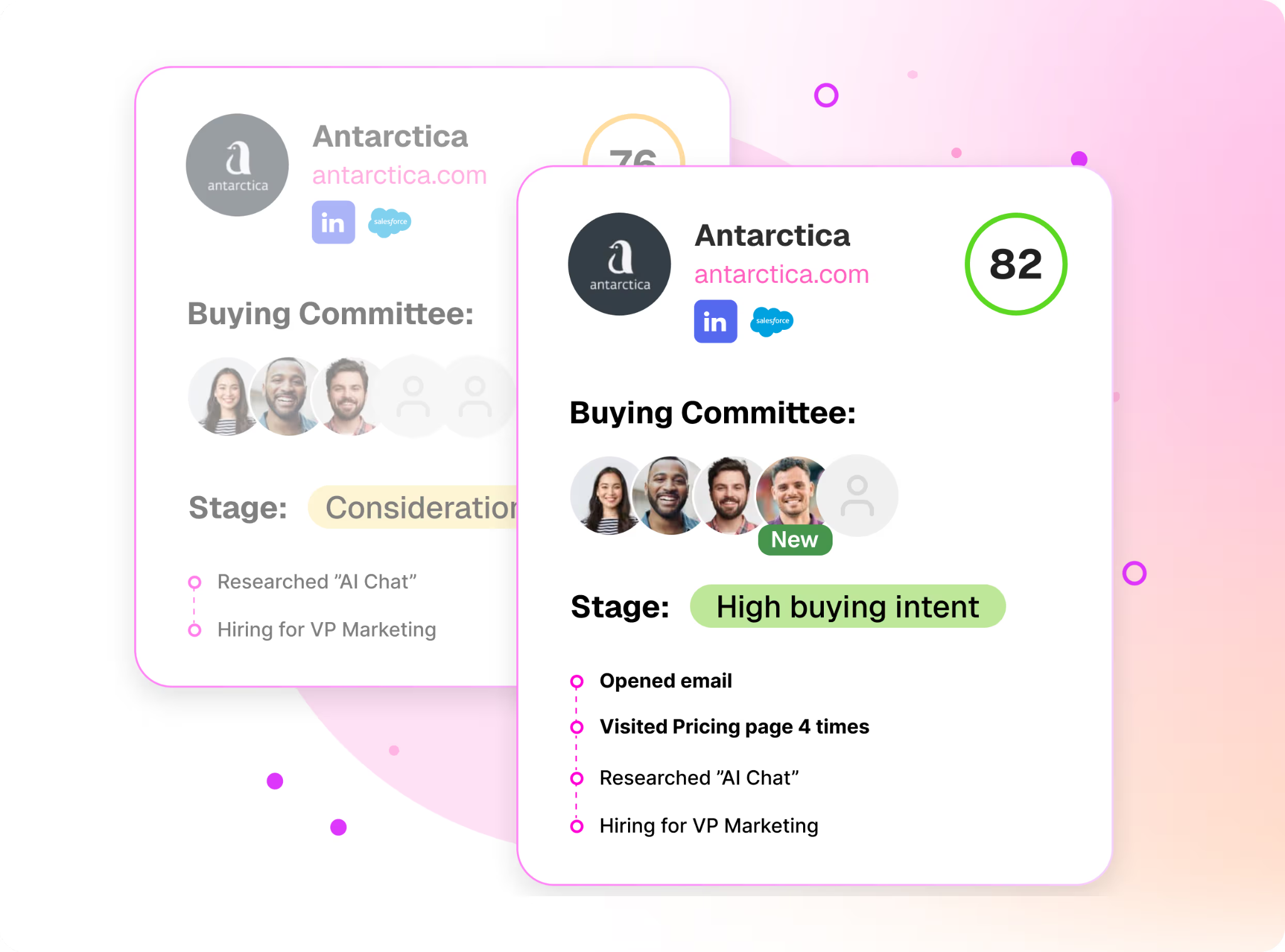
Warmly identifies anonymous visitors natively, down to the person, with their work email, title, seniority, and LinkedIn pulled onto one record.
You drop in the pixel, and matched visitors start showing up without anything else to configure.
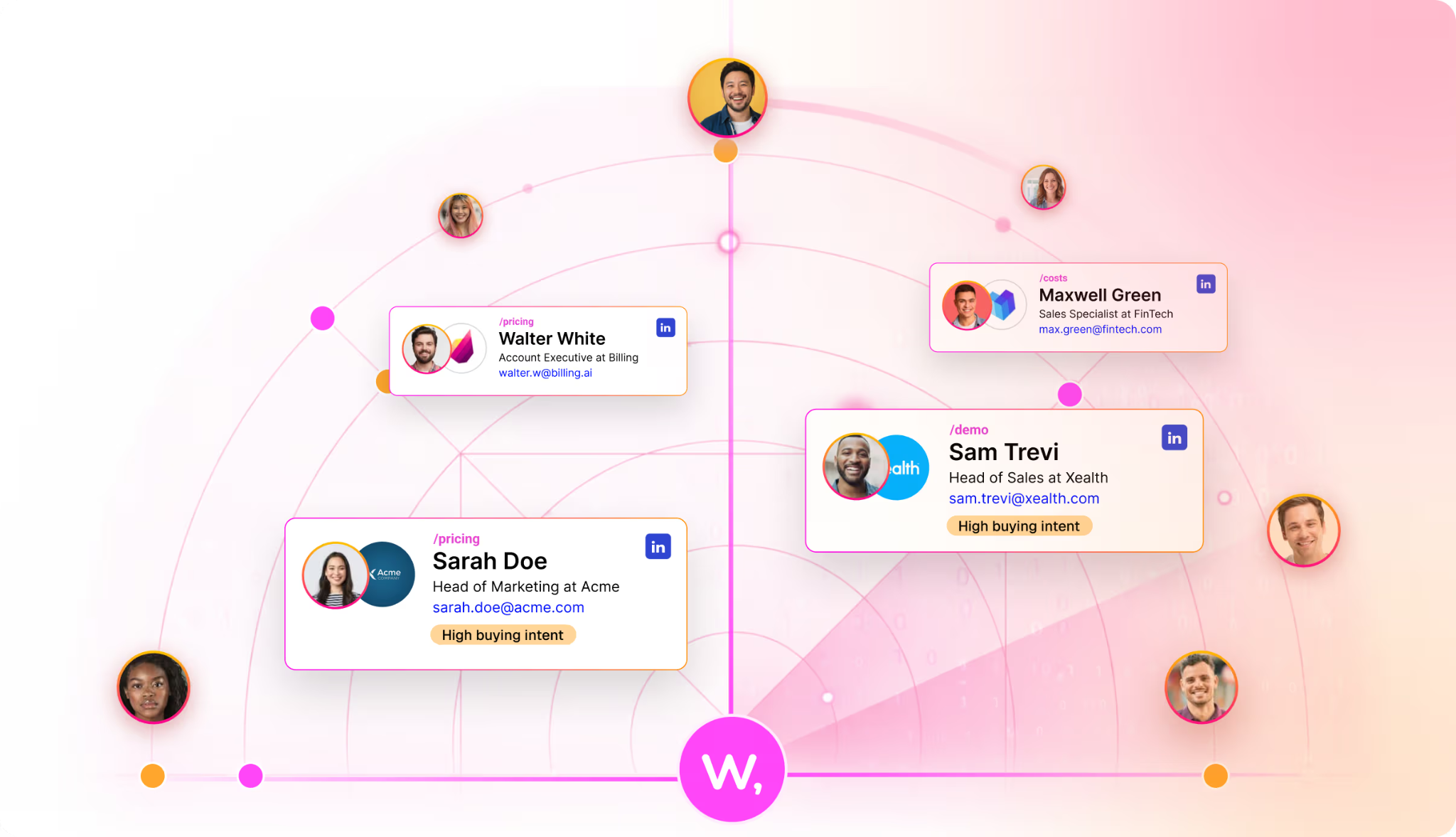
That comes to around 65% of companies and roughly 15% of individuals on regular B2B traffic, with the real numbers shifting by traffic source and where the visitor is based.
The difference shows up in your reps' day: they follow up with Priya in RevOps, who was on your pricing page for four minutes, not "someone at a mid-size logistics firm dropped by" that other company-level visitor ID tools give you.
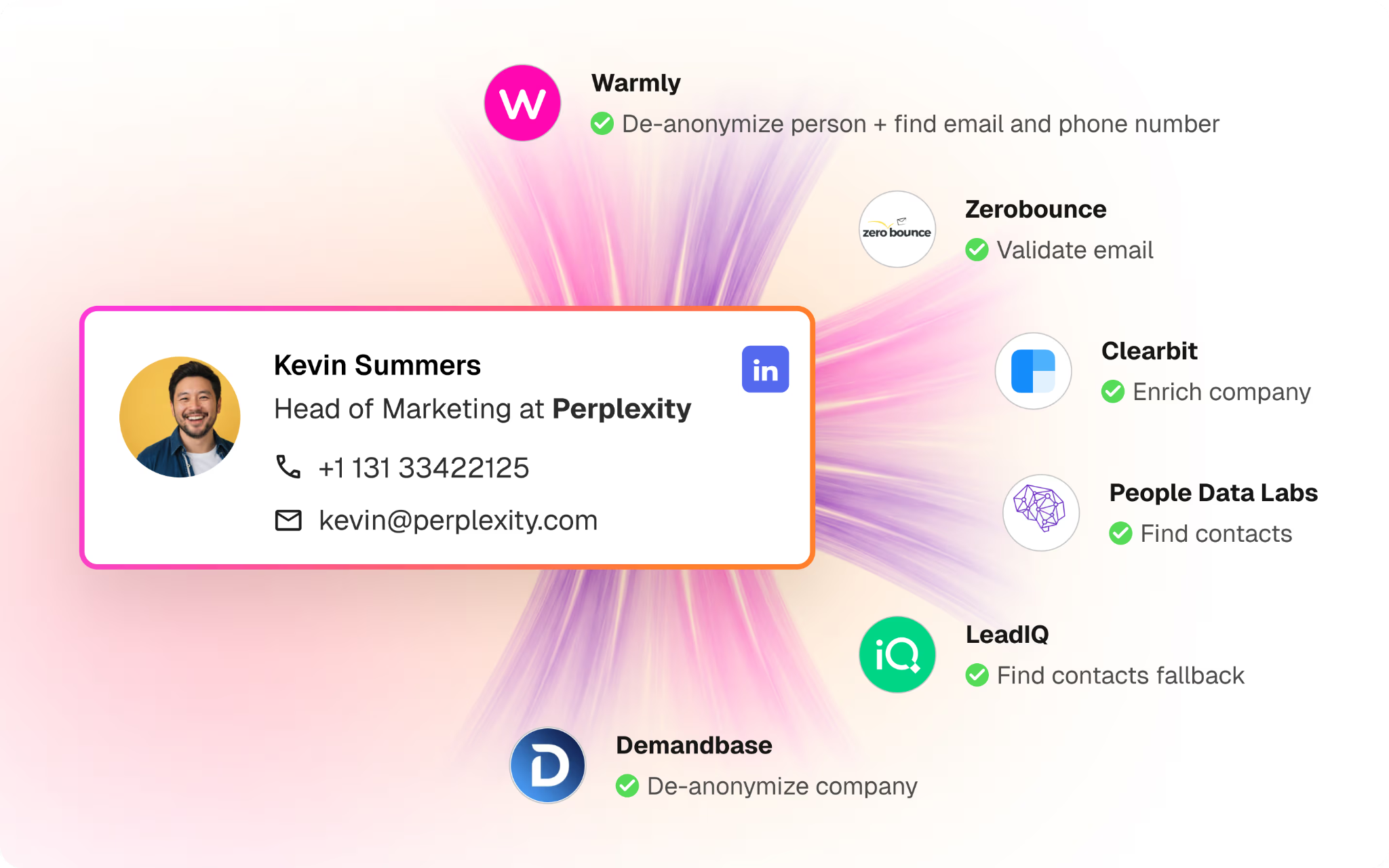
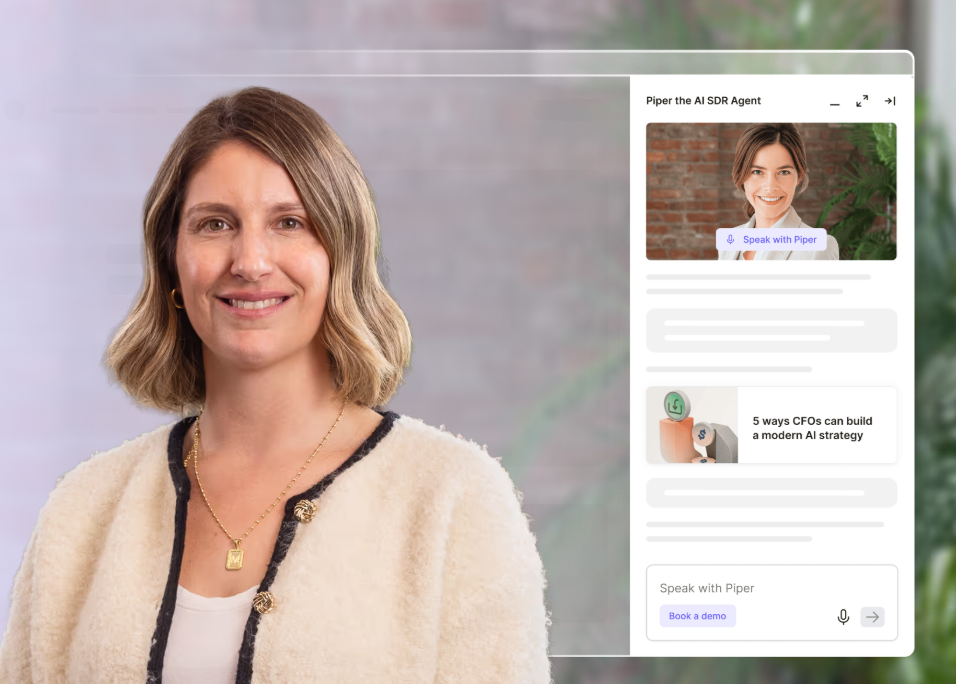
The Inbound Agent engages the prospects after identification
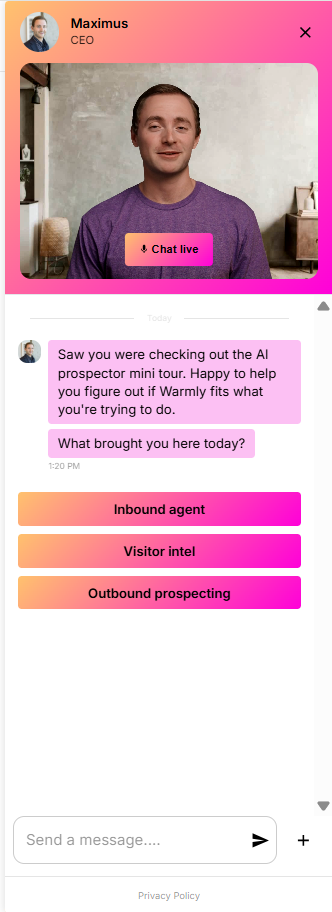
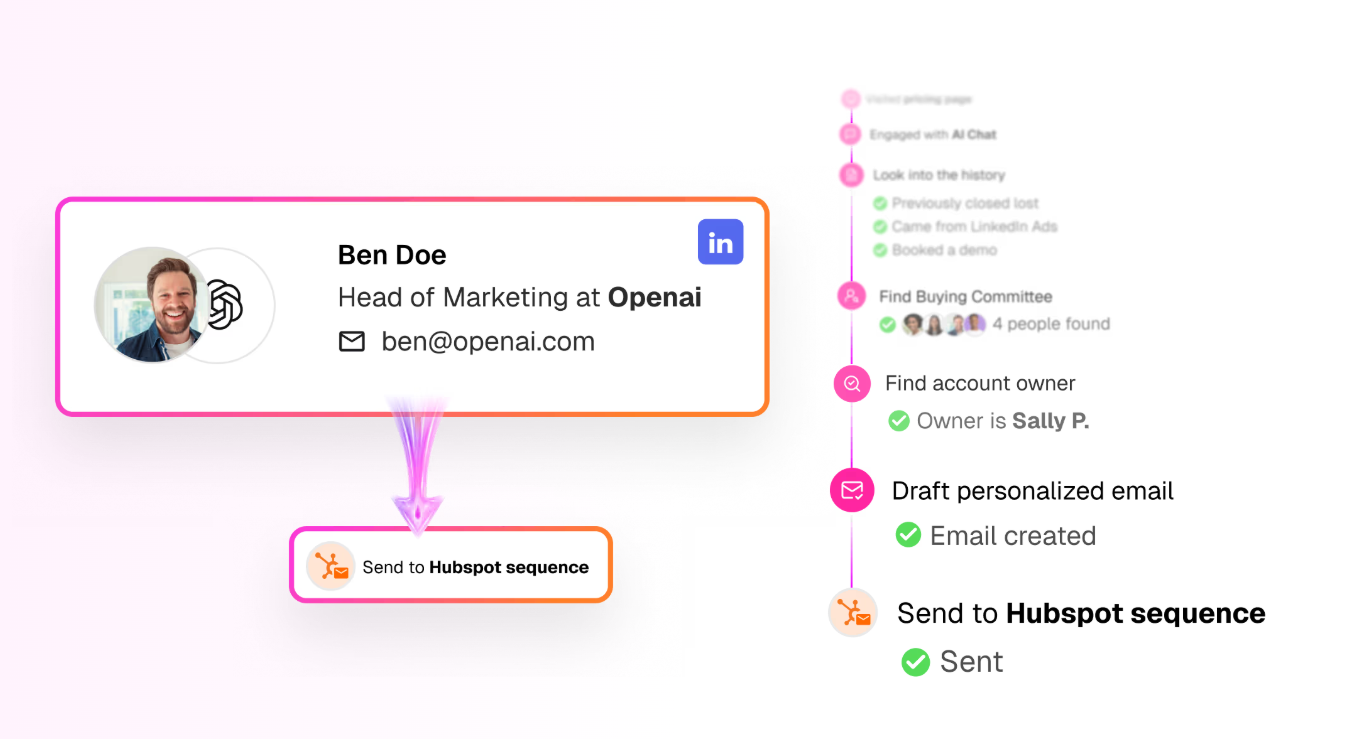
The Inbound Agent handles everything that happens on the page after the visitor is identified: it engages identified visitors with AI chat, qualifies them, and books meetings, all while they're still on the site.
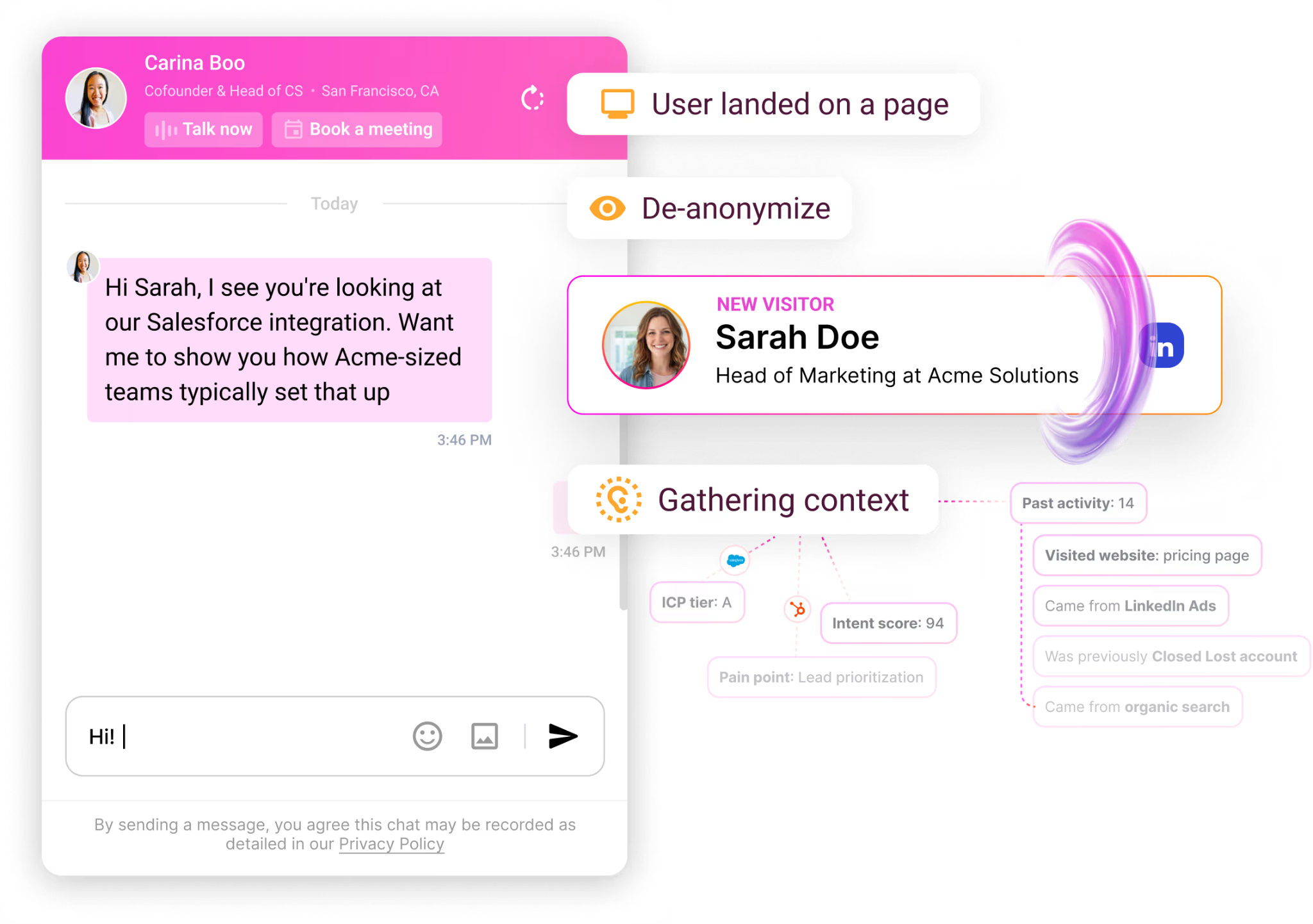
As it already knows who's on your website and what page they’re looking at the moment, the first line draws on their CRM and intent history and opens on something that fits (not a generic greeting).
When a rep needs to take over, the chat hands off with the full thread attached, so the visitor never repeats what the bot already heard.
A good-fit visitor can book straight onto the right calendar from the chat, with no form and no SDR gatekeeping the slot.
Our platform also offers an AI 24/7 Video Chat Agent add-on, which is a photorealistic avatar that runs human-like video conversations around the clock to qualify leads and walk them through personalized demos.
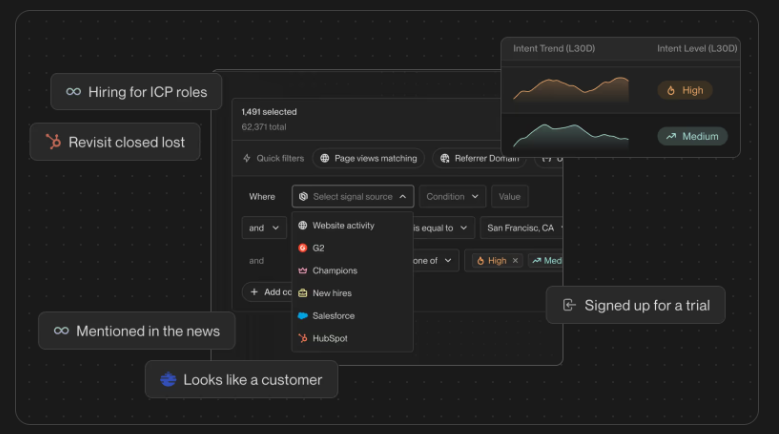
The TAM Agent runs the off-site motion after the prospect leaves
The TAM Agent runs the off-site outbound motion by building target audiences, scoring accounts, mapping the buying committee, enriching contacts, and sequencing across email and LinkedIn.
Our agent picks up where the on-site work ends once a visitor has left the page.
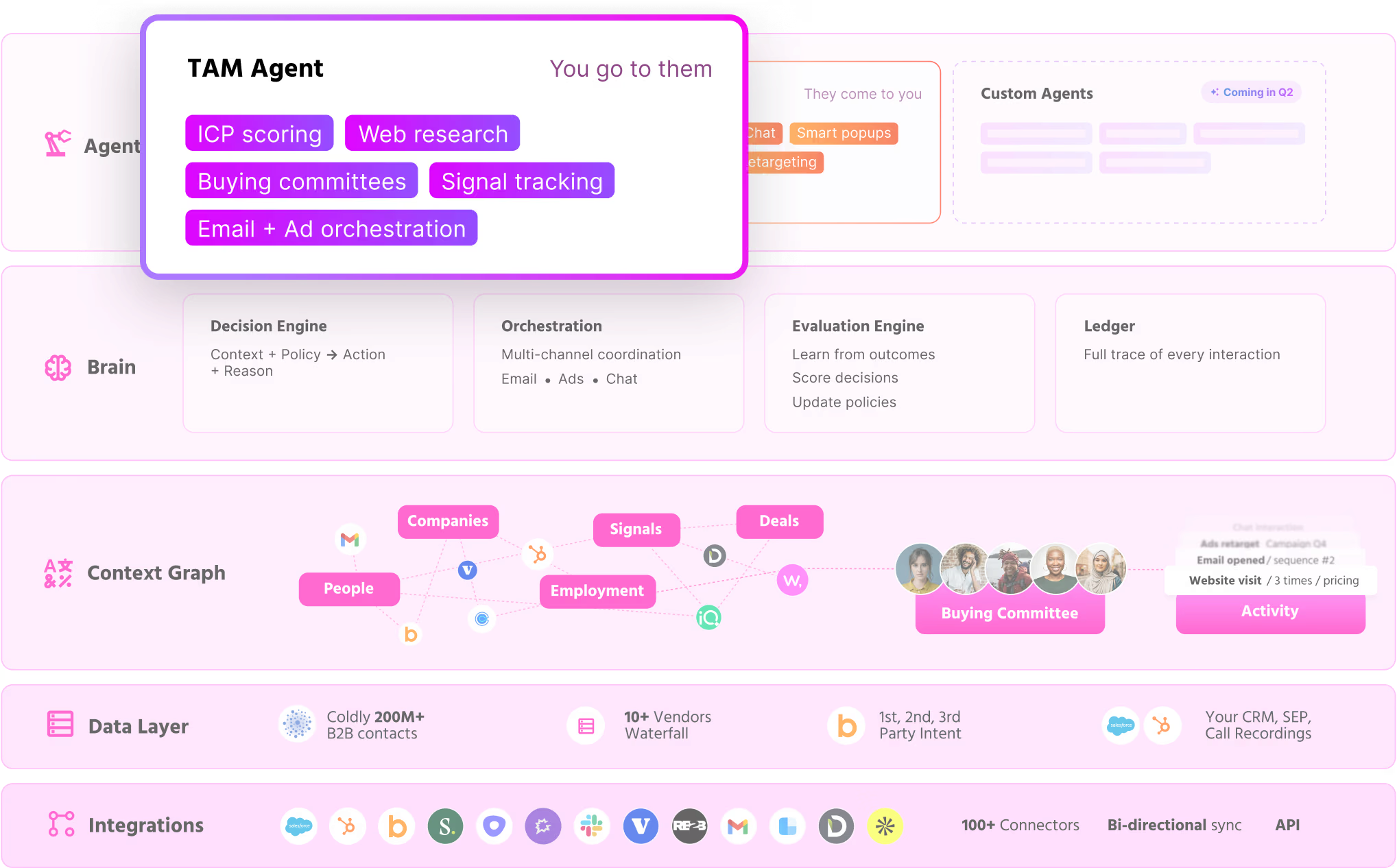
Four pieces carry most of the weight:
- AI ICP Tiering: a model trained on your closed-won deals sorts every account into Tier 1, 2, 3, or Not ICP and shows its reasoning.
- Buying committee mapping: it reads past job titles to assemble the Champion, Decision-maker, Influencer, and Approver from org charts, job descriptions, and LinkedIn.
- Outbound orchestration: route through reps, hand it to an autonomous AI SDR, or blend both, with guardrails that keep it off open deals and anyone mid-chat.
- ML intent scoring: first, second, and third-party signals feed one transparent score that your team can see and adjust.
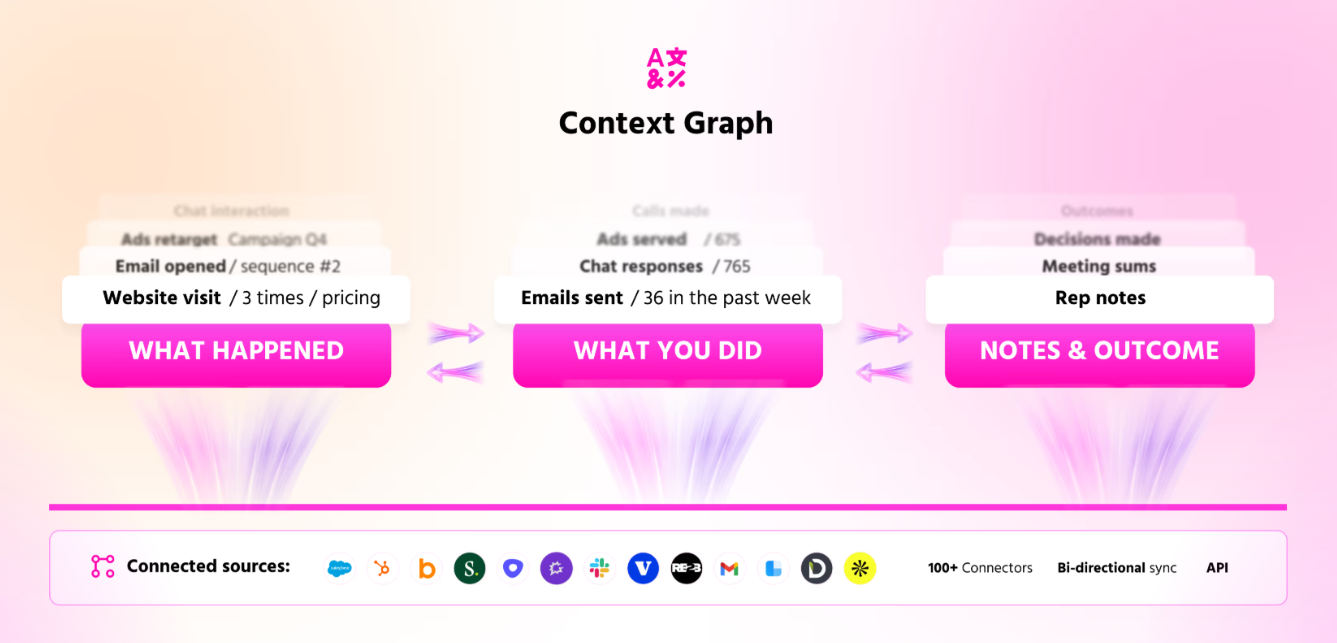
The Context Graph ties both agents together in a shared memory layer
The Context Graph is the shared memory that the inbound and TAM agents read from and write to.
It stores every account's full history in one structure, so the Inbound Agent and the TAM Agent are always working from the same version of the truth.
That history covers four things:
- The buyer's activity.
- Your team's actions.
- The reasoning behind each one.
- The result.
A chat can reference an ad the visitor clicked last quarter and the case study they opened this morning, because both already live in the same place.
How is Warmly different from Swan AI?
The main difference between Warmly and Swan AI is what you get out of the box when you sign up for the GTM platforms.
Swan offers an agent builder where you configure workflows, while Warmly ships two pre-built agents, a native identification layer, and a Context Graph that connects them, ready on day one.
With Swan, your GTM team describes a workflow in everyday language, and it assembles the steps, picking tools and pulling identification from connected providers like RB2B and Vector.
Nothing is pre-set by the looks of it, so the team defines every play, which is what teams that want full control are paying for.
Warmly does the defining for you.
Our Inbound Agent converts on-site visitors, the TAM Agent runs outbound, and both pull person-level identification and intent from the same Context Graph, with no workflow-building required to start.
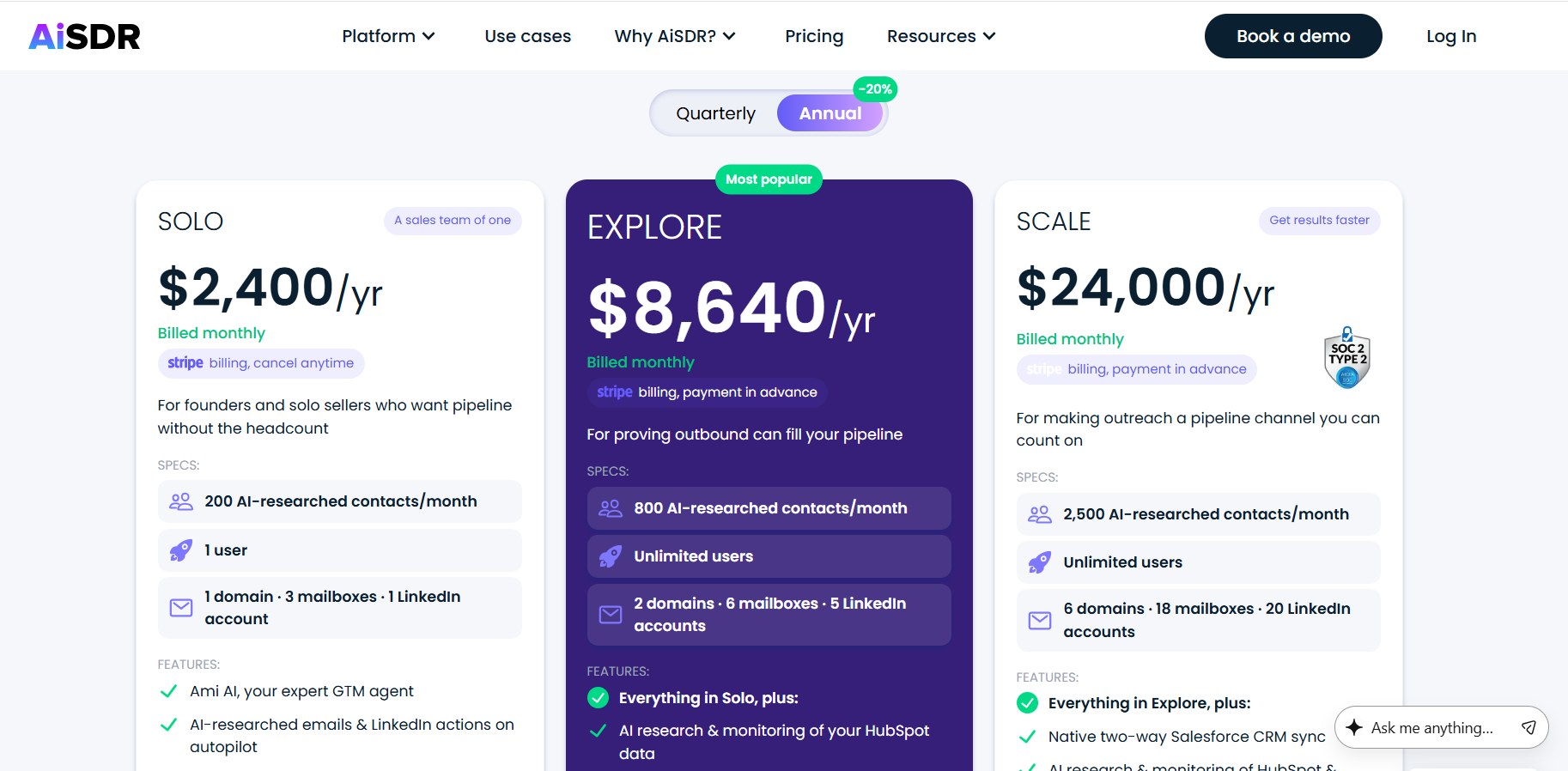
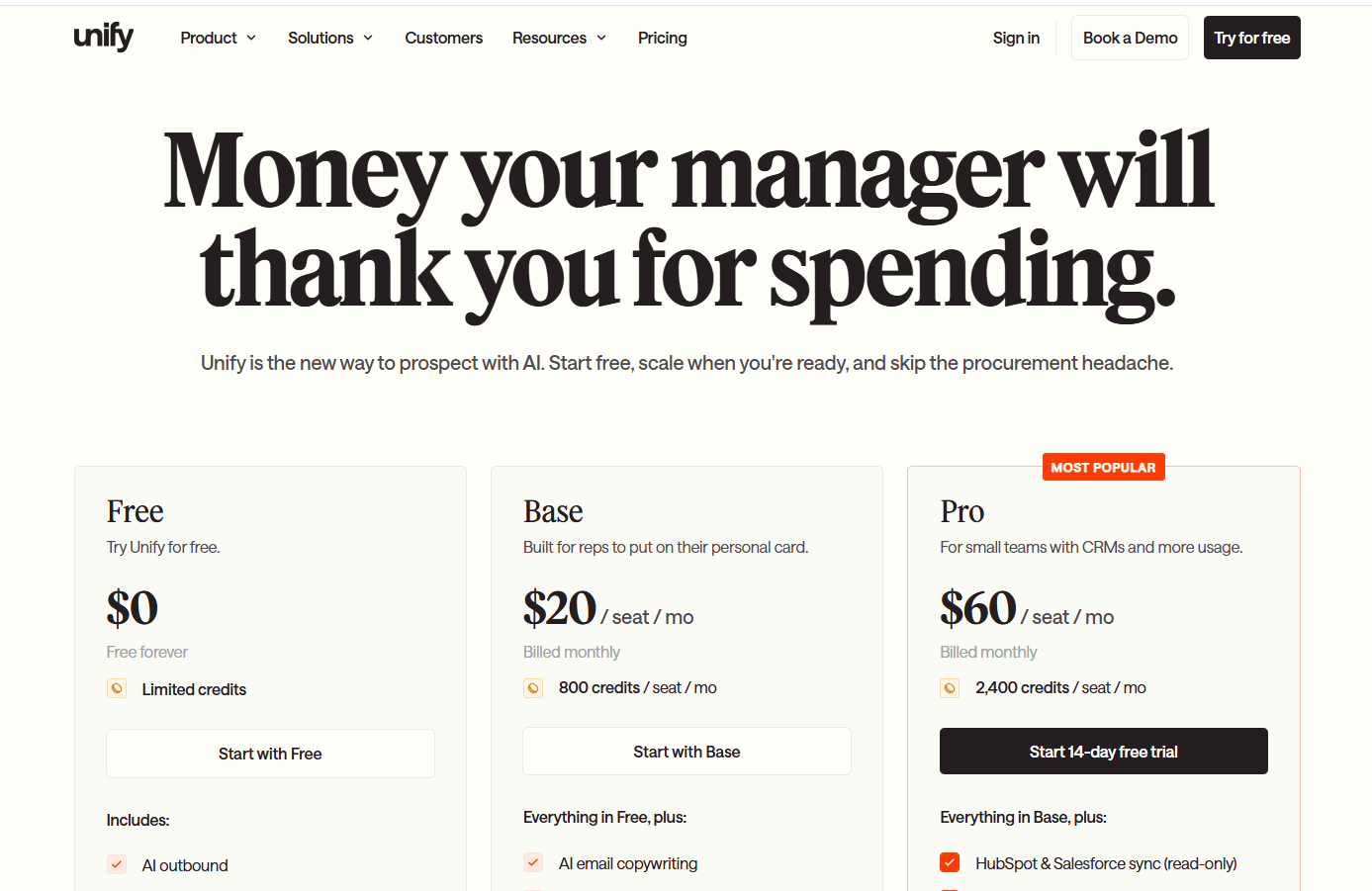
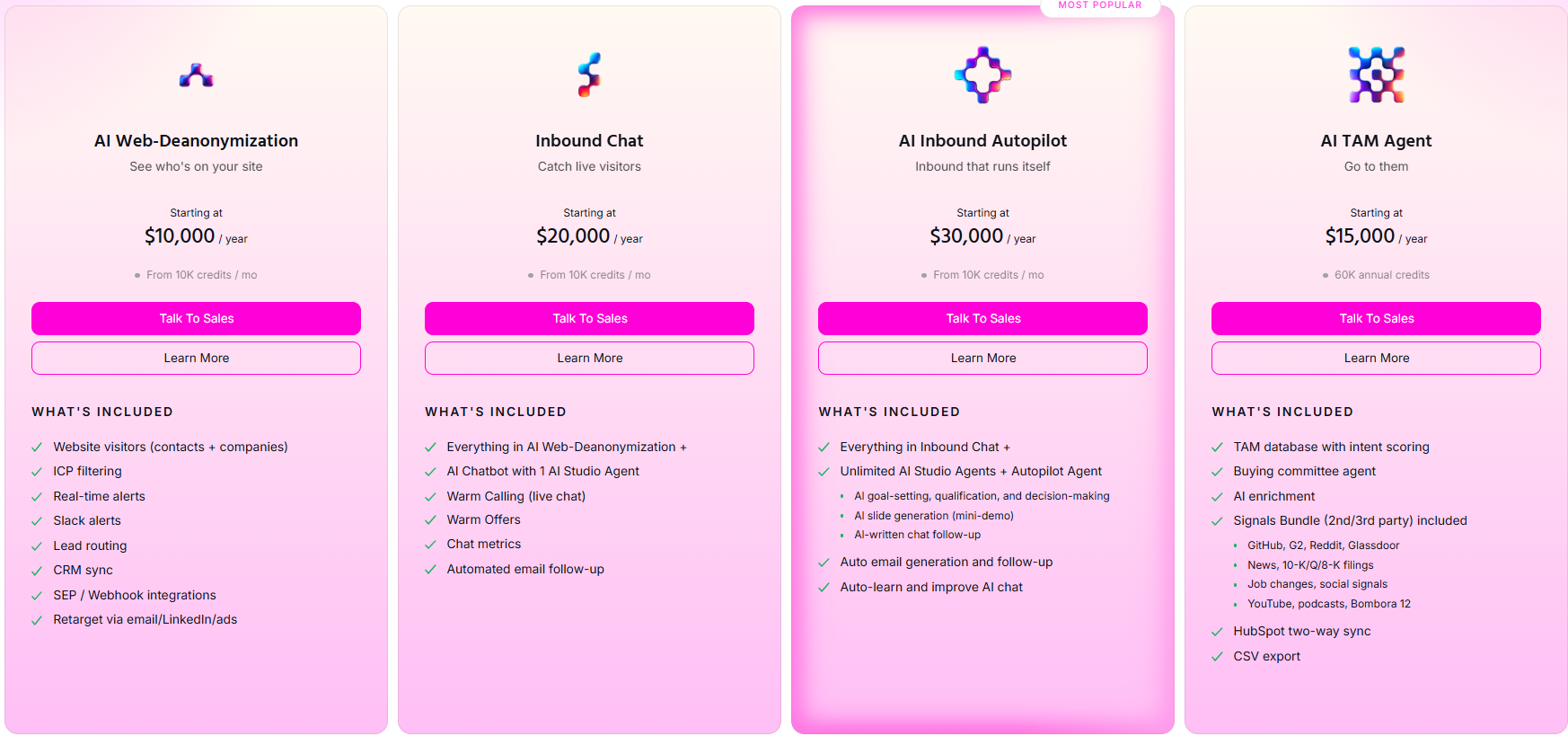
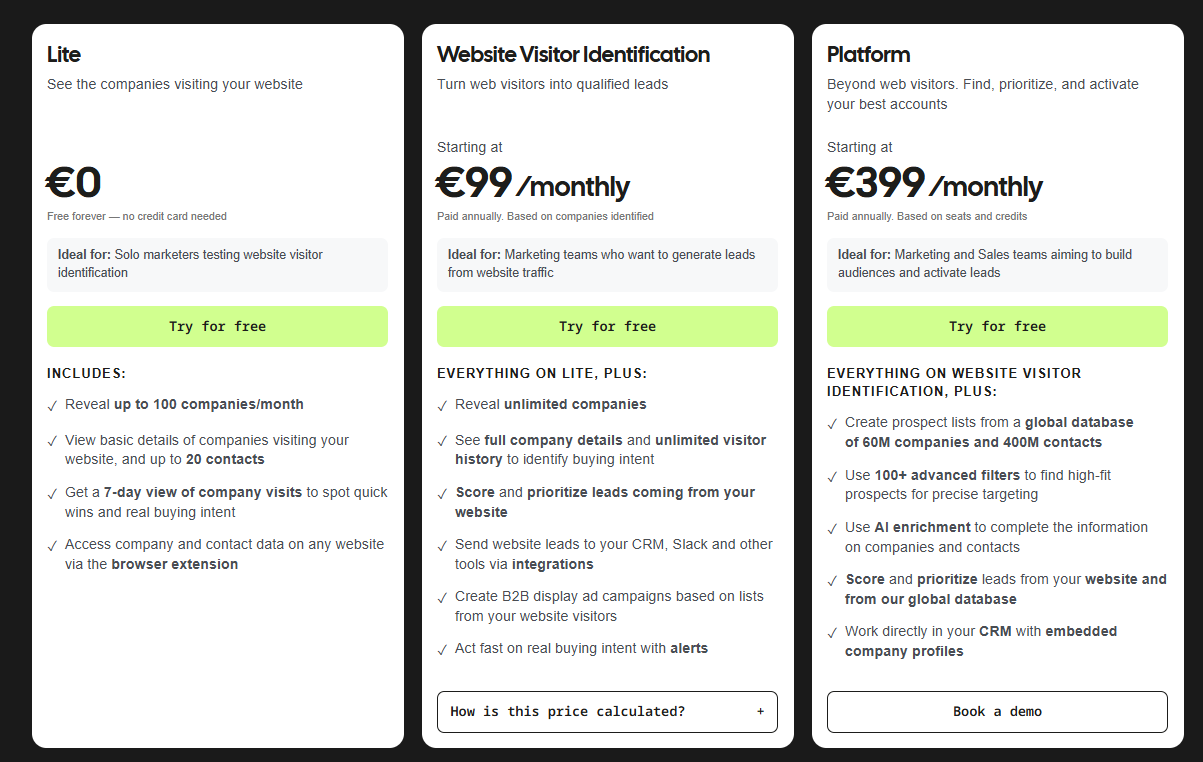
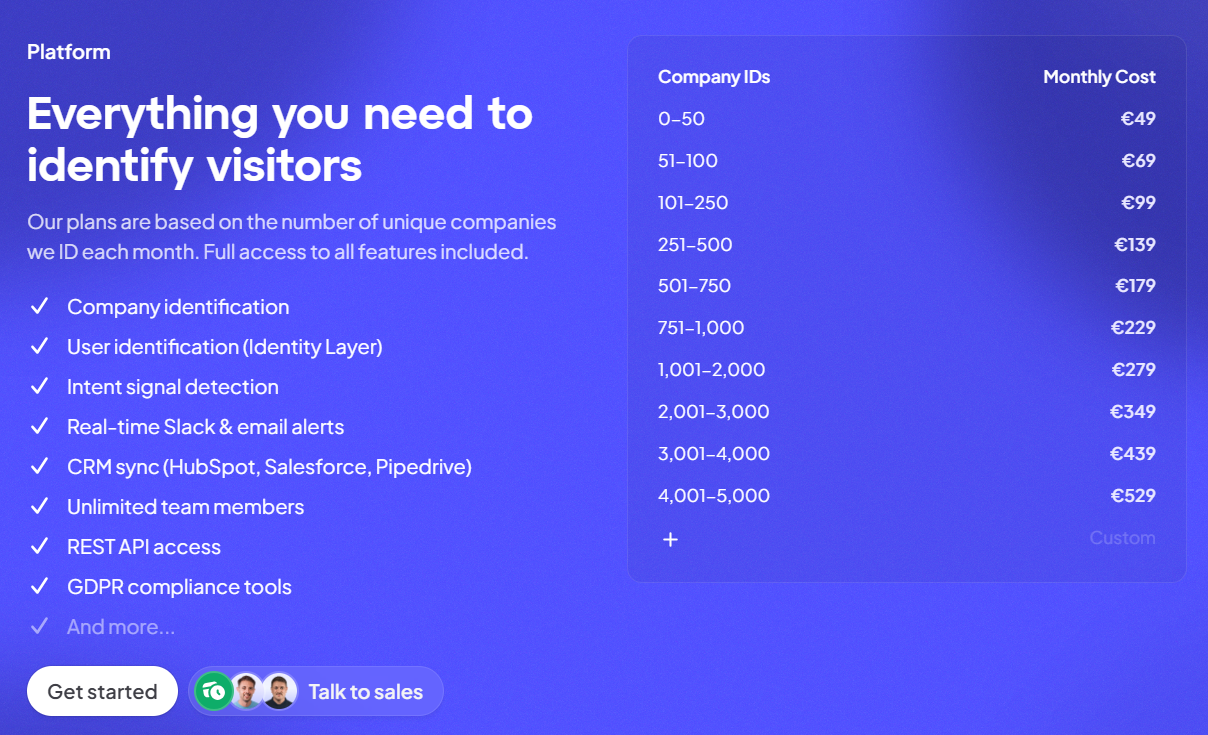
Warmly’s pricing
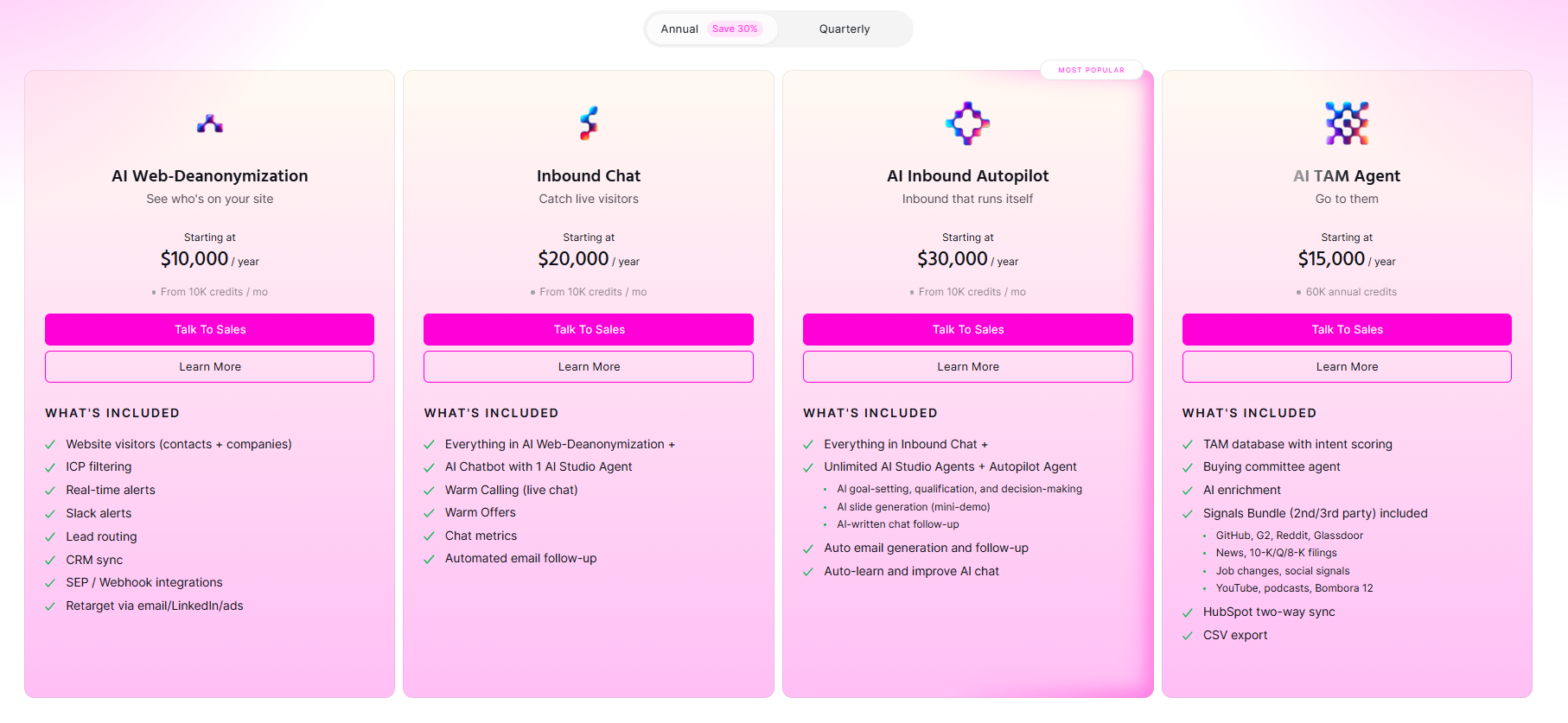
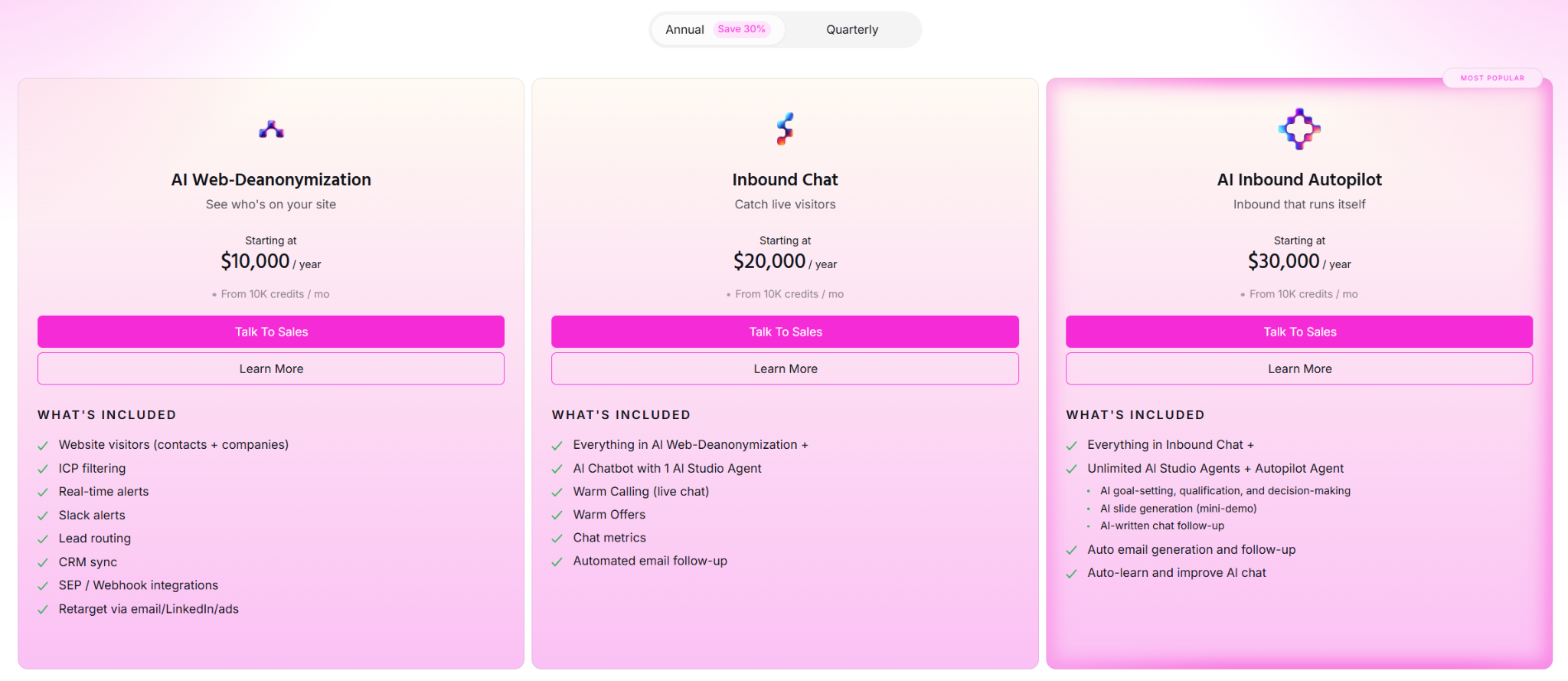
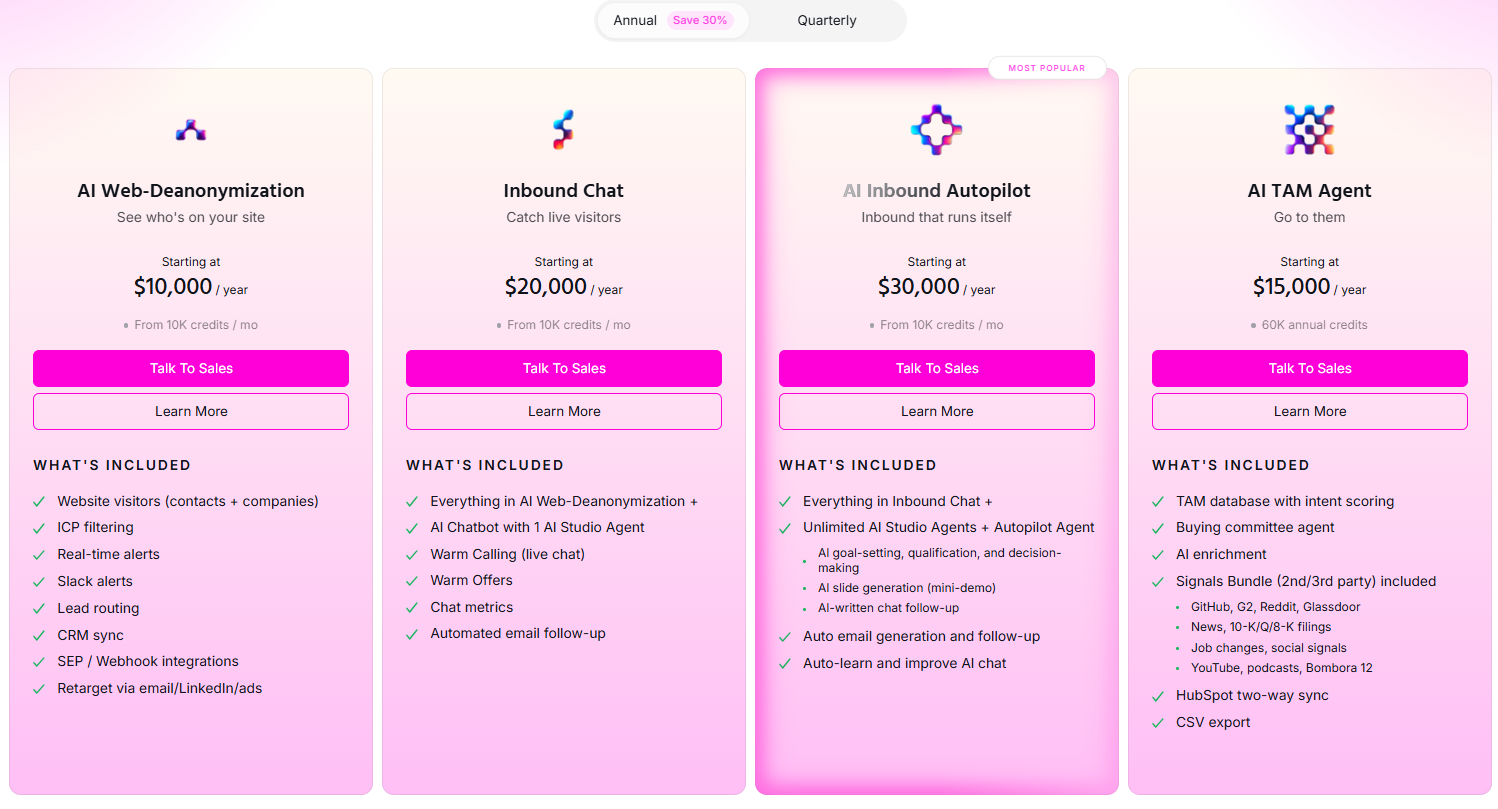
Warmly runs three paid plans on top of a free tier, and they stack as you add more of the funnel.
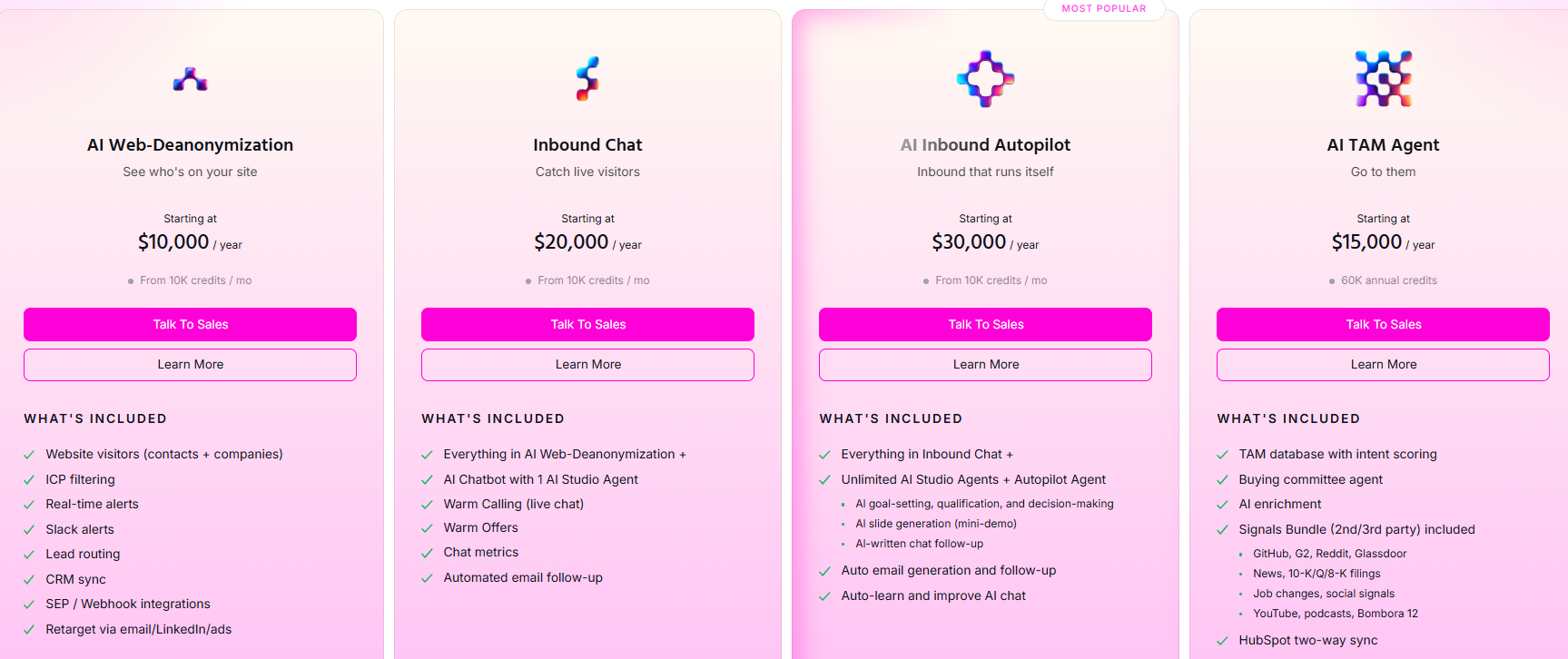
- Free: 500 de-anonymized visitors a month, real-time Slack alerts, and CSV export.
- AI Web-Deanonymization: $10,000/year, 10K credits a month, contact and company-level identification, ICP filtering, real-time Slack alerts, lead routing, CRM sync, and retargeting across email, LinkedIn, and ads. Chat doesn't live on this tier; it starts at Inbound Chat.
- Inbound Chat: $20,000/year, which layers on the conversation: an AI Chatbot (one AI Studio Agent), Warm Calling for the live chat handoff, Warm Offers, chat metrics, and automated email follow-up.
- AI Inbound Autopilot: $30,000/year, which extends Inbound Chat with unlimited AI Studio Agents, the Autopilot Agent, AI goal-setting and qualification, AI-generated mini-demo slides, AI-written follow-up, and auto-learning that sharpens chat performance over time.
Try Warmly for free
By now, you can probably tell whether the build-it-yourself route or the ready-built route suits your team.
Here’s what Warmly puts in your GTM team’s hands:
- Person-level visitor identification.
- An Inbound Agent that chats, qualifies, books, and circles back to the ones who slipped away.
- A TAM Agent running ICP scoring, committee mapping, and outbound.
- A Context Graph that lets both sides learn from one shared history.
You can start on the free plan with 500 identified visitors a month, or skip ahead and book a demo if you already want both agents live.
⚠️ Disclaimer: This article was last updated on the 2nd of July, 2026. If anything here has been misread, contact us, and we'll fact-check it.
![10 Best Artisan AI Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a461258d8b098ce533f8b5f_artisan%20ai%20alternatives.png)



![10 Best Swan AI Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a418038ba577e5a48992a46_swan%20ai%20alternatives.png)


![Snitcher Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a416c8fdb39053fc92efbe9_snitcher%20pricing.png)



![Demandbase Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a353caddcd5ecf848e46ea7_demandbase%20pricing.png)



![10 Best Snitcher Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a2c18de1740cf1b5ffe70f7_snitcher%20alternatives.png)



![Albacross Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a2c16faec9dd450aee359ac_albacross%20pricing.png)

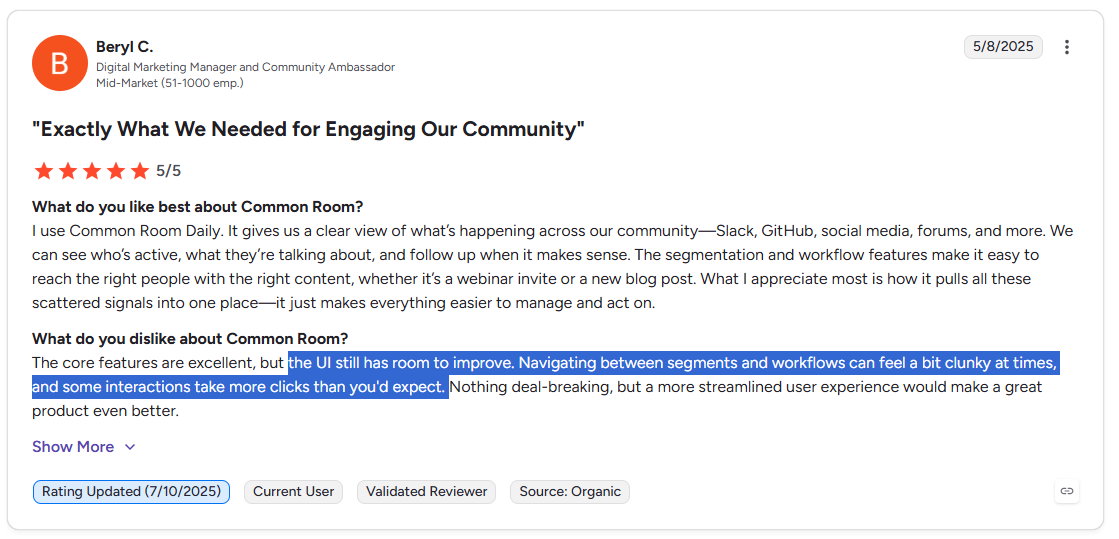
![Common Room Pricing: Is It Worth It In 2026? [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a2299cb2e63bc69223ea63d_common%20room%20pricing.png)

![10 Best Albacross Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a2297519e7f1d1c19cfda93_albacross%20alternatives.png)
![10 Best Common Room Alternatives & Competitors [2026]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a1a91bba75f99c148911b7f_common%20room%20alternatives.png)
![10 Best Agentic Inbound Agents In 2026 [Reviewed]](https://cdn.prod.website-files.com/6506fc5785bd592c468835e0/6a185fc1a37dcea65149d3aa_agentic%20inbound%20agents.png)